NeurIPS 2019 Outstanding Paper Awards
NeurIPS 2019 is underway in Vancouver, and the committee has just recently announced this year's Outstanding Paper Awards. Find out what the selections were, along with some additional info on NeurIPS papers, here.

NeurIPS 2019 is underway in Vancouver, and the committee has just recently announced this year's Outstanding Paper Awards.
Before looking at those selected as outstanding, you might want to first have a look at all of the conference's selected papers for 2019.
The Outstanding Paper Committee selection criteria, directly from NeurIPS:
We asked the Outstanding Paper Committee to choose from the set of papers that had been selected for oral presentation. Before looking at the papers, they agreed on the following criteria to guide their selection.
- Potential to endure — Focused on the main game, not sidelines. Likely that people will still care about this in decades to come.
- Insight — Provides new (and hopefully deep) understanding; does not just show a few percentage points of improvement.
- Creativity / Unexpectedness / Wow — Looks at the problem in a creatively new way; a result that really surprises the reader.
- Revolutionary — Will radically change the way people will think in the future.
- Rigour — Unimpeachable rigour and care.
- Elegance — Beautiful, clean, slick, polished.
- Realism — Does not over-claim the significance.
- Scientific — Actually falsifiable.
- Reproducible — The results are actually reproducible; code available, and it works on a wide range of machines; data available; full detailed proofs.
They also agreed on some criteria that they would like to avoid:
- Inefficient — Steering away from work that only stand out due to resource profligacy (achieved a higher league table ranking largely by virtue of squandering huge resources)
- Trendiness — An approach taken because an idea is fashionable but could be accessed in a different more effective way using other approaches.
- Over Complicated — The paper engaged in unnecessary complexity.
Finally, they determined it appropriate to introduce an additional Outstanding New Directions Paper Award, to highlight work that distinguished itself in setting a novel avenue for future research.
Selections are presented below, with simplified paper abstracts coming from the NeruIPS Outstanding Paper Awards webpage.
Outstanding Paper Award
Distribution-Independent PAC Learning of Halfspaces with Massart Noise, by Ilias Diakonikolas, Themis Gouleakis, Christos Tzamos
The paper studies the learning of linear threshold functions for binary classification in the presence of unknown, bounded label noise in the training data. It solves a fundamental, and long-standing open problem by deriving an efficient algorithm for learning in this case. This paper makes tremendous progress on a long-standing open problem at the heart of machine learning: efficiently learning half-spaces under Massart noise. To give a simple example highlighted in the paper, even weak learning disjunctions (to error 49%) under 1% Massart noise was open. This paper shows how to efficiently achieve excess risk equal to the Massart noise level plus epsilon (and runs in time poly(1/epsilon), as desired). The algorithmic approach is sophisticated and the results are technically challenging to establish. The final goal is to be able to efficiently get excess risk equal to epsilon (in time poly(1/epsilon)).
Outstanding New Directions Paper Award
Uniform convergence may be unable to explain generalization in deep learning, by Vaishnavh Nagarajan, J. Zico Kolter
The paper presents what are essentially negative results showing that many existing (norm based) bounds on the performance of deep learning algorithms don’t do what they claim. They go on to argue that they can’t do what they claim when they continue to lean on the machinery of two-sided uniform convergence. While the paper does not solve (nor pretend to solve) the question of generalisation in deep neural nets, it is an ``instance of the fingerpost’’ (to use Francis Bacon’s phrase) pointing the community to look in a different place.
Honorable Mention Outstanding Paper Award
Nonparametric Density Estimation & Convergence Rates for GANs under Besov IPM Losses, by Ananya Uppal, Shashank Singh, Barnabas Poczos
The paper shows, in a rigorous theoretical manner, that GANs can outperform linear methods in density estimation (in terms of rates of convergence). Leveraging prior results on wavelet shrinkage, the paper offers new insight into the representational power of GANs. Specifically, the authors derive minimax convergence rates for non-parametric density estimation under a large class of losses (so-called integral probability metrics) within a large function class (Besov spaces). Reviewers felt this paper would have significant impact for researchers working on non-parametric estimation and GANs.
Fast and Accurate Least-Mean-Squares Solvers, by Alaa Maalouf, Ibrahim Jubran, Dan Feldman
Least Mean-Square solvers operate at the core of many ML algorithms, from linear and Lasso regression to singular value decomposition and Elastic net. The paper shows how to reduce their computational complexity by one or two orders of magnitude, with no precision loss and improved numerical stability. The approach relies on the Caratheodory theorem, establishing that a coreset (set of d2 + 1 points in dimension d) is sufficient to characterize all n points in a convex hull. The novelty lies in the divide-and-conquer algorithm proposed to extract a coreset with affordable complexity (O(nd + d5 log n), granted that d << n). Reviewers emphasize the importance of the approach, for practitioners as the method can be easily implemented to improve existing algorithms, and for extension to other algorithms as the recursive partitioning principle of the approach lends itself to generalization.
Honorable Mention Outstanding New Directions Paper Award
Putting An End to End-to-End: Gradient-Isolated Learning of Representations, by Sindy Löwe, Peter O'Connor, Bastiaan Veeling
The paper revisits the layer-wise building of deep networks, using self-supervised criteria inspired from van Oord et al. (2018), specifically the mutual information between the representation of the current input, and input close in space or time. As noted by reviewers, such self-organization in perceptual networks might give food for thought at the cross-road of algorithmic perspectives (sidestepping end-to-end optimization, its huge memory footprint and computational issues), and cognitive perspectives (exploiting the notion of so-called slow features and going toward more “biologically plausible” learning processes).
Scene Representation Networks: Continuous 3D-Structure-Aware Neural Scene Representations, by Vincent Sitzmann, Michael Zollhoefer, Gordon Wetzstein
The paper presents an elegant synthesis of two broad approaches in CV: the multiple view geometric, and the deep representations. Specifically, the paper makes three contributions: 1) A per-voxel neural renderer, which enables resolution-free rendering of a scene in a 3D aware manner; 2) A differentiable ray-marching algorithm, which solves the difficult problem of finding surface intersections along rays cast from a camera; and 3) A latent scene representation, which uses auto-encoders and hyper-networks to regress the parameters of the scene representation network.
Test of Time Award
As in previous years we created a committee to select a paper published 10 years ago at NeurIPS and that was deemed to have had a particularly significant and lasting impact on our community.
Dual Averaging Method for Regularized Stochastic Learning and Online Optimization, by Lin Xiao (originally presented at NIPS 2009)
We consider regularized stochastic learning and online optimization problems, where the objective function is the sum of two convex terms: one is the loss function of the learning task, and the other is a simple regularization term such as L1-norm for sparsity. We develop a new online algorithm, the regularized dual averaging method, that can explicitly exploit the regularization structure in an online setting. In particular, at each iteration, the learning variables are adjusted by solving a simple optimization problem that involves the running average of all past subgradients of the loss functions and the whole regularization term, not just its subgradient. This method achieves the optimal convergence rate and often enjoys a low complexity per iteration similar as the standard stochastic gradient method. Computational experiments are presented for the special case of sparse online learning using L1-regularization.
If you're looking to geek out a bit more on NeurIPS paper selection (and really, who isn't?), Diego Charrez has collected some relevant statistics, which he wrote about here. Among other collected stats, he broke down papers by acceptance over the past few years, as well as number of selected papers by author and by institution. For instance, here is a comparison of the submitted and accepted papers for the past six NeurIPS conferences, dating back to 2014.
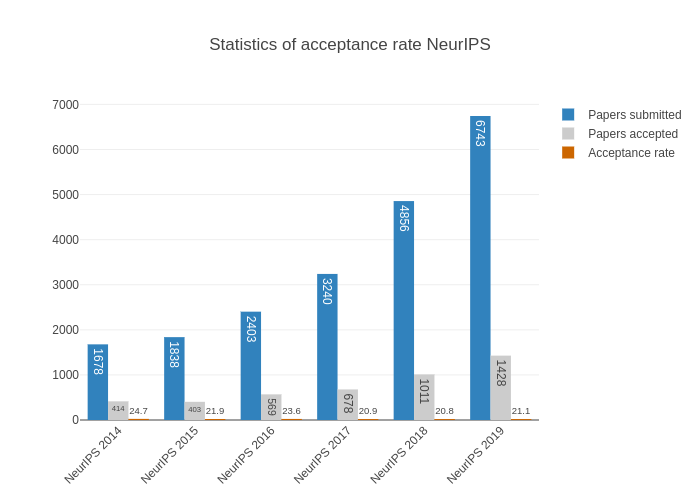
For those interested, head over to the original blog for more information.
Related:
- AI, Analytics, Machine Learning, Data Science, Deep Learning Research Main Developments in 2019 and Key Trends for 2020
- Gender Diversity in AI Research
- 12 NLP Researchers, Practitioners & Innovators You Should Be Following