The Decade of Data Science
With the last decade being so strong for the emerging field of Data Science, this review considers current trends in the industry, popular frameworks, helpful tools, and new tools that can be leveraged more in the future.
By Alex Mitrani, Data Scientist.
It’s been just over seven years since Harvard Business Review published an article proclaiming that Data Scientist is “The Sexiest Job of the 21st Century.” Since then, Bootcamps have popped up around the country and colleges have developed data science undergraduate, masters, and doctorate programs; my own alma mater is planning to build a center specifically for the subject. The cost of these programs varies widely depending on if they are completed online or taught in person, the length of the program, and the schools’ employment statistics and prestige.
What actually is a data scientist? The broadest acceptable definition may be one who looks to extract actionable insights from data by applying coding and statistics. After I completed my data science course, I covered market trend analysis, time series, recommender systems, A/B testing, CNNs, computer vision, natural language processing, categorical and continuous modeling, unstructured clustering, and more. I utilized mostly python coding and SQL to complete these projects. These skills can be applied to virtually any topic which is why companies across all industries are hiring data scientists who need domain knowledge.
As the decade draws to a close, I thought I’d take the opportunity to discuss trends in the industry, popular frameworks, some helpful tools that I have had the opportunity to use, and tools that I look forward to using more in the future.
Employment Outlook
I decided to join the data science field for several reasons. I have a business degree and a background in finance and real estate. Since I graduated from college, I noticed that the preferred qualification sections of my target jobs were more and more populated by knowledge of python, SQL, and machine learning. I was also working with large data sets that excel could no longer handle. I wanted to become as competitive and relevant as possible so I began to look for programs that would cover these skills. After a significant amount of research, I decided to explore data science.
Data Scientist took the number three spot on LinkedIn’s 2020 US Emerging Jobs Report, experiencing 37% annual growth in the field. According to a Glassdoor survey of 4,354 respondents in 2018, the starting salary for an Entry Level Data Scientist is $101,087 per year. These employment statistics should look promising to practicing and aspiring data scientists.

Tab 2 of “Computer and Information Research Scientists” includes Data science. Source: U.S. BUREAU OF LABOR STATISTICS.
Frameworks
Data Science is statistics merged with computer science, among other things. The Python coding language has a growing number of packages that enable data scientists to wrangle data and create models. The libraries I’ve used most often are (in no particular order):
- Pandas— Structures your raw data as a data frame and performs summary statistics
- NumPy— Numerous calculations that can be efficiently performed on n-dimensional arrays
- Scikit-learn— Numerous machine learning models and evaluation metrics
- Matplotlib— Standard and highly customizable statistics visualizations
- Seaborn— Statistical visualizations, simpler to implement than Matplotlib
- Plotly and Plotly Express— Interactive and statistical visualizations, simpler to implement than Matplotlib
- Folium— Geospatial visualizations, i.e., a choropleth map
- TensorFlow and its Keras implementation— Deep learning libraries that enable model development and transfer learning. Can be applied to numerous types of data, i.e., text, image, audio, etc.
Cloud-Based Tools
Google Colab, Amazon EMR, and IBM Watson Studio all allow you to run Jupyter Notebook style files remotely. These platforms also enable you to store and access data in the cloud to build models, in addition to utilizing powerful GPUs to train models faster than you would be able to on your local machine’s CPU. These GPUs can be rented on a per hour basis. Postman is another service that enables you to rent GPUs.
Helpful Tools
AST Literal Evaluation
In numerous projects, I would create a column of arrays in a pandas data frame. I would then need to save the data frame and retrieve the data later on. No matter what file type I used, whenever I read in the saved file the arrays column would load as a string type with literal spaces (\n) between each element. This is an especially frustrating problem when you’ve spent hours web scraping or obtaining embeddings from a model and you have a deadline approaching. Fortunately, python’s Abstract Syntax Trees (ast) module’s literal_eval() method is there to solve this issue. I used a series of .replace() statements on the malformed array to replace the \n and other abnormal characters with literal spaces. I then added brackets to the string to make it look like an array. Once the string reads like an array I applied the ast method to the string and obtained an actual array. The statement which returned the array is as follows:
asarray(ast.literal_eval(embedding_as_string)).astype(‘float32’)
Breaking down the above statement:
- embedding_as_string — The retrieved string that should be an array with all irregular characters removed (i.e., \n). Normally appears when reading a file into a pandas data frame where the original data type was an array.
- literal_eval() — The method for reading the string syntax
- asarray() — A NumPy method for converting the string syntax to an array
- .astype(‘float32’) — The array in this scenario contained elements that are floating-point decimals, this converts the individual elements to the float32 type.
All together this statement takes in a malformed string representation of an array and returns an actual array.
TQDM
Speed matters, especially during live demonstrations. I completed a facial similarity program that compared a user’s face embeddings to a database of embeddings of celebrities and politicians. I used the cosine similarity metric to compare the users to the database in a live demonstration. I originally utilized Scikit-learn’s method, but the live demonstration was far too slow. I searched for the bottleneck by putting text print statements after each function. I soon discovered that the calculation of cosine similarity was taking far too long. I read about the speed of NumPy calculations and decided to switch to a pure NumPy implementation of the calculation after reading Danushka Bollegala’s article. Out of curiosity, I searched for a way to time the difference between the two functions and my colleague suggested the TQDM project.
I use Jupyter Notebooks to build functions because I like to test the output before I build a python script. TQDM creates a visible status bar which enables us to view the progress of loops.

An example of a TQDM status bar on a lambda function iterating over a Pandas data frame.
The TQDM status bar tells you which iteration the function is completing, the total number of expected iterations (helpful for locating problems if the function breaks), the total time spent, the expected remaining time, and the number of iterations per second. TQDM works well with Jupyter Notebooks. The NumPy implementation of cosine similarity was 75% faster than the Scikit-learn implementation on my data set.
What I’m Looking Forward To Using
Containerization
The ability to share code and projects is becoming a necessity in the data science field. Containerization is the practice of packaging software in a way that will run consistently and efficiently across all machines. Docker is a popular platform for containerization. It essentially creates a package of software with the versions of each library used so that it can be consistently loaded and run on different machines. When you run a docker container on your machine you will not need to download the original computer’s operating system or common dependent libraries, which is why containerization is more efficient.
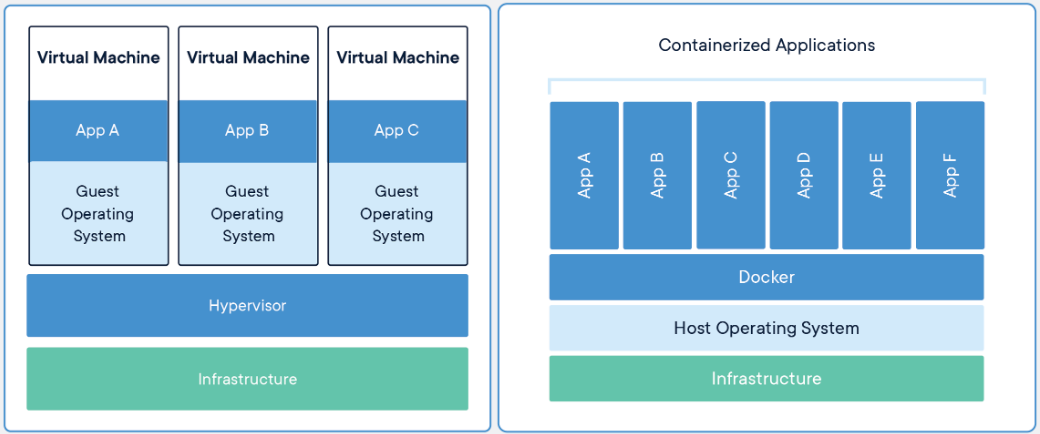
A virtual machine (VM) versus a container. The VM requires the operating system and then downloads the related libraries, and the container does not require the operating system and only downloads the libraries that are not already on the machine. Source: docker.com.
Applying containerization to data science projects can be tricky because of how abstract and customizable a container is. The most common container I’ve interacted with is one that holds a SQL database with python scripts that run queries. Docker’s quickstart guide covers the basics of a container and related terminology. I found that reverse engineering a container made for the specific purpose I have in mind is the best way to practice building different types of containers. Once I have I similar container I can utilize the Docker documentation to adapt it for my purposes.
Transfer Learning With Keras
I’m looking forward to building more deep learning projects with transfer learning. Transfer learning is the practice of applying the knowledge of a model built for one purpose to build a model for another purpose.

“Traditional learning versus transfer learning” Source: “A Comprehensive Hands-on Guide to Transfer Learning with Real-World Applications in Deep Learning” by: Dipanjan (DJ) Sarkar.
For example, you can incorporate a pre-trained facial recognition model to another dataset of pictures without having to train a model from scratch. Keras enables us to load pre-trained models and adapt them to other datasets.
OpenScale
I recently had a conversation with a Master Inventor at IBM about Watson OpenScale. The project was presented to me in an interesting way. We agreed that the majority of a data scientist’s time is spent obtaining and cleaning data, and then asking the right questions. Building the actual model takes comparatively less time and is not as hard as the previous parts of a project. If you are working on a categorical project, you will build several models and use a tool like GridSearch to tune the model to the most effective hyperparameters. You will then select a metric to compare the models and select the most effective one for your purposes. This type of model building depends on your ability to select the best range for each parameter and patience for waiting for the GridSearch to locate the optimal hyperparameter values. OpenScale takes this process to the next level by essentially working as a cloud-based GridSearch of categorical models and each model’s parameters. This makes the shortest portion of a data science project even shorter and enables data scientists to focus on the more important parts of a project: EDA, asking the right questions, drawing actionable insights, and clearly communicating their findings to all stakeholders.
Summary
The outlook for the data science field is strong. There are always newer tools being released that I look forward to using. This field covers a growing amount of topics, which means there is always something new to learn. Data science can be applied to any industry for multiple purposes and can create value for any organization if you ask the right questions.
Originally published in Analytics Vidhya and also Medium. Reposted with permission.
Bio: Alex Mitrani is a Data scientist with a passion for using technology to make informed decisions. Alex's experience includes Real Estate and Finance where he analyzed investments and managed customer relationships. Alex completed the Flatiron School's Data Science program and graduated from Boston University with a major in finance.
Related: