TensorFlow 2.0 Tutorial: Optimizing Training Time Performance
Tricks to improve TensorFlow training time with tf.data pipeline optimizations, mixed precision training and multi-GPU strategies.
By Raphael Meudec, Data Scientist @ Sicara
This tutorial explores how you can improve training time performance of your TensorFlow 2.0 model around:
- tf.data
- Mixed Precision Training
- Multi-GPU Training Strategy
I adapted all these tricks to a custom project on image deblurring, and the result is astonishing. You can get a 2–10x training time speed-up depending on your current pipeline.
Usecase: Improving TensorFlow training time of an image deblurring CNN
2 years ago, I published a blog post on Image Deblurring with GANs in Keras. I thought it would be a nice transition to pass the repository in TF2.0 to understand what has changed and what are the implications on my code. In this article, I’ll train a simpler version of the model (the cnn part only).
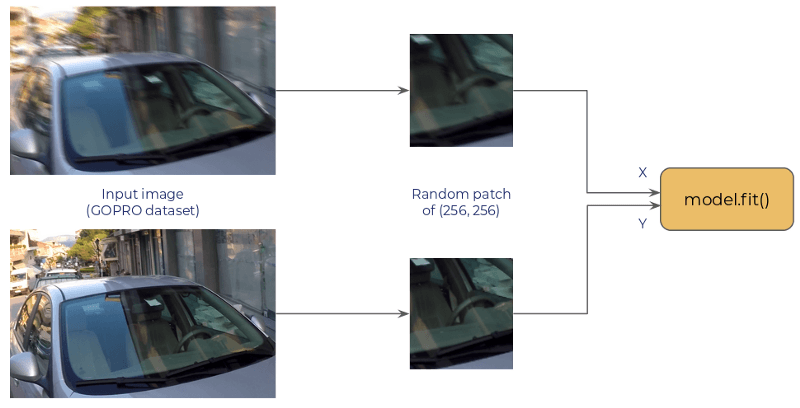
The model is a convolutional net which takes the (256, 256, 3) blurred patch and predicts the (256, 256, 3) corresponding sharp patch. It is based on the ResNet architecture and is fully convolutional.
Step 1: Identify bottlenecks
To optimize training speed, you want your GPUs to be running at 100% speed. nvidia-smi is nice to make sure your process is running on the GPU, but when it comes to GPU monitoring, there are smarter tools out there. Hence, the first step of this TensorFlow tutorial is to explore these better options.
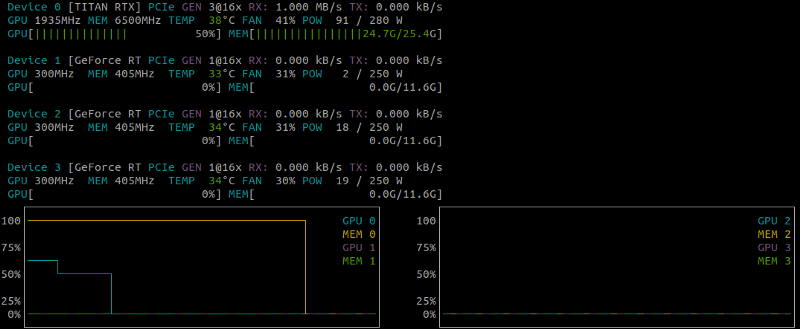
nvtop
If you’re using an Nvidia card, the simplest solution to monitor GPU utilization over time might probably be nvtop. Visualization is friendlier than nvidia-smi, and you can track metrics over time.
TensorBoard Profiler
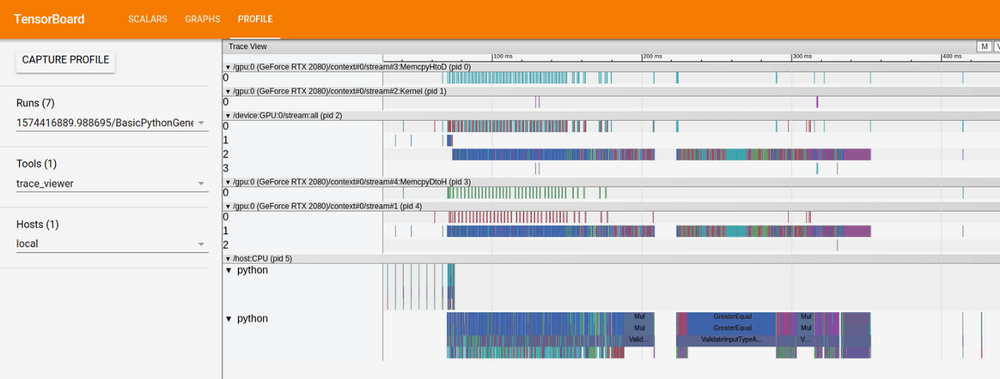
By simply setting profile_batch={BATCH_INDEX_TO_MONITOR} inside the TensorBoard callback, TF adds a full report on operations performed by either the CPU or GPU for the given batch. This can help identify if your GPU is stalled at some point for lack of data.
This is a Jupyterlab extension which gives access to various metrics. Along with your GPU, you can also monitor elements from your motherboard (CPU, Disks, ..). The advantage is you don’t have to monitor a specific batch, but rather have a look on performance over the whole training.
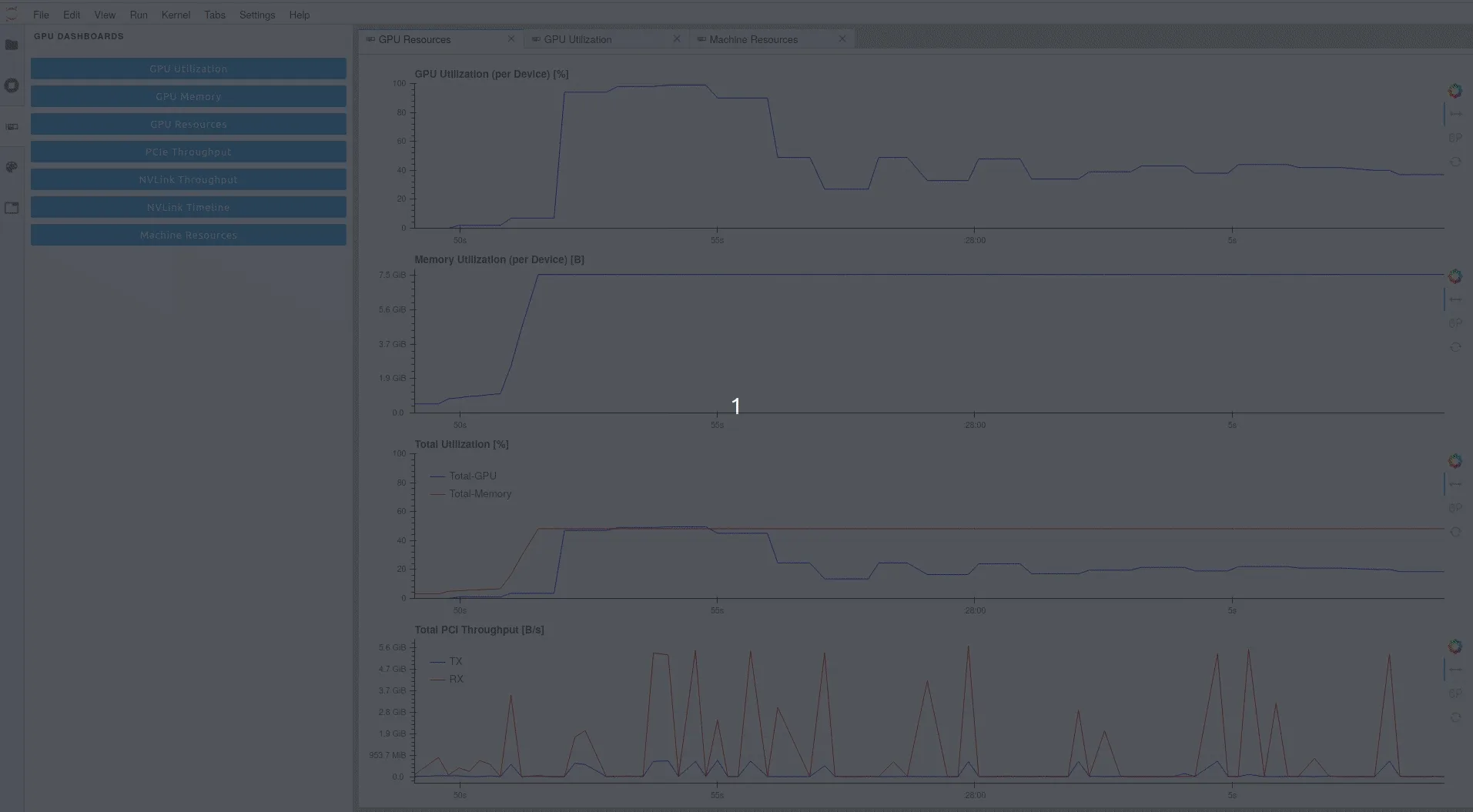
Here, we can easily spot that GPU is at 40% speed most of the time. I have activated only 1 of the 2 GPUs on the computer, so total utilization is around 20%.
Step 2: Optimize your tf.data pipeline
The first objective is to make the GPU busy 100% of the time. To do so, we want to reduce the data loading bottleneck. If you are using a Python generator or a Keras Sequence, your data loading is probably sub-optimal. Even if you’re using tf.data, data loading can still be an issue. In my article, I initially used Keras Sequences to load the images.
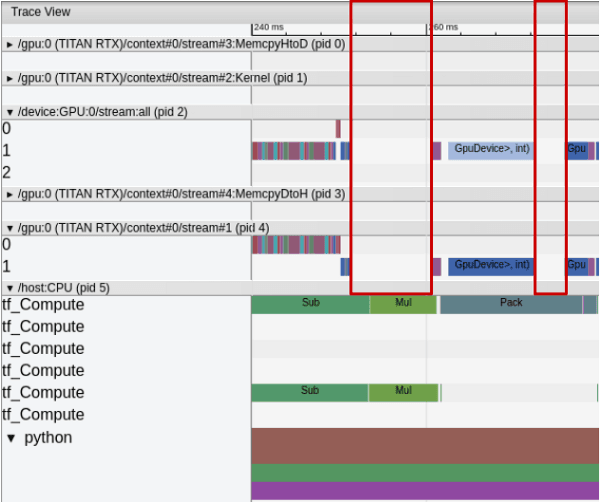
You can easily spot this phenomenom using the TensorBoard profiling. GPUs will tend to have free time while CPUs are performing multiple operations related to data loading.
Making the switch from the original Keras sequences to tf.data was fairly easy. Most operations for data loading are pretty well supported, the only tricky part is to take the same patch on the blurred image and the real one.
Just switching from a Keras Sequence to tf.data can lead to a training time improvement. From there, we add some little tricks that you can also find in TensorFlow's documentation:
- parallelization: Make all the
.map()calls parallelized by adding thenum_parallel_calls=tf.data.experimental.AUTOTUNEargument - cache: Keep loaded images in memory by caching datasets before the patch selection
- prefetching: Start fetching elements before previous batch has ended
The dataset creation now looks like this:
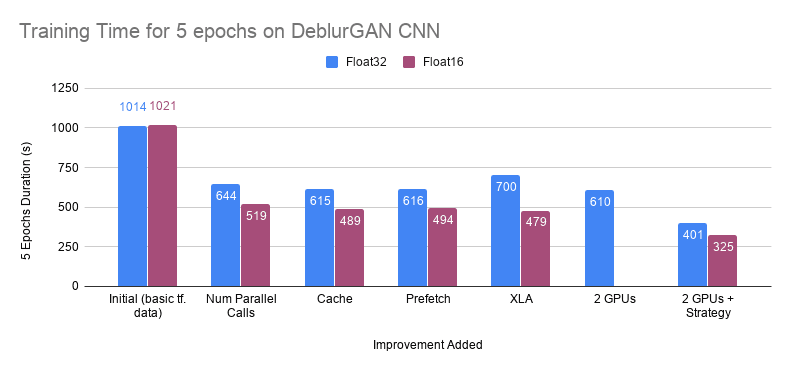
Those small changes make a 5 epochs training time fall from 1000 sec (on an RTX2080) to 616s (full graph is below) .
Step 3: Mixed Precision Training
By default, all variables used in our neural network training are stored on float32. This means every element has to be encoded on 32 bits. The core concept of Mixed Precision Training is to say: we don't need so much precision at all time, let's use 16 bits sometimes.
During the Mixed Precision Training process, you keep a float32 version of the weights, but perform forward and backward passes on float16 versions of the weights. All the expensive operations to obtain the gradients are performed using float16 elements. In the end, you use the float16 gradients to update the float32 weights. A loss scaling is used in the process to keep training stability.
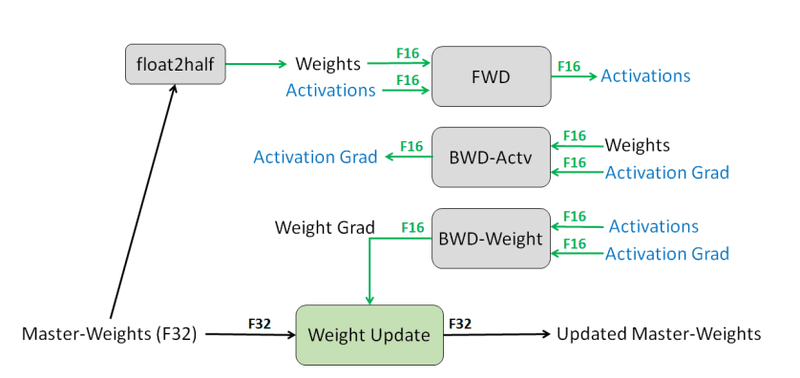
By keeping float32 weights, this process does not lower the accuracy of your models. On the contrary, they claim some performance improvements on various tasks.
TensorFlow makes it easy to implement from version 2.1.0, by adding different Policy. Mixed Precision Training can be activated by using these two lines before model instantiation.
With this method, we can reduce the 5 epochs training time to 480 sec.
Step 4: Multi-GPU Strategies
Last topic concerns how to perform multi-GPU training with TF2.0. If you don't adjust your code for multi-GPU, you won't reduce your TensorFlow training time because they won't be efficiently used.
The easiest way to perform multi-GPU training is to use the MirroredStrategy. It instantiates your model on each GPU. At each step, different batches are sent to the GPUs which run the backward pass. Then, gradients are aggregated to perform weights update, and the updated values are propagated to each model instantiated.
The distribution strategy is again fairly easy with TensorFlow 2.0. You should only think of multiplying the usual batch size by the number of available GPUs.
If you use TPUs, you might consider taking a deeper look at the official Tensorflow tutorial from documentation on training distribution.
Wrap-up on tips to improve your TensorFlow training time
All those steps lead to a massive reduction of your model training time. This graph traces the 5 epochs training time after each improvement of the training pipeline. I hope you enjoy this TensorFlow tutorial on training time performance. You can ping me on Twitter (@raphaelmeudec) if you have any feedback!
Bio: Raphael Meudec (@raphaelmeudec) is a Data Scientist at Sicara.
Original. Reposted with permission.
Related:
- Hands on Hyperparameter Tuning with Keras Tuner
- Easy Image Dataset Augmentation with TensorFlow
- Transfer Learning Made Easy: Coding a Powerful Technique