Are Tera Operations Per Second (TOPS) Just hype? Or Dark AI Silicon in Disguise?
This article explains why TOPS isn’t as accurate a gauge as many people think, and discusses other criteria that should be considered when evaluating a solution to a real application.
By Ludovic Larzul, Founder and CEO, Mipsology
It is natural for humans to try to simplify how we compare things. People like to gravitate towards a single metric to summarize our vision of the world; for example, a higher IQ equals intelligence, fewer calories are the secret to health and weight losss, and a higher star rating means a better product or service.
But can we really simplify the world with one number? For CPUs in the 1990s, Intel made us believe that the highest MHz was just better. In the 2000s, we discovered that MHz was just one measure, and threads or cache are just as important. For machine learning, the hype today is about Tera Operations Per Second (TOPS). Many believe that the highest TOPS is the best for neural network (NN) performance. That’s because the AI processor companies hype their TOPS numbers as the gold standard for performance. But does TOPS really provide any measure in a field as complicated as AI, with so many different NNs and the technology advancing at such a fast pace?
A true evaluation of neural network performance should consider the application and assess several different benchmarks. In this piece, I will explain why TOPS isn’t as accurate a gauge as many people think, and discuss other criteria that should be considered when evaluating a solution to a real application, so that you line up the right solution for your needs.
Neural Network Numerology
An operation for a neural network typically involves simple addition or multiplication, and one NN can require billions of them to process one piece of data, like an image. TOPS is a measure of Operations Per Second, in Trillions, that a chip can process. So, more TOPS should equal more processing… That’s great, but “more” doesn’t always equal “better.”
In the real world, we need to evaluate performance as it relates to cost and needs. Marketing aside, pricing is generally proportional to the amount of silicon, and a chip will need more silicon to crank out more TOPS.
You can expect more TOPS to simply cost you more money. So, what if you cannot use all those TOPS? This is equivalent to what has been called “dark silicon,” the ultimate symbol of chip overengineering and diminishing returns. Dark silicon is the amount of circuitry that cannot be powered because transistor and voltage scaling no longer align. In AI, it seems we have already entered the dark silicon era: the amount of data processed no longer scales linearly with the number of TOPS available from AI-oriented chips. And as the price is quite proportional to TOPS, this means wasting money on silicon that cannot be fully used.
What Architectures and Metrics Matter in Image Computation?
For convolutional NNs, which are most commonly used to analyze visual information, a more appropriate measurement is “images processed per second.” One well-established metric involves ResNet-50, a neural network that is designed for image classification. By comparing the output of ResNet-50, you should get an accurate measurement of the performance of a chip.
Granted, ResNet-50 is only one network among many, and is not widely used as-is for real applications, as far as we have seen. Real performance can be found only by running the actual NN, but ResNet-50 at least gives one measure of a chip’s quality. It’s sort of a ‘common ground.’ While TOPS may still be a subject of debate, ResNet-50 is at least a widely accepted neural network. So, let’s look at the best solution for the most commonly discussed silicon:
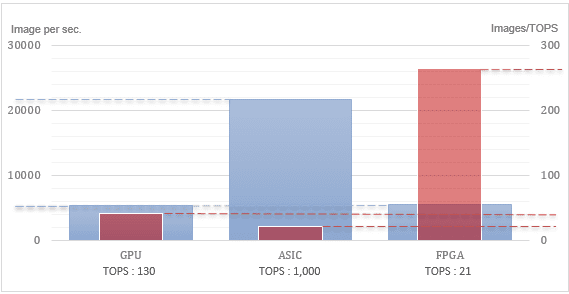
This graph shows the performance of an nVdia GPU, a Groq™ ASIC, and a Zebra™ powered FPGA, the number of TOPS the silicon can run, and the ratio of the former and latter (to show silicon utilization).
GPU is the obvious reference. Based on nVidia’s numbers, it does not have the best performance, but it does an honest job of putting the 130 TOPS into action. As a lot of the silicon goes to the gaming ability of the chip, the GPU seems to have limitations in processing this simple neural network.
There is a lot of hype building around ASICs for machine learning, and it is certainly driving hundreds of millions of dollars into that field. One startup seems to be ahead of the others, as it announced an impressive 1,000 TOPS with expected performance about four times higher than the GPUs for ResNet50. As the ASIC is designed for this kind of NN, it is not surprising that it demonstrates higher performance than a chip that was not intended chiefly for machine learning. However, what is surprising is that about 7.5x the number of TOPS results in only about 4x the performance. In other words, relatively to TOPS, about 50% of the chip is “dark” for NN computations. That is quite a lot of silicon unused but paid for especially for a chip tailored for NN computations.
FPGAs have long been considered a possible solution for NN inference. However, the programming challenges have impeded adoption. Some companies are now working on software solutions that eliminate the need to program FPGAs for machine learning. These solutions make the FPGA look like a GPU to AI frameworks, and enable computation of NN without FPGA competence. This works quite well in terms of silicon efficiency. While the FPGA supports less than 1/6th the TOPS of the GPU, it delivers a similar number of images per second. Relatively, the silicon of the GPU is only about 15% used, and the silicon of the ASIC only 8%. Therefore, even though you’re giving up some TOPS, you’re getting more efficiency and comparable performance with an FPGA.
Normalizing the silicon size, this is basically what we are looking at:
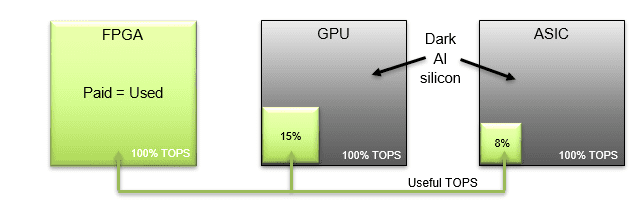
This shows that TOPS is definitely not a number to consider as the only measure of efficiency. It also shows that many of the chips are already full of dark AI silicon, which cannot be used for actual computing. Of course, to have a full understanding, the same comparison would need to be conducted on more neural networks.
Images per second is a better way of measuring convolutional NN performance but is still only useful if the exact neural network is used for comparison. A slight change can impact a cache, or a round division of operations can turn into a small remainder, drastically reducing the efficiency.
Many other aspects must be considered, as well. For example, the lifespan of the silicon: GPUs were designed for gamers, with a goal of packing the maximum number of transistors per mm2 and selling a replacement every other year. AI ASICs have no track record and are manufactured with very little verification of their behavior, raising questions about the quality of results or possible random failures.
Conclusion
It is a mistake to rely on a “one size fits all” metric when evaluating the performance of a chip used to compute neural networks. It might wind up costing more and not achieve your goals. Conversely, there are huge benefits to considering the right metrics, in terms of optimizing ROI, performance and lifetime TCO. On the specific ResNet50 benchmark, the efficiency reached by FPGAs over GPUs and ASICs is powerful evidence that more TOPS does not translate directly into more images processed.
References:
Performance and TOPS numbers obtained from publicly available documents in May 2020:
- nVidia: https://developer.nvidia.com/deep-learning-performance-training-inference
- Groq: https://groq.com
- Zebra: https://mipsology.com/
Bio: Ludovic Larzul has more than 25 years of experience driving product development, and has authored 16 technical patents. He previously co-founded and served as VP of engineering for Emulation and Verification Engineering (EVE), a startup that designed specialized ASIC validating supercomputers. Ludovic led the company to a 2012 acquisition by Synopsys, where he served as R&D group director before founding Mipsology in 2018. He holds an MS in Microelectronics from France’s Universite de Nantes, and an MS in Computer Science from Polytech Nantes.
Related:
- AI and Machine Learning for Healthcare
- Accuracy Fallacy: The Media’s Coverage of AI Is Bogus
- Demystifying the AI Infrastructure Stack