Recommender Systems in a Nutshell
Marketing scientist Kevin Gray asks Dr. Anna Farzindar of the University of Southern California about recommender systems and the ways they are used.
By Kevin Gray and Anna Farzindar

Kevin Gray: What are recommender systems?
Anna Farzindar: When you search for a product on Amazon, the algorithm suggests other items with the note “Recommended for you, Kevin” or “Customers who bought this item also bought…”
Recommender systems predict the preference of the user for these items, which could be in form of a rating or response. When more data becomes available for a customer profile, the recommendations become more accurate.
There are a variety of applications for recommendations including movies (e.g. Netflix), consumer products (e.g., Amazon or similar on-line retailers), music (e.g. Spotify), or news, social media, online dating and advertising.
Could you give us a brief history of how they came about?
The World Wide Web continues to grow rapidly around the world, and it is necessary to develop algorithms to analyze the high volume of information it produces. Especially with the transition of traditional retailers to on-line vending and e-commerce, the Web enables near-zero-cost diffusion of information about products. A physical store has limited shelf space and can only provide what is popular, but an on-line retailer like Amazon offers millions of products.
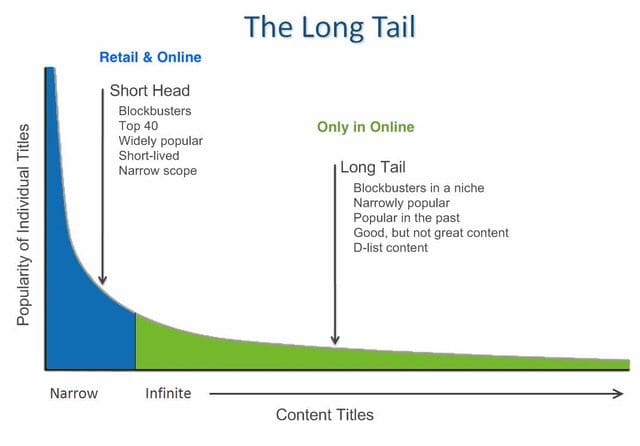
This concept has been called the “Long Tail'' phenomenon as shown below. The vertical axis represents the popularity of items and the horizontal axis the options based on their popularity. Physical stores can only offer popular products, while on-line stores can make everything available to a buyer anywhere. The role of the recommendation system is to suggest items to users that include popular ones and those on the long tail.
From 2006 to 2009, Netflix, a streaming service offering TV shows, movies and documentaries on internet-connected devices, conducted a competition with a grand prize of $1M for the winning recommendation system. They provided a dataset of over 100 million movie ratings by anonymous Netflix customers between 1999 and 2005, and the winner had to improve the baseline predictions of Netflix's existing system by 10%. In September 2009, the grand prize was given to the BellKor's Pragmatic Chaos team.

What is their current state-of-the-art? What sorts of things are they especially useful for and, conversely, in what ways are they still a work-in-progress?
There are several approaches used to build recommender systems, including content-based, collaborative filtering, knowledge-based and hybrid methods.
The main idea of a content-based approach is to recommend items to a customer that are similar to previous items rated highly by him or her. This requires characterizing the content of items. For example, if an item is a movie, then features like actors, director, genre, and language could describe the item. The system will predict the movie to recommend that matches the user’s preferences based on these characteristics.
Collaborative filtering employs the user's past behavior and information from similar choices made by other users (their “neighborhood”). The recommender model predicts items the user may like. For example, if a user gave a high rating, then the model finds other users whose ratings are similar to this user’s ratings.
User-based collaborative filtering predicts the user’s ratings based on ratings of others in their neighborhood. The computational complexity of search for similar users is a bottleneck for these models. Additionally, the system must deal with complicated users preferences, for example when the same user likes documentary and action movies.
In Item-based collaborative filtering, rather than matching similar users, the model matches user’s rated items to similar items in the database. These models are faster online and, since the approach analyses item rather than user data, they can provide better recommendations.
Hybrid recommender systems combine various inputs and different recommendation strategies to take advantage of the synergy among them.
What are the key challenges they face from a technical perspective?
Among many technical challenges and limitations are the following.
- Lack of Data: Recommender systems need a large volume of data to make predictions effectively. Huge corporations such as Google, Apple, and Amazon are able to make better recommendations because they continuously collect data on their customers. Also, there are recommender systems based on purchases only, i.e., no ratings are collected. Even Amazon does not know how much a customer liked a book, for example, if they do not rate it.
- Cold start: When a new item is added to the catalogue or a new user joins the service, the system has very little historical information with which to make suggestions.
- Changing Data and User Preferences: Recommendation is a very dynamic field. Thousands of items are continuously added to catalogues, with millions of features. User preferences are changing, in addition. Therefore, markets and trends are always shifting.
How can we tell if a recommender system works as claimed? What are some things to look for?
The evaluation of recommendation engines is challenging. The metric used in Netflix’s grand prize was RMSE (Root Mean Squared Error). RMSE pertains to regression problems where the predicted output (e.g., a predicted movie rating) is compared with the true value output (e.g., the actual rating).
Other evaluation methods measure the number of items selected from the long tail in user recommendation, which is a limited item list.
Thinking about the future, where are recommender systems heading?
With more data and consumers, recommender systems become smarter. They not only can predict one user’s preference but a group’s preference, for example, a group of travelers or recommendations for a music playlist.
Detecting unfairness and reducing bias in algorithms are other important considerations. For example, identification of popularity bias is challenging when an item or a movie is very popular or frequently rated, but not relevant for every user.
How can we learn more about recommender systems? Are there sources you can suggest?
Here are a few sources for more information about recommender systems.
- Overview of some major recommendation algorithms: https://towardsdatascience.com/introduction-to-recommender-systems-6c66cf15ada
- How companies make product recommendations:
https://towardsdatascience.com/recommender-systems-in-practice-cef9033bb23a - Wikipedia: https://en.wikipedia.org/wiki/Recommender_system
- Rajaraman, J. Leskovec and J. D. Ullman, Mining of Massive Datasets, 3rd edition, Chapter 9 Recommendation Systems, Cambridge University Press, 2019. http://infolab.stanford.edu/~ullman/mmds/ch9.pdf
- Hybrid Recommender Systems: Survey and Experiments. Burke, R. User Modeling and User-Adapted Interaction 12, 331–370 (2002).
https://link.springer.com/article/10.1023/A:1021240730564 - Deep Learning based Recommender System: A Survey and New Perspectives, Shuai Zhang Sh. Yao L. Sun A. and Tay Y. Journal of ACM Computing Surveys, 2019.
https://arxiv.org/pdf/1707.07435.pdf - Multistakeholder recommendation: Survey and research directions, Abdollahpouri, H., Adomavicius, G. , Burke, R. , Ido, G. , Jannach, D., Toshihiro, K. and Krasnodebski, J. and Pizzato, L., Journal of User Modeling and User-Adapted Interaction, 2020. https://link.springer.com/article/10.1007/s11257-019-09256-1
Thank you, Anna!
Kevin Gray is President of Cannon Gray, a marketing science and analytics consultancy.
Anna Farzindar, Ph.D. is a faculty member of the Department of Computer Science, Viterbi School of Engineering, University of Southern California. Her Instagram art page is
https://www.instagram.com/afar90210/. The painting shown in the background photo was done with ink and acrylic on handmade paper (30” x 22”).
Related:
- Recommender System Metrics: Comparing Apples, Oranges and Bananas
- Automatic Text Summarization in a Nutshell
- Chatbots in a Nutshell