5 Must-Read Data Science Papers (and How to Use Them)
Keeping ahead of the latest developments in a field is key to advancing your skills and your career. Five foundational ideas from recent data science papers are highlighted here with tips on how to leverage these advancements in your work, and keep you on top of the machine learning game.

Photo by Rabie Madaci on Unsplash.
Data science might be a young field, but that doesn’t mean you won’t face expectations about having an awareness of certain topics. This article covers several of the most important recent developments and influential thought pieces.
Topics covered in these papers range from the orchestration of the DS workflow to breakthroughs in faster neural networks to a rethinking of our fundamental approach to problem solving with statistics. For each paper, I offer ideas for how you can apply these ideas to your own work
#1 — Hidden Technical Debt in Machine Learning Systems
The team at Google Research provides clear instructions on antipatterns to avoid when setting up your data science workflow. This paper borrows the metaphor of technical debt from software engineering and applies it to data science.
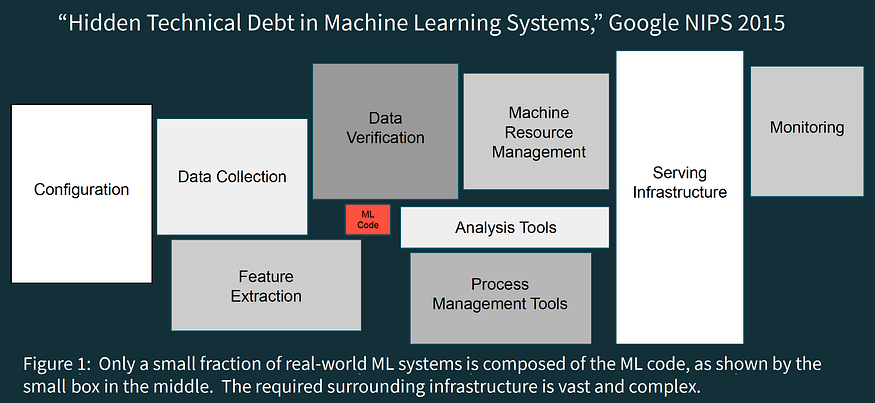
via DataBricks.
As the next paper explores in greater detail, building a machine learning product is a highly specialized subset of software engineering, so it makes sense that many lessons drawn from this discipline will apply to data science as well.
How to use: follow the experts’ practical tips to streamline development and production.
#2 — Software 2.0
This classic post from Andrej Karpathy articulated the paradigm that machine learning models are software applications with code based on data.
If data science is software, what exactly are we building towards? Ben Bengafort explored this question in an influential blog post called “The Age of the Data Product.”

The data product represents the operationalization phase of an ML project. Photo by Noémi Macavei-Katócz on Unsplash.
How to use: read more about how the data product fits into the model selection process.
#3 — BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
In this paper, the team at Google Research put forward the natural language processing (NLP) model that represented a step-function increase in our capabilities in for text analysis.
Though there’s some controversy over exactly why BERT works so well, this is a great reminder that the machine learning field may have uncovered successful approaches without fully understanding how they work. As with nature, artificial neural networks are steeped in mystery.
In this delightful clip, the Director of Data Science at Nordstrom explains how artificial neural nets draw inspiration from nature.
How to use:
- The BERT paper is imminently readable and contains some suggested default hyperparameter settings as a valuable starting point (see Appendix A.3).
- Whether or not you’re new to NLP, check out Jay Alammar’s “A Visual Guide to Using BERT for the First Time” for a charming illustration of BERT’s capabilities.
- Also, check out ktrain, a package that sits atop Keras (which in turn sits atop TensorFlow) that allows you to effortlessly implement BERT in your work. Arun Maiya developed this powerful library to enable speed to insight for NLP, image recognition, and graph-based approaches.
#4 — The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks
While NLP models are getting larger (see GPT-3’s 175 billion parameters), there’s been an orthogonal effort to find smaller, faster, more efficient neural networks. These networks promise quicker runtimes, lower training costs, and less demand for compute resources.
In this groundbreaking paper, machine learning wiz kids Jonathan Frankle and Michael Carbin outline a pruning approach to uncover sparse sub-networks that can attain comparable performance to the original, significantly larger neural network.
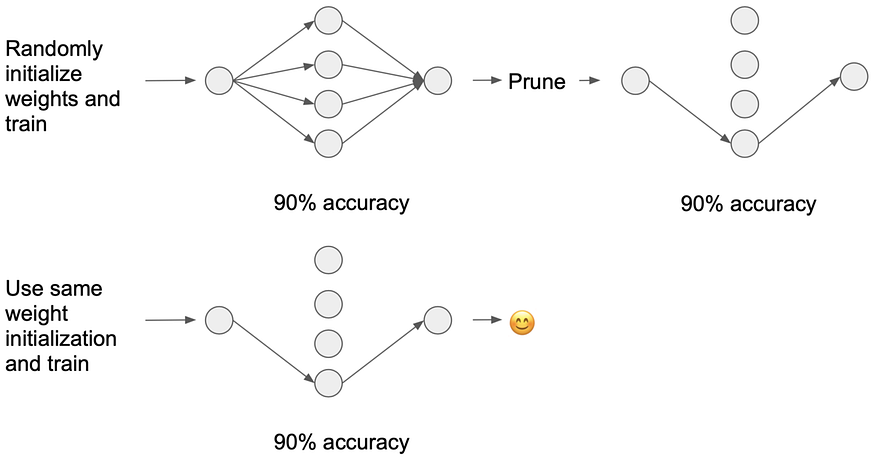
via Nolan Day’s “Breaking down the Lottery Ticket Hypothesis.”
The Lottery Ticket refers to the connections with initial weights that make them particularly effective. The finding offers many advantages in storage, runtime, and computational performance - and won a best paper award at ICLR 2019. Further research has built on this technique, proving its applicability and applying it to an originally sparse network.
How to use:
- Consider pruning your neural nets before putting them into production. Pruning network weights can reduce the number of parameters by 90%+ while still achieving the same level of performance as the original network.
- Also, check out this episode of the Data Exchange podcast where Ben Lorica talks to Neural Magic, a startup that’s looking to capitalize on techniques such as pruning and quantization with a slick UI that makes achieving sparsity easier.
Read more:
- Check out this interesting sidebar from one of the “The Lottery Ticket” authors about flaws in how the machine learning community evaluates good ideas.
#5 — Releasing the death-grip of null hypothesis statistical testing (p < .05)
Classical hypothesis testing leads to over-certainty and produces the false idea that causes have been identified via statistical methods. (Read more)
Hypothesis testing predates the use of computers. Given the challenges associated with this approach (such as the fact that even statisticians find it nearly impossible to explain p-value), it may be time to consider alternatives such as somewhat precise outcome testing (SPOT).

“Significant” via xkcd.
How to use:
- Check out this blog post, “The Death of the Statistical Tests of Hypotheses,” where a frustrated statistician outlines some of the challenges associated with the classical approach and explains an alternative utilizing confidence intervals.
Original. Reposted with permission.
Bio: Nicole Janeway Bills is a machine learning engineer with experience in commercial and federal consulting. Proficient in Python, SQL, and Tableau, Nicole has business experience in natural language processing (NLP), cloud computing, statistical testing, pricing analysis, and ETL processes, and aims to use this background to connect data with business outcomes and continue to develop technical skillsets.
Related: