5 Things You Are Doing Wrong in PyCaret
PyCaret is an alternate low-code library that can be used to replace hundreds of lines of code with few words only. This makes experiments exponentially fast and efficient. Find out 5 ways to improve your usage of the library.
By Moez Ali, Founder & Author of PyCaret

PyCaret
PyCaret is an open-source, low-code machine learning library in Python that automates machine learning workflows. It is an end-to-end machine learning and model management tool that speeds up the machine learning experiment cycle and makes you more productive.
In comparison with the other open-source machine learning libraries, PyCaret is an alternate low-code library that can be used to replace hundreds of lines of code with few words only. This makes experiments exponentially fast and efficient.
Official: https://www.pycaret.org
Docs: https://pycaret.readthedocs.io/en/latest/
Git: https://www.github.com/pycaret/pycaret
???? compare_models does more than what you think
When we had released version 1.0 of PyCaret in Apr 2020, compare_models function was comparing all the models in the library to return the averaged cross-validated performance metrics. Based on which you would use create_model to train the best performing model and get the trained model output that you can use for predictions.
This behavior was later changed in version 2.0. compare_models now returns the best model based on the n_select parameter which by default is set to 1 which means that it will return the best model (by default).

By changing the default n_select parameter to 3, you can get a list of top 3 models. For example:

The returned objects are trained models, you really don’t need to call create_model again to train them. You can use these models to generate diagnostic plots or to even use them for predictions, if you would like. For example:
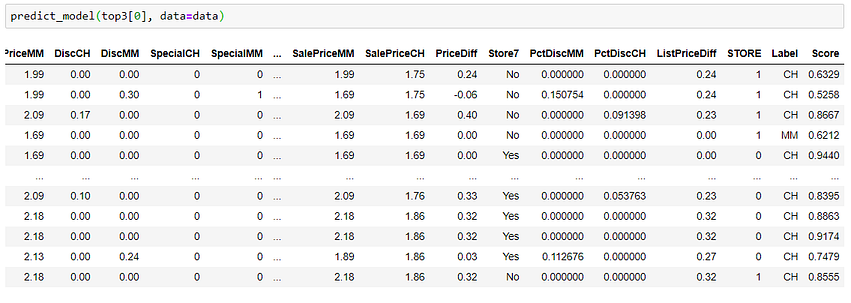
????You think you are limited to scikit-learn models only
We recieve a lot of requests to include non scikit-learn models in the model library. Many people don’t realize that you are not limited to the default models only. create_model function also accepts untrained model object in addition to the ID’s of models available in the model library. As long as your object is compatible with scikit-learn fit/predict API, it will work just fine. For example, here we have trained and evaluated NGBClassifier from ngboost library by simply importing untrained NGBClassifier:
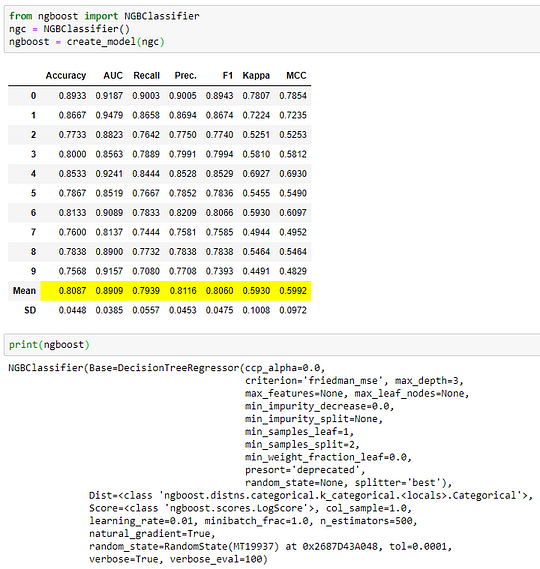
You can also pass the untrained models in the include parameter of the compare_models and it will just work normally.

Notice that include parameters include ID’s for three untrained model from the model library i.e. Logistic Regression, Decision Tree and K Neighbors and one untrained object from ngboost library. Also, notice that the index represents the position of the model entered in the include parameter.
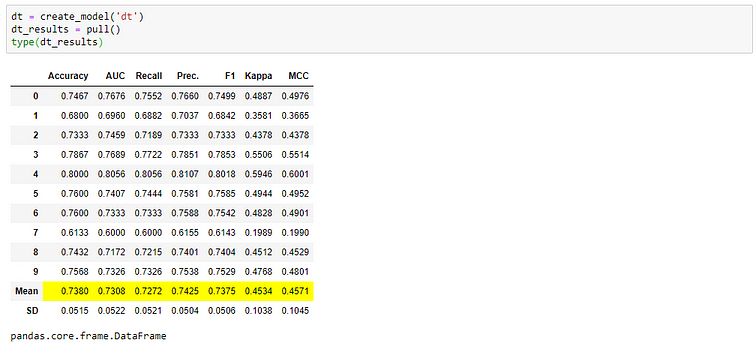
????You don’t know about the pull( ) function
All training functions (create_model, tune_model, ensemble_model, etc.) in PyCaret displays a score grid but it doesn’t return the score grid. Hence you cannot store the score grid in an object like pandas.DataFrame. However, there is a function called pull that allows you to do that. For example:
This will also work for holdout score grid when you use predict_model function.
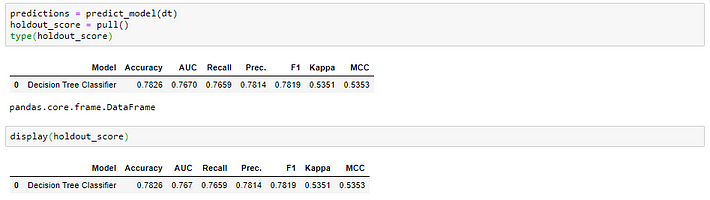
Now that you can access metrics as pandas.DataFrame, you can do wonders. For example, you can create a loop to train a model with different parameters and create a comparison table with this simple code:

???? You think PyCaret is a black-box, it is not.
Another common confusion is that all the preprocessing is happening behind the scenes and is not accessible to users. As such, you cannot audit what happens when you ran the setup function. This is not True.
There are two functions in PyCaret get_config and set_config that allows you to access and change everything in the background, from your training set to the random state of your model. You can check the documentation of get_config function by simply calling help(get_config) to see which variables are accessible to you:
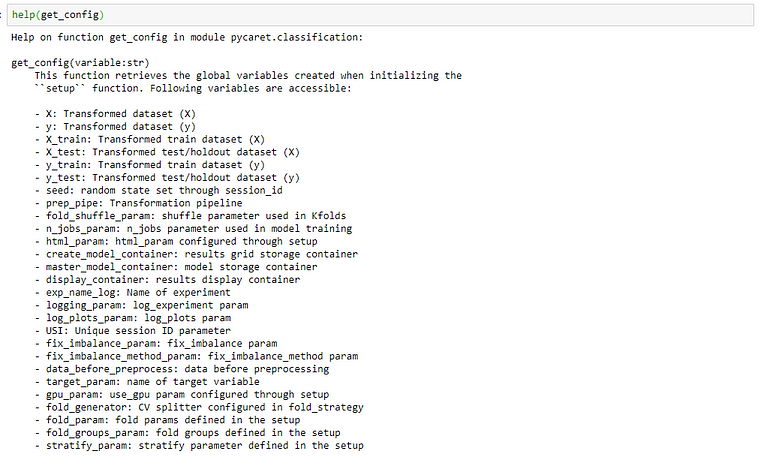
You can access the variable by calling it inside the get_config function. For example to access X_train transformed dataset, you will write this:
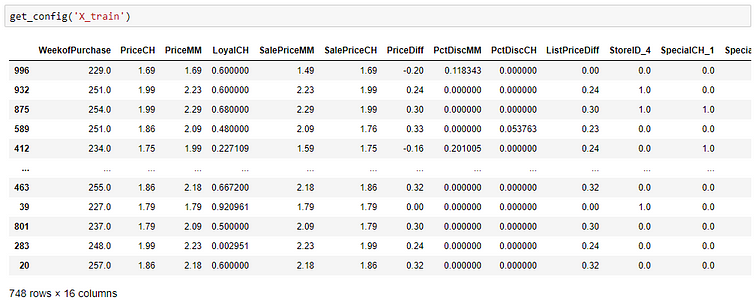
You can use the set_config function to change the environment variables. With what you know so far about pull, get_config, and set_config function, you can create some pretty sophisticated workflows. For example, you can resample holdout set N times to evaluate averaged performance metrics instead of relying on one holdout set:
import numpy as np
Xtest = get_config('X_test')
ytest = get_config('y_test')AUC = []for i in np.random.randint(0,1000,size=10):
Xtest_sampled = Xtest.sample(n = 100, random_state = i)
ytest_sampled = ytest[Xtest_sampled.index]
set_config('X_test', Xtest_sampled)
set_config('y_test', ytest_sampled)
predict_model(dt);
AUC.append(pull()['AUC'][0])>>> print(AUC)[Output]: [0.8182, 0.7483, 0.7812, 0.7887, 0.7799, 0.7967, 0.7812, 0.7209, 0.7958, 0.7404]>>> print(np.array(AUC).mean())[Output]: 0.77513
????You are not logging your experiments
If you are not logging your experiments, you should start logging them now. Whether you want to use MLFlow backend server or not, you should still log all your experiments. When you perform any experiment, you generate a lot of meta data which is impossible to keep track of manually.
PyCaret’s logging functionality will generate a nice, light-weight, easy to understand excel spreadsheet when you use get_logs function. For example:
# loading dataset
from pycaret.datasets import get_data
data = get_data('juice')# initializing setup
from pycaret.classification import *
s = setup(data, target = 'Purchase', silent = True, log_experiment = True, experiment_name = 'juice1')# compare baseline models
best = compare_models()# generate logs
get_logs()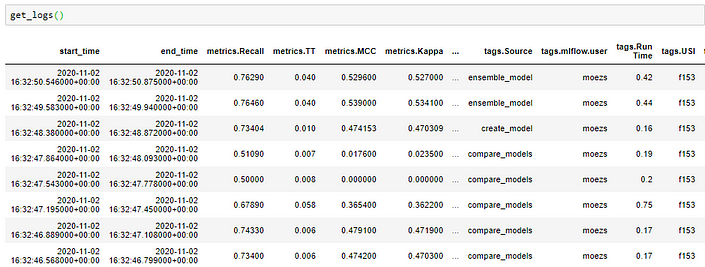
In this very short experiment we have generated over 3,000 meta data points (metrics, hyperparameters, runtime, etc.). Imagine how you would have manually kept track of these datapoints? Perhaps, it’s not practically possible. Fortunately, PyCaret provides a simple way to do it. Simply set log_experiment to True in the setup function.
There is no limit to what you can achieve using the lightweight workflow automation library in Python. If you find this useful, please do not forget to give us ⭐️ on our GitHub repo.
To hear more about PyCaret follow us on LinkedIn and Youtube.
To learn more about all the updates in PyCaret 2.2, please see the release notes or read this announcement.
Important Links
User Guide
Documentation
Official Tutorials
Example Notebooks
Other Resources
Want to learn about a specific module?
Click on the links below to see the documentation and working examples.
Classification
Regression
Clustering
Anomaly Detection
Natural Language Processing
Association Rule Mining
Bio: Moez Ali is a Data Scientist, and is Founder & Author of PyCaret.
Original. Reposted with permission.
Related:
- 5 Things You Don’t Know About PyCaret
- Deploy a Machine Learning Pipeline to the Cloud Using a Docker Container
- GitHub is the Best AutoML You Will Ever Need