5 Most Useful Machine Learning Tools every lazy full-stack data scientist should use
If you consider yourself a Data Scientist who can take any project from data curation to solution deployment, then you know there are many tools available today to help you get the job done. The trouble is that there are too many choices. Here is a review of five sets of tools that should turn you into the most efficient full-stack data scientist possible.
By Ian Xiao, Data | ML | Marketing.

Photo by Creatv Eight on Unsplash.
Building good Machine Learning applications is like making Michelin-style dishes. Having a well organized and managed kitchen is critical, but there are too many options to choose from. In this article, I highlight the tools I found useful in delivering professional projects and share a few thoughts and alternatives. Like any tooling discussion, the list is not exhaustive. I try to focus on the most useful and simplest tools.
Disclaimer: This post is not endorsed or sponsored. I use the term Data Science and ML interchangeably.
“How do I build good Machine Learning applications?”
This question came up many times and in various forms during chats with aspiring data scientists in schools, professionals who are looking to switch, and team managers.
There are many aspects of delivering a professional data science project. Like many others, I like to use the analogy of cooking in a kitchen: there is the ingredient (data), the recipe (design), the process of cooking (well, your unique approach), and finally, the actual kitchen (tools).
So, this article walks through my kitchen. It highlights the most useful tools to design, develop, and deploy full-stack Machine Learning applications — solutions that integrate with systems or serve human users in Production environments.
Overwhelming Possibilities
We live in a golden age. If you search “ML tools” in Google or ask a consultant, you are likely to get something like this:

Data & AI Landscape 2019, Image Source.
There are (too) many tools out there; the possible combination is infinite. It can be confusing and overwhelming. So, let me help you to narrow it down. That said, there is no perfect setup. It all depends on your needs and constraints. So pick, choose, and modify accordingly.
My list prioritizes the following (not in order):
- Free
- Easy to learn and setup
- Future proved (adoption & tool maturity)
- Engineering over research
- Work for big or small projects at start-up or large enterprises
- Just get the job done
Caveat: I use Python 99% of the time. So the tools work well with or are built with native Python. I haven’t tested them with other programming languages, such as R or Java.
1. The Fridge: Databases
A free and open-source relational database management system (RDBMS) emphasizing extensibility and technical standards compliance. It is designed to handle a range of workloads, from single machines to data warehouses or Web services with many concurrent users.
Alternatives: MySQL, SAS, IBM DB2, Oracle, MongoDB, Cloudera, GCP, AWS, Azure, PaperSpace
2. The Countertop: Deployment Pipeline Tools
Pipeline tools are critical to the speed and quality of development. We should be able to iterate fast with minimum manual processing. Here is a setup that works well. See my 12-Hour ML Challenge article for more details. Every lazy data scientist should try this early on in the project.

Author’s work, 12-Hour ML Challenge.
It offers the distributed version control and source code management (SCM) functionality of Git, plus its own features. It provides access control and several collaboration features such as bug tracking, feature requests, task management, and wikis for every project.
Alternative: DVC, BitBucket, GitLab
PyCharm Community Edition
An integrated development environment (IDE) used in computer programming, specifically for the Python language. It is developed by the Czech company JetBrains. It provides code analysis, a graphical debugger, an integrated unit tester, integration with version control systems (VCSes), and supports web development with Django as well as Data Science with Anaconda.
A framework makes it easy to write small tests yet scales to support complex functional testing for applications and libraries. It saves lots of time from manual testing. If you need to test something every time you make changes to the code, automate it with Pytest.
Alternative: Unittest
CircleCI is a continuous integration and deployment tool. It creates an automated testing workflow using remote dockers when you commit to Github. Circle CI rejects any commit that does not pass the test cases set by PyTest. This ensures code quality, especially when you work with a larger team.
Alternative: Jenkins, Travis CI, Github Action
Heroku (Only when you need web hosting)
A platform as a service (PaaS) that enables developers to build, run, and operate applications entirely in the cloud. You can integrate with CircleCI and Github to enable automatic deployment.
Alternative: Google App Engine, AWS Elastic Compute Cloud, others
Streamlit (Only if you need an interactive UI)
Streamlit is an open-source app framework for Machine Learning and Data Science teams. It’s become one of my favourite tools in recent years. Check out how I used it and the other tools in this section to create a movie and simulation app.
Alternative: Flask, Django, Tableau
3. the iPad: Exploration Tools
Streamlit (again)
Forget about Jupyter Notebook. Yes, that’s right.
Jupyter was my go-to tool for exploring data, doing analysis, and experimenting with different data and modelling processes. But I can’t remember how many times when:
- I spent lots of time debugging (and pulling my hair out), but eventually realized I forgot to run the code from the top; Streamlit fixes this.
- I had to wait a while for my data pipeline to re-run even for a small code change; Streamlit Caching fixes this.
- I had to re-write or convert codes from Jupyter to executables files — and the time spent on re-testing; Streamlit offers a shortcut.
It’s frustrating. So, I use Streamlit to do early exploration and serve the final front-end — killing two birds with one stone. The following is my typical screen setup. PyCharm IDE on the left and result visualization on the right. Give it a try.
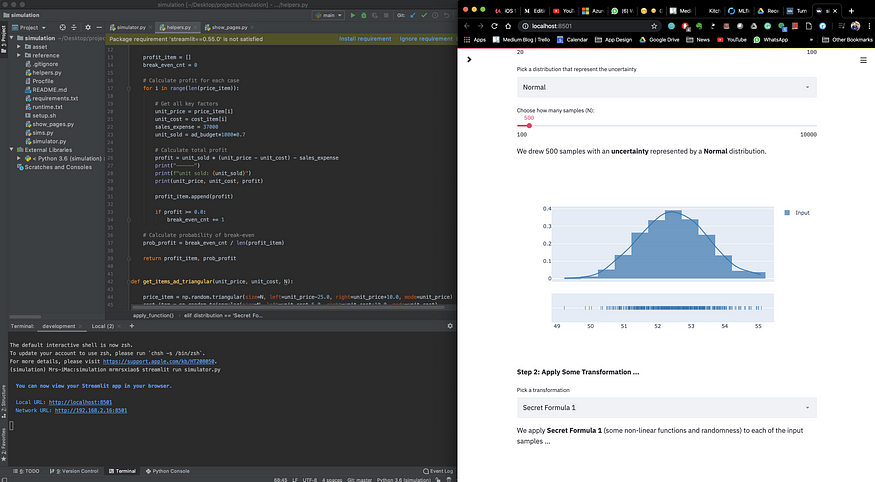
IDE (left) + live update with Streamlit (right), author’s work from the Forgotten Algorithm
Alternative: Jupyter Notebook, Spyder from Anaconda, Microsoft Excel (seriously)
4. The Knives: ML Frameworks
Like using actual knives, you should pick the right ones depending on the food and how you want to cut it. There are general-purpose and specialty knives.
Be cautious. Using a specialty knife for sushi to cut bones will take a long time, although the sushi knife is shinier. Pick the right tool to get the job done.
Scikit-Learn (Common ML use cases)
The go-to framework for doing general Machine Learning in Python. Enough said.
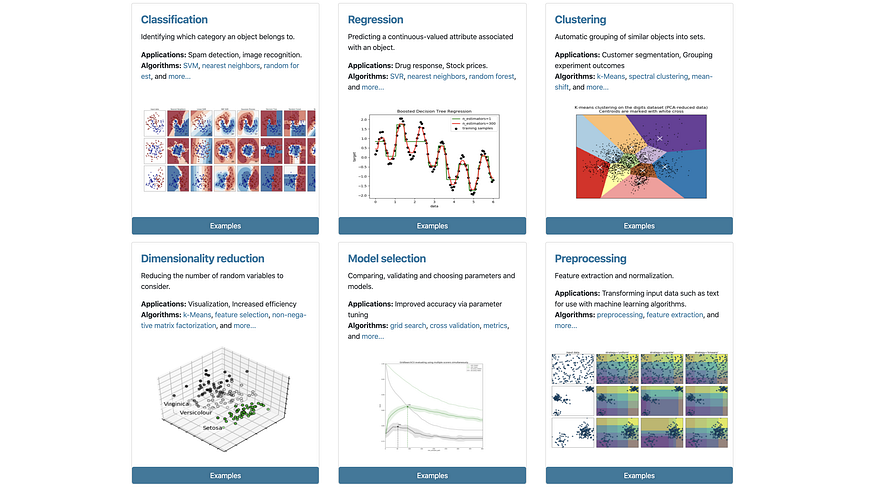
Use Cases for Scikit-Learn, Source.
Alternatives: none, period.
PyTorch (Deep Learning use cases)
An open-source machine learning library based on the Torch library. Given the Deep Learning focus, it’s mostly used for applications such as computer vision and natural language processing. It is primarily developed by Facebook’s AI Research lab (FAIR). Recently, many well-known AI research institutes, such as Open AI, are using PyTorch as their standard tool.
Alternatives: Tensorflow, Keras, Fast.ai
Open AI Gym (Reinforcement Learning use cases)
A toolkit for developing and comparing reinforcement learning algorithms. It offers API and visual environments. This is an active area the communities are building tools for. Not many well-packaged tools are available yet.
Alternatives: many small projects, but not many are as well maintained as the Gym.
5. The Stove: Experimentation Management
A free tool that allows data scientists to set up experiments with a few snippets and surface the results to a web-based dashboard.
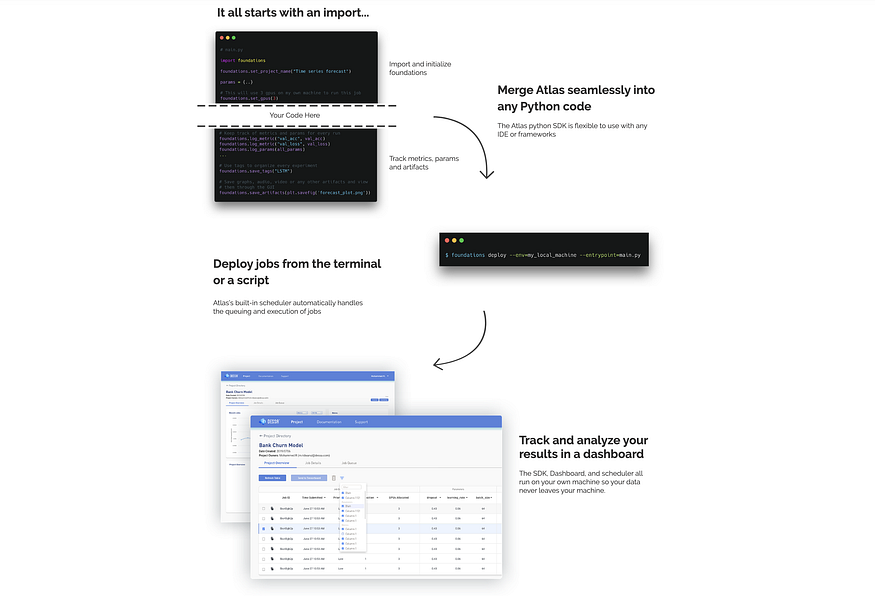
Atlas process, source.
Disclaimer: I worked at Dessa, the company that created Altas.
Alternatives: ML Flow, SageMaker, Comet, Weights & Biases, Data Robot, Domino
An Alternative View
As I mentioned, there is no perfect setup. It all depends on your needs and constraints. Here is another view of what tools are available and how they can work together.
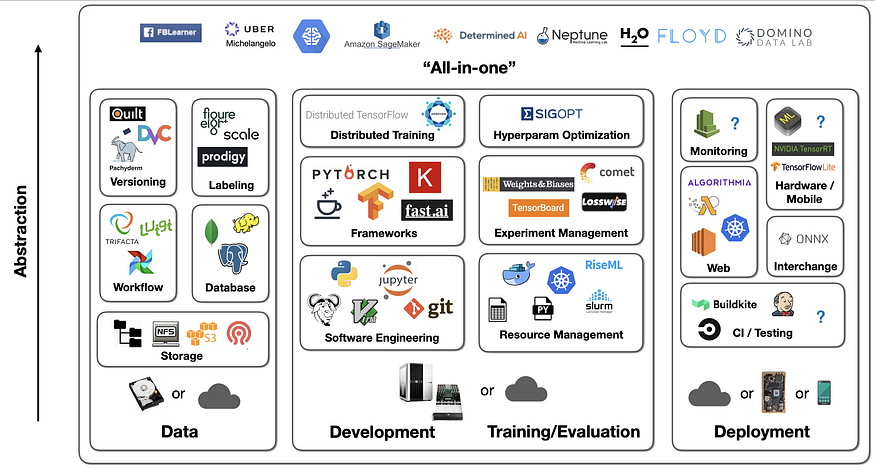
Presentation from Sergey Karayev at Full Stack Deep Learning, 2019.
Original. Reposted with permission.
Related: