How to use Machine Learning for Anomaly Detection and Conditional Monitoring
This article explains the goals of anomaly detection and outlines the approaches used to solve specific use cases for anomaly detection and condition monitoring.
By Michael Garbade, CEO & Founder, Education Ecosystem
Key Takeaways
- The main goal of Anomaly Detection analysis is to identify the observations that do not adhere to general patterns considered as normal behavior.
- Anomaly Detection could be useful in understanding data problems.
- There are domains where anomaly detection methods are quite effective.
- Modern ML tools include Isolation Forests and other similar methods, but you need to understand the basic concept for successful implementation
- Isolation Forests method is unsupervised outlier detection method with interpretable results.
Introduction
Before doing any data analysis, the need to find out any outliers in a dataset arises. These outliers are known as anomalies.
This article explains the goals of anomaly detection and outlines the approaches used to solve specific use cases for anomaly detection and condition monitoring.
What is Anomaly Detection? Practical use cases.
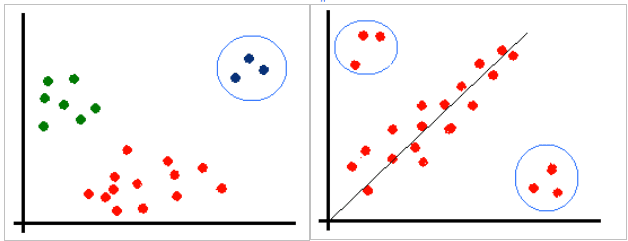
The main goal of Anomaly Detection analysis is to identify the observations that do not adhere to general patterns considered as normal behavior. For instance, Fig. 1 shows anomalies in the classification and regression problems. We can see that some values deviate from most examples.
There are two directions in data analysis that search for anomalies: outlier detection and novelty detection. So, the outlier is the observation that differs from other data points in the train dataset. The novelty data point also differs from other observations in the dataset, but unlike outliers, novelty points appear in the test dataset and usually absent in the train dataset. Hence, there are outliers in Fig. 1.
The most common reason for the outliers are;
- data errors (measurement inaccuracies, rounding, incorrect writing, etc.);
- noise data points;
- hidden patterns in the dataset (fraud or attack requests).
So outlier processing depends on the nature of the data and the domain. Noise data points should be filtered (noise removal); data errors should be corrected. Some applications focus on anomaly selection, and we consider some applications further.
There are various business use cases where anomaly detection is useful. For instance, Intrusion Detection Systems (IDS) are based on anomaly detection. Figure 2 shows the observed distribution of the NSL-KDD dataset that is a state of the art dataset for IDS. We can see that most observations are the normal requests, and Probe or U2R are some outliers. Naturally, the majority of requests in the computer system are normal, and only some of them are attack attempts.

The Credit Card Fraud Detection Systems (CCFDS) is another use case for anomaly detection. For example, the open dataset from kaggle.com (https://www.kaggle.com/mlg-ulb/creditcardfraud) contains transactions made by credit cards in September 2013 by European cardholders. This dataset presents transactions that occurred in two days. There are 492 frauds out of 284,807 transactions. The dataset is highly unbalanced. The positive class (frauds) account for 0.172% of all transactions.
There are two approaches to anomaly detection:
- Supervised methods;
- Unsupervised methods.
In supervised anomaly detection methods, the dataset has labels for normal and anomaly observations or data points. IDS and CCFDS datasets are appropriate for supervised methods. Standard machine learning methods are used in these use cases. Supervised anomaly detection is a sort of binary classification problem. It should be noted that the datasets for anomaly detection problems are quite imbalanced. So it's important to use some data augmentation procedure (k-nearest neighbors algorithm, ADASYN, SMOTE, random sampling, etc.) before using supervised classification methods. Jordan Sweeney shows how to use the k-nearest algorithm in a project on Education Ecosystem, Travelling Salesman - Nearest Neighbour.
Unsupervised anomaly detection is useful when there is no information about anomalies and related patterns. Isolation Forests, OneClassSVM, or k-means methods are used in this case. The main idea here is to divide all observations into several clusters and to analyze the structure and size of these clusters.
There are different open datasets for outlier detection methods testing, for instance, Outlier Detection DataSets (http://odds.cs.stonybrook.edu/).
Unsupervised Anomaly Detection using Isolation Forests
Isolation Forests method is based on the random implementation of the Decision Trees and other results ensemble. Each Decision Tree is built until the train dataset is exhausted. A random feature and a random splitting are selected to build the new branch in the Decision Tree. The algorithm separates normal points from outliers by the mean value of the depths of the Decision Tree leaves. This method is implemented in the scikit-learn library (https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.IsolationForest.html).
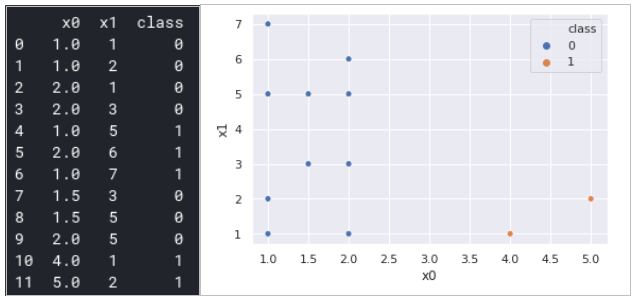
In order to illustrate anomaly detection methods, let's consider some toy datasets with outliers that have been shown in Fig. 3. Points with class 1 are outliers. Column' class' isn't used in the analysis but is present just for illustration.
Lets apply Isolation Forests for this toy example with further testing on some toy test dataset. The results are shown in Fig. 4. The full code is present here: https://www.kaggle.com/avk256/anomaly-detection.

It should be noted that ‘y_train’ and ‘y_test’ columns are not in the method fitting. So, the Isolation Forests method uses only data points and determines outliers. Hence, ‘X_test’ dataset consists of two normal points and two outliers and after the prediction method we obtain exactly equal distribution into two clusters.
Conclusion
In a nutshell, anomaly detection methods could be used in branch applications, e.g., data cleaning from the noise data points and observations mistakes. On the other hand, anomaly detection methods could be helpful in business applications such as Intrusion Detection or Credit Card Fraud Detection Systems. Andrey demonstrates in his project, Machine Learning Model: Python Sklearn & Keras on Education Ecosystem, that the Isolation Forests method is one of the simplest and effective for unsupervised anomaly detection. In addition, this method is implemented in the state-of-the-art library Scikit-learn.
Bio: Michael Garbade is CEO & Founder, Education Ecosystem Michael is a forward-thinking, global, serial entrepreneur with expertise in software development, backend architecture, data science, artificial intelligence, fintech, blockchain, and venture capital. He combines experience with tech, data, finance and business development with an impressive educational background and a talent for identifying new business models. As co-founder and CEO of Education Ecosystem, his mission is to build the world’s largest decentralized learning ecosystem for professional developers and college students. He writes subject matter expert technical and business articles in leading blogs like Opensource.com, Dzone.com, Cybrary, Businessinsider, Entrepreneur.com, TechinAsia, Coindesk and Cointelegraph.
Related:
- Anomaly Detection, A Key Task for AI and Machine Learning, Explained
- Introducing MIDAS: A New Baseline for Anomaly Detection in Graphs
- Introduction to Anomaly Detection