
 Introducing MIDAS: A New Baseline for Anomaly Detection in Graphs
Introducing MIDAS: A New Baseline for Anomaly Detection in Graphs

 Introducing MIDAS: A New Baseline for Anomaly Detection in Graphs
Introducing MIDAS: A New Baseline for Anomaly Detection in GraphsFrom network security to financial fraud, anomaly detection helps protect businesses, individuals, and online communities. To help improve anomaly detection, researchers have developed a new approach called MIDAS.
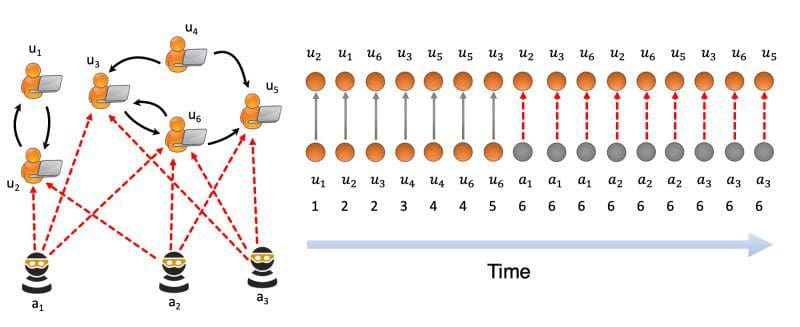
In machine learning, hot topics such as autonomous vehicles, GANs, and face recognition often take up most of the media spotlight. However, another equally important issue that data scientists are working to solve is anomaly detection. From network security to financial fraud, anomaly detection helps protect businesses, individuals, and online communities. To help improve anomaly detection, researchers have developed a new approach called MIDAS.
What is MIDAS?
At the National University of Singapore, PhD candidate Siddharth Bhatia and his team have developed MIDAS, a new approach to anomaly detection that outperforms baseline approaches both in speed and accuracy.

MIDAS stands for Microcluster-Based Detector of Anomalies in Edge Streams. As the name suggests, MIDAS detects microcluster anomalies or sudden groups of suspiciously similar edges in graphs. One of the main benefits of MIDAS is its ability to detect these anomalies in real time, at a speed many times greater than existing state-of-the-art models.
Real-world Use Cases of Anomaly Detection in Graphs
Put simply, anomaly detection is the practice of finding patterns or outliers that deviate from what you expect to see in a dataset. It can help us find and eliminate harmful content. “Anomaly detection in graphs is a critical problem for finding suspicious behavior in countless systems,” says Siddharth. “Some of these systems include intrusion detection, fake ratings, and financial fraud.”

This technology can help social networks like Twitter and Facebook detect fake profiles used for spam and phishing. It can even be used to help investigators identify online sexual predators. “Using MIDAS, we can find anomalous edges and nodes in a dynamic (time-evolving) graph,” says Siddharth. “In Twitter and Facebook, tweet and message networks can be considered a time-evolving graph and we can find the malicious messages and fake profiles by finding the anomalous edges and nodes in these graphs.”
Some other common use cases of anomaly detection include:
- Spam Filters
- Credit Card Fraud Detection
- Dataset Preprocessing
- Network Security
- Social Media Content Moderation
MIDAS Outperforms State-of-the-Art Approaches
“Anomaly detection is a well-researched problem with the majority of the proposed approaches focusing on static graphs,” says Siddharth. “However, many real-world graphs are dynamic in nature, and methods based on static connections may miss temporal characteristics of the graphs and anomalies.”
MIDAS addresses the need to detect anomalies in real-time, in order to start recovery as soon as possible and lessen the effects of malicious activities, such as fraudulent credit card purchases.
“In addition, since the number of vertices can increase as we process the stream of edges, we need an algorithm which uses constant memory in graph size,” Siddharth explains. “Moreover, fraudulent or anomalous events in many applications occur in microclusters or suddenly arriving groups of suspiciously similar edges, e.g. denial of service attacks in network traffic data and lockstep behavior.”
“By using a principled hypothesis testing framework,” says Siddharth. “MIDAS provides theoretical bounds on the false positive probability, which earlier methods do not provide.”
How was Midas tested?
Siddharth and his colleagues demonstrated the potential of MIDAS in social network security and intrusion detection tasks. They used the following datasets for anomaly detection:
- Darpa Intrusion Detection (4.5 million IP-IP communications)
- Twitter Security Dataset (2.6 million tweets related to security events in 2014)
- Twitter World Cup Dataset (1.7 million tweets during Soccer World Cup in 2014)
To compare the performance of MIDAS, the team looked at the following baselines:
- RHSS
- SEDANSPOT
However, since RHSS had a low AUC measure of 0.17 on the Darpa dataset, the team measured accuracy, running time, and real-world effectiveness by comparing against SEDANSPOT.
The Results
MIDAS detects microcluster anomalies up to 48% more accurately and as much as 644 times faster than current baseline approaches.
“Our experimental results show that MIDAS outperforms baseline approaches by 42%-48% accuracy (in terms of AUC),” says Siddharth. “Furthermore, MIDAS processes the data 162−644 times faster than baseline approaches.
Improving MIDAS: Future Work
“We have extended MIDAS to M-Stream: Fast Streaming Multi-Aspect Group Anomaly Detection,” says Siddharth. “In M-Stream, we detect anomalies on multi-aspect data having both categorical and numeric attributes.”
Siddharth and his team say that M-Stream also outperforms several baselines including popular Sklearn algorithms like Isolation Forest and Local Outlier Factor in terms of both accuracy and running time. However, their work with M-Stream is currently under review.
“Considering the performance of MIDAS, we think it will become a new baseline approach and be quite useful for Anomaly Detection,” says Siddharth. “Also, it will be interesting to explore how MIDAS can contribute in other applications.”
If you’re interested in learning more about MIDAS, check out Siddharth’s full paper. You can also download the code and datasets on Github.
For more machine learning interviews, guides, and news, check out the related resources below and don’t forget to subscribe to our newsletter.
Bio: Limarc Ambalina is a Tokyo-based writer specializing in AI, tech, and pop culture. He has written for numerous publications including Hacker Noon, Japan Today, and Towards Data Science.
Original. Reposted with permission.
Related:
- Graph Neural Network model calibration for trusted predictions
- Anomaly Detection, A Key Task for AI and Machine Learning, Explained
- What is Benford’s Law and why is it important for data science?