 Data Engineering — the Cousin of Data Science, is Troublesome
Data Engineering — the Cousin of Data Science, is Troublesome
 Data Engineering — the Cousin of Data Science, is Troublesome
Data Engineering — the Cousin of Data Science, is TroublesomeA Data Scientist must be a jack of many, many trades. Especially when working in broader teams, understanding the roles of others, such as data engineering, can help you validate progress and be aware of potential pitfalls. So, how can you convince your analysts to realize the importance of expanding their toolkit? Examples from real life often provide great insight.
By Lissie Mei, Data Scientist at Visa.
We always deem data science as the “sexiest job of the 21st century.” When it comes to the transformation from a traditional company to an analytical company, either the company or the data scientists would expect to dive into the fancy world of analytics as soon as possible. But, is it always the case?
A troublesome start
Ever since we, a Practicum team from UC Davis, started the collaboration with Hilti, a leading manufacturing company in power tools and related services, we had provisioned several splendid blueprints: automation of pricing, propensity model…Working with such a great company was such a precious opportunity for us that we could barely wait to exploit our analytical skills to create business value. But when we started to tap into the data, we found that it is hard for us to directly acquire clean and structured data from a traditional company, as compared to from a data-driven company such as e-commerce companies.
As I was mainly responsible for the data cleaning and engineering of the project, I witnessed how we were hindered in the analytical progress due to the unready data.

I witnessed how we were hindered in the analytical progress due to the unready data.
We were directly working with the finance team, but the other team, pricing operations, was actually taking charge of the database. In the beginning, the process was heavily lagged because we could barely request and inquire about the data or people in time. Moreover, as the sales data of Hilti was sensitive and the company lacked a secure way to transfer data, a time-consuming masking process was needed upon every request of data. Thirdly, weak data engineering led to the inconsistency among several referring tables, and we could barely proceed with a solid model or conclusion. Finally, we have to deal with various data types: CSV, JSON, SQLite, etc…Indeed a good chance to learn, though.
After around two months, we got all the data ready, and every anomaly case was discussed and solved.
Diving time!
Our well-developed frames of visualizations and models couldn’t wait to have a taste of the fresh data. However, the most embarrassing thing happened when we were presenting the first proposal with actual figures.

Guess what? The big numbers didn’t seem to match. After a quick discussion, we realized that we didn’t receive the complete data at all. We were only focusing on the detail of data, such as anomalies and relationships among data sources, but we forgot to do the basic checks such as sum and count. This is a lesson that I would remember for a lifetime. Truly!
Why data engineering is so important
The most important thing that I learned from the data engineering drama is that the kind of roles working behind the scene, such as data engineers, are actually holding the gateway of innovation. When a traditional company considers exploiting their data, the most efficient and first-step action should be improving the data engineering process. With good data engineers, the company can build a healthy and scalable data pipeline making it much easier for data analysts to carry out data mining and finding business insights.
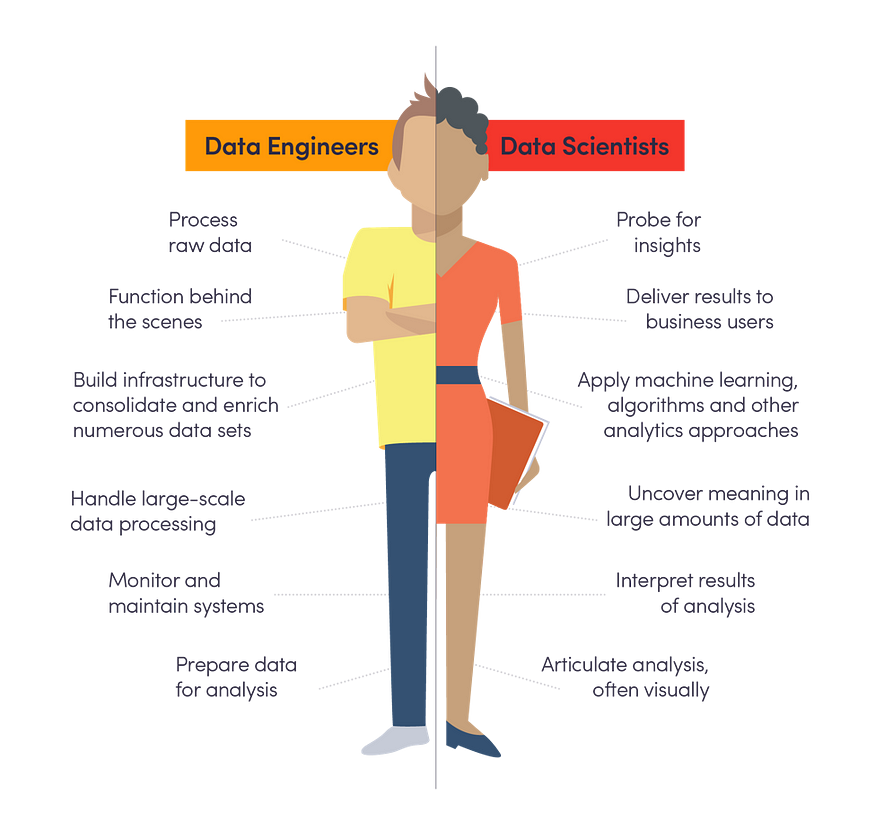
I also learned that why a lot of companies require their data analysts to have knowledge in programming related tools, such as Python and Scala, apart from analytics tools such as SQL and Excel. Usually, we cannot expect a “full-stack” analyst, but it is necessary that we have someone who can communicate with both engineering people and management people. Although a clear allocation of work is important for high efficiency, a guru of every data tool is indeed attractive.

Full-stack… makes sense!
What I am expecting myself to learn in the future is the knowledge of both the front side and the backside, such as Java, JavaScript, Kafka, Spark, and Hive, and I believe eventually, they would be the sparkling point in my experience.
Original. Reposted with permission.
Related: