 Building a Deep Learning Based Reverse Image Search
Building a Deep Learning Based Reverse Image Search
 Building a Deep Learning Based Reverse Image Search
Building a Deep Learning Based Reverse Image SearchFollowing the journey from unstructured data to content based image retrieval.
Ever wondered how the Google reverse image search works, which take in an image and returns you the most similar images in a fraction of a second?
For humans, evaluating the content of images is fairly straight forward, and determining whether an image contains a car, cat or a house does not require much effort. However, imagine you have a database with 100.000 images (or more), without any metadata or structure. With lack of any relevant metadata about the image content, how can you extract any useful information without having to manually scroll through all your images? Fortunately, techniques from both classical computer vision and recent developments within deep learning comes to the rescue.
One important application within content based image retrieval is the so called “reverse image search”. This is the application of computer vision techniques to the image retrieval problem, that is, the problem of searching for images in large databases. “Content-based” means that the search analyzes the content of the image rather than the metadata such as keywords, tags, or descriptions associated with the image.
Having a large database of images with no available metadata is not an ideal starting point, but unfortunately this is actually quite a common scenario. Fortunately, we can make use of many of the same techniques as the aforementioned “reverse image search” by Google to build our own custom image matching application.
Deep learning and image classification
Examples you have probably seen before could e.g. be the typical “cat vs. dog” classification models, discussed in an abundance of blogs and tutorials online. However, most of these examples are based on having access to a significant amount of labelled images, where you have the “ground truth” information available for training your model. In our case, this is not really what we are looking for, as we do not have any such information available. Luckily, we can still make use of openly available deep learning models trained on other datasets.
Access to models that have already been trained on vast amounts of data (e.g. the popular ImagNet dataset, containing millions of annotated images), is one of the reasons why it has become much easier to build state-of-the-art deep learning applications. Using such pre-trained models as a basis, one can often sucessfully make use of transfer-learning techniques to adapt the model to our specific needs, even with very limited amounts of data (or no data at all).
In our case, when it comes to making sense of a database of unstructured images, we can actually get a lot of valuable insight without any labeled training images at all. This is because of how these deep learning models actually analyze image content, based on automatically extracting relevant “features” of the image.
A deep learning model trained on a large set of labelled images have basically become an automatic “feature extractor”. This means that when analyzing our images, we basically get as output a “feature vector” which contains relevant information about the image content. Even if we have not trained our model to classify this output into a distinct set of categories/classes, we can still extract a lot of valuable information.
Neural network as a feature extractor
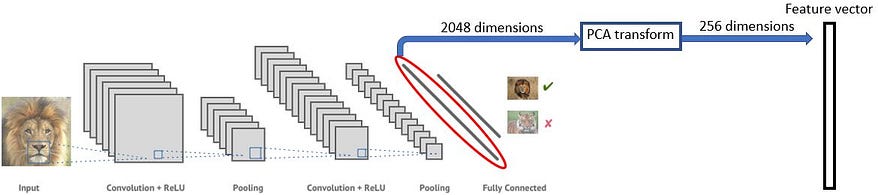
- A neural network image classifier works through converting images (which are points in high-dimensional pixel space) to low dimensional “feature vectors” representing characteristic “features” learned by the network (as illustrated in the figure below)
- We can then take a trained neural network, remove its last high-level layers originally used to classify objects, and use the dissected model to convert our images into feature vectors.

This feature vector representation of the image can still contain some “noise” and redundant information. To filter out the most important information (and also speed up the image retrieval and analysis process), we compress the data further based on a principal component analysis. In doing so, we here compress the feature vector from 2048 to 256 dimensions. (note that the dimensionality depends on your choice of neural network as feature extractor).
Similarity metric: Cosine Similarity
After converting our images to feature vectors, we then need some kind of similarity metric to compare them. One such candidate, and the one used in this example, is the “cosine similarity”. Essentially, this measures the “angle” between images in the high dimensional feature space. This is illustrated in a very simplified version below for a two dimensional feature space, comparing the cosine similarity between the input image and images “A”/“B”. We here see that “A” contains similar objects as the input image (and hence a smaller “angle” between them), whereas “B” contains different looking objects (and correspondingly has a larger angle).
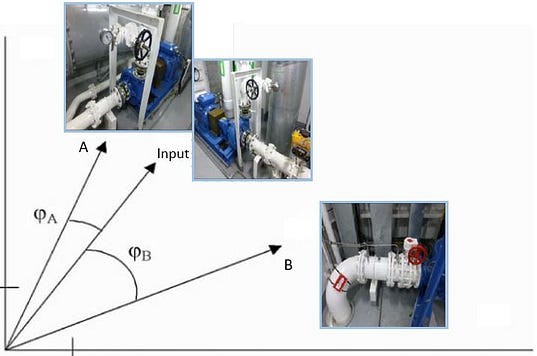
Image clustering
By processing the images in our database through our “feature extraction model”, we can convert all images to a feature vector representation. This means we now have a quantitative description in terms of image content. Having this information, we can e.g. pass these vectors through a clustering algorithm, which will assign the images to various clusters based on their content. In doing this, we still do not know what the individual images contain, but we know that the images within the various clusters typically contain similar objects/content.
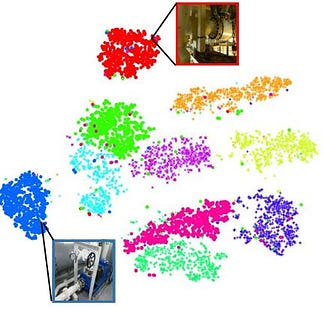
One application of this technique could e.g. be as a preliminary step towards defining a training set for supervised image classification models. By clustering all images, and inspecting a few of the images from each cluster, we can then assign a label to all images in the cluster. In doing this, we have effectively labelled all of our images just by looking at a few examples from each cluster. Compared to manually scrolling through and annotating 100.000 images this is clearly an improvement. That said, automatically assigning the same label to all images within each of the clusters will probably cause some mislabeling. Nevertheless, it still represents a good starting point for a more detailed analysis.
Reverse image search for industrial applications
Another key application is that of “reverse image search”, which is the main topic of this article. Let`s say we want to analyze a “target image”, and then search our database for similar content. For example, this could e.g. be a database of images from previous maintenance work or inspections in a manufacturing/production plant. We might then be interested in finding images of similar objects, or perhaps all the historical inspection images of a specific piece of equipment.
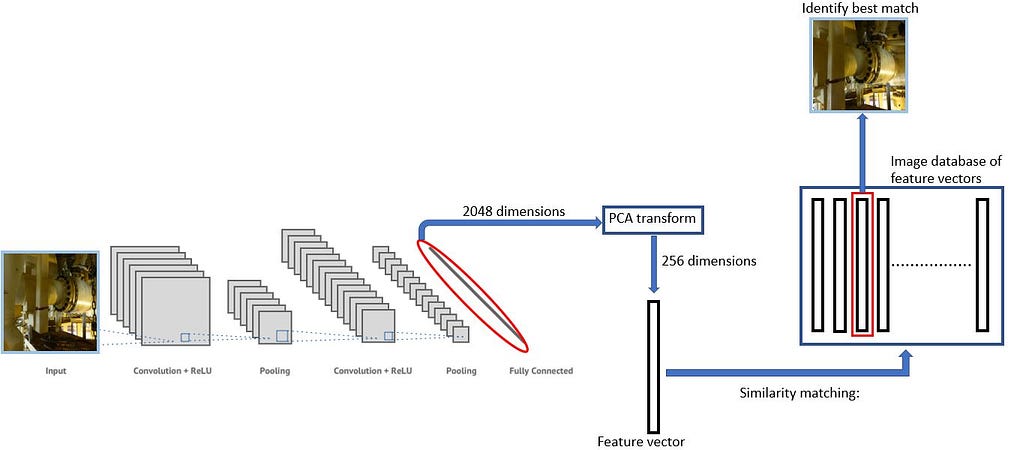
What we can then do, is to first convert our target image into a feature vector representation by processing it through our “feature extractor model”. Having done this, we can then perform a similarity search through our database of feature vectors.
Matching images: Step-by-step
- Preparing image database: Convert the image database into a feature vector representation using our neural network model, followed by a principal component transformation.
- Analyze new target image: Convert the image to a low-dimensional feature vector using the same pipeline as described above.
- Find matching images: Compute similarity between feature vectors using the cosine similarity. Use similarity metric to match images from the database which are most similar to the target image.
Summary:
Ideally, a database of images should of course already be structured with the neccesary metadata to perform such a search in the first place. However, there are actually many real-world examples where this is not the case. Fortunately, as illustrated through the example case above, all hope is not lost. Even from messy and unstructured data, one can still extract valuable insights.
This article is not intended to be a technological deepdive into the complexities of implementing such a solution in practice, but I hope it at least gives you a basic idea of the functionality and possibilities that these technologies can offer.
I believe it is important to emphasize that deep learning is not only applicable for companies having access to huge amounts of high quality labeled data. As illustrated through the example above, even with no labeled data at all, you can still utilize the underlying technologies to extract valuable insights from your data.
In case you are interested in learning more about topics related to AI/Machine Learning and Data Science, you can also have a look at some of the other articles I have written. You will find all of them listed on my medium author profile, which you can find here.
- What is Graph theory, and why should you care?
- Deep Transfer Learning for Image Classification
- Building an AI that can read your mind
- The hidden risk of AI and Big Data
- How to use machine learning for anomaly detection and condition monitoring
- How (not) to use Machine Learning for time series forecasting: Avoiding the pitfalls
- How to use machine learning for production optimization: Using data to improve performance
- How do you teach physics to AI systems?
- Can we build artificial brain networks using nanoscale magnets?
- Artificial Intelligence in Supply Chain Management: Utilizing data to drive operational performance
I also discuss various topics related to AI/machine learning in the workshop presentation below: “From hype to real-world applications”. I hope you found these resources interesting and useful! Any feedback and input in the comments below is of course always welcome.
Bio: Vegard Flovik is working on machine learning and advanced analytics at Kongsberg Digital.
Original. Reposted with permission.
Related:
- Build Dog Breeds Classifier Step By Step with AWS Sagemaker
- Deep Learning for Detecting Pneumonia from X-ray Images
- How to Create Custom Real-time Plots in Deep Learning