MLOps: Model Monitoring 101
Model monitoring using a model metric stack is essential to put a feedback loop from a deployed ML model back to the model building stage so that ML models can constantly improve themselves under different scenarios.
By Pronojit Saha and Dr. Arnab Bose, Abzooba

Background
ML models are driving some of the most important decisions for businesses. As such it is important that these models remain relevant in the context of the most recent data, once deployed into production. A model may go out of context if there is data skew i.e. data distribution may have changed in production from what was used during training. It may also be that a feature becomes unavailable in production data or that the model may no longer be relevant as the real-world environment might have changed (e.g. Covid19) or further and more simply, the user behavior may have changed. Monitoring the changes in model’s behavior and the characteristics of the most recent data used at inference is thus of utmost importance. This ensures that the model remains relevant and/or true to the desired performance as promised during the model training phase.
An instance of such a model monitoring framework is illustrated in Fig 2 below. The objective is to track models on various metrics, the details of which we will get into the next sections. But first, let us understand the motivation of a model monitoring framework.

Motivation
Feedback loops play an important role in all aspects of life as well as business. Feedback loops are simple to understand: you produce something, measure information on the production, and use that information to improve production. It’s a constant cycle of monitoring and improvement. Anything that has measurable information and room for improvement can incorporate a feedback loop and ML models can certainly benefit from them.
A typical ML workflow includes steps like data ingestion, pre-processing, model building & evaluation, and finally deployment. However, this lacks one key aspect i.e. feedback. The primary motivation of any “model monitoring” framework thus is to create this all-important feedback loop post-deployment back to the model building phase (as depicted in Fig 1). This helps the ML model to constantly improve itself by deciding to either update the model or continue with the existing model. To enable this decision the framework should track & report various model metrics (details in “Metrics” section later) under two possible scenarios described below.
- Scenario I: The training data is available and the framework computes the said model metrics both on training data and production (inference) data post-deployment and compares to make a decision.
- Scenario II: The training data is not available and the framework computes the said model metrics based only on the data that is available post-deployment.
The following table lists the inputs required by the model monitoring framework to generate the said metrics, under the two scenarios.
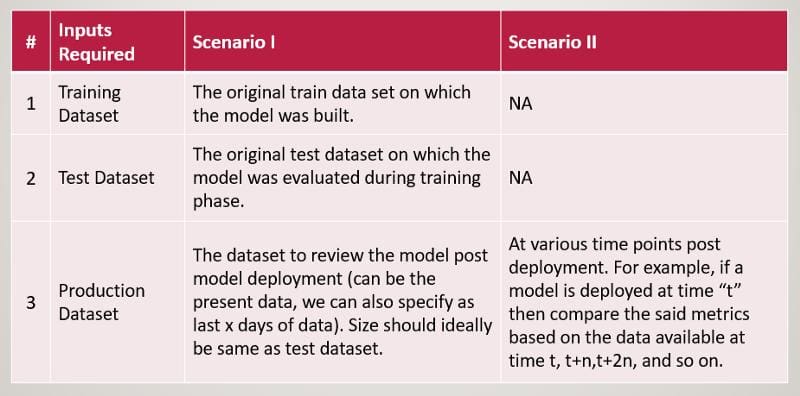
Based on which of the two scenarios is applicable, metrics highlighted in the next section are computed to decide if a model in production needs an update or some other interventions.
Metrics
A proposed model monitoring metrics stack is given in Fig 3 below. It defines three broad types of metrics based on the dependency of the metric on data and/or ML model. A monitoring framework should ideally consist of one or two metrics from all three categories, but if there are tradeoff then one may build up from the base i.e. starting with operations metrics and then building up with the maturity of the model. Further, operations metrics should be monitored at a more real time level or at-least daily where stability and performance can be at a weekly or even a larger time frame depending on the domain & business scenario.

1. Stability Metrics — These metrics help us to capture two types of data distribution shifts:
a) Prior Probability Shift — Captures the distribution shift of the predicted outputs and/or dependent variable between either the training data and production data (scenario I) or various time frames of the production data (scenario II). Examples of these metrics include Population Stability Index (PSI), Divergence Index (Concept Shift), Error Statistic (details & definition to follow in next article of this series)
b) Covariate Shift — Captures the distribution shift of each independent variable between either the training data and production data (scenario I) or various time frames of the production data (scenario II), as applicable. Examples of these metrics include Characteristic Stability Index (CSI) & Novelty Index (details & definition to follow in the next article of this series)
2. Performance Metrics — These metrics help us to detect a concept shift in data i.e. identify whether the relation between independent & dependent variables has changed (e.g. post-COVID the way users purchase during festivals may have changed). They do so by examining how good or bad the existing deployed model is performing viz-a-viz when it was trained (scenario I) or during a previous time frame post-deployment (scenario II). Accordingly, a decision can be taken to re-work the deployed model or not. Examples of these metrics include,
a) Project Metrics like RMSE, R-Square, etc for regression and accuracy, AUC-ROC, etc for classification.
b) Gini and KS -Statistics: A statistical measure of how well the predicted probabilities/classes are separated (only for classification models)
3. Operations Metrics — These metrics help us to determine how the deployed model is performing from a usage point of view. They are as such independent of model type, data & don’t require any inputs as with the above two metrics. Examples of these metrics include,
a. # of time ML API endpoints called in the past
b. Latency when calling ML API endpoints
c. IO/Memory/CPU usage when performing prediction
d. System uptime
e. Disk utilization
Conclusion
Model monitoring within the realm of MLOps has become a necessity for mature ML systems. It is quintessential to implement such a framework to ensure consistency and robustness of the ML system, as without it ML systems may lose the “trust” of the end-user, which could be fatal. As such including and planning for it in the overall solution architecture of any ML use case implementation is of utmost importance.
In the next blogs of the series, we will get into more details of the two most important model monitoring metric i.e. Stability & Performance metrics and we will see how we can use them to build our model monitoring framework.
References
- D. Sato, A. Wider, C. Windheuser, Continuous Delivery for Machine Learning (2019), martinflower.com
- M. Stewart, Understanding Dataset Shift (2019), towardsdatascience.com
Pronojit Saha is an AI practitioner with extensive experience in solving business problems, architecting, and building end-to-end ML driven products & solutions by leading and facilitating cross-functional teams. He is currently the Advanced Analytics Practice Lead at Abzooba, wherein apart from project execution he also engages in leading & growing the Practice by nurturing talent, building thought leadership, and enabling scalable processes. Pronojit has worked in the retail, healthcare, and Industry 4.0 domains. Time series analytics and natural language processing are his expertise and he has applied these along with other AI methodologies for use cases like price optimization, readmission prediction, predictive maintenance, aspect-based sentiment analytics, entity recognition, topic modeling, among others.
Dr. Arnab Bose is Chief Scientific Officer at Abzooba, a data analytics company and an adjunct faculty at the University of Chicago where he teaches Machine Learning and Predictive Analytics, Machine Learning Operations, Time Series Analysis and Forecasting, and Health Analytics in the Master of Science in Analytics program. He is a 20-year predictive analytics industry veteran who enjoys using unstructured and structured data to forecast and influence behavioral outcomes in healthcare, retail, finance, and transportation. His current focus areas include health risk stratification and chronic disease management using machine learning, and production deployment and monitoring of machine learning models.
Related:
- MLOps – “Why is it required?” and “What it is”?
- Model Experiments, Tracking and Registration using MLflow on Databricks
- Data Science Meets Devops: MLOps with Jupyter, Git, and Kubernetes