Working With Sparse Features In Machine Learning Models
Sparse features can cause problems like overfitting and suboptimal results in learning models, and understanding why this happens is crucial when developing models. Multiple methods, including dimensionality reduction, are available to overcome issues due to sparse features.

What are Sparse Features?
Features with sparse data are features that have mostly zero values. This is different from features with missing data. Examples of sparse features include vectors of one-hot-encoded words or counts of categorical data. On the other hand, features with dense data have predominantly non-zero values.
What is the Difference between Sparse Data and Missing Data?
When there is missing data, it means that many data points are unknown. On the other hand, if the data is sparse, all the data points are known, but most of them have zero value.
To illustrate this point, there are two types of features. The feature with sparse data has known values (= 0), but the feature with missing data has unknown values (= null). It is unknown what values should be in the null-valued rows.
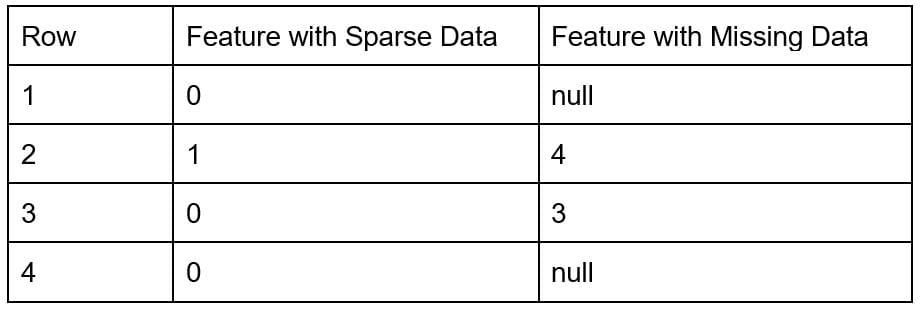
Table 1. Sample data with two types of features.
Why is Machine Learning Difficult with Sparse Features?
Common problems with sparse features include:
- If the model has many sparse features, it will increase the space and time complexity of models. Linear regression models will fit more coefficients, and tree-based models will have greater depth to account for all features.
- Model algorithms and diagnostic measures might behave in unknown ways if the features have sparse data. Kuss [2002] shows that goodness-of-fit tests are flawed when the data is sparse.
- If there are too many features, models fit the noise in the training data. This is called overfitting. When models overfit, they are unable to generalize to newer data when they are put in production. This negatively impacts the predictive power of models.
- Some models may underestimate the importance of sparse features and given preference to denser features even though the sparse features may have predictive power. Tree-based models are notorious for behaving like this. For example, random forests overpredict the importance of features that have more categories than those features that have fewer categories.
Methods for Dealing with Sparse Features
1. Removing features from the model
Sparse features can introduce noise, which the model picks up and increase the memory needs of the model. To remedy this, they can be dropped from the model. For example, rare words are removed from text mining models, or features with low variance are removed. However, sparse features that have important signals should not be removed in this process.
LASSO regularization can be used to decrease the number of features. Rule-based methods like setting a variance threshold for including features in the model might also be useful.
2. Make the features dense
- Principal component analysis (PCA): PCA methods can be used to project the features into the directions of the principal components and select from the most important components.
- Feature hashing: In feature hashing, sparse features can be binned into the desired number of output features using a hash function. Care must be taken to choose a generous number of output features to prevent hash collisions.
3. Using models that are robust to sparse features
Some versions of machine learning models are robust towards sparse data and may be used instead of changing the dimensionality of the data. For example, the entropy-weighted k-means algorithm is better suited to this problem than the regular k-means algorithm.
Conclusion
Sparse features are common in machine learning models, especially in the form of one-hot encoding. These features can result in issues in machine learning models like overfitting, inaccurate feature importances, and high variance. It is recommended that sparse features should be pre-processed by methods like feature hashing or removing the feature to reduce the negative impacts on the results.
Arushi Prakash, Ph.D., is an Applied Scientist at Amazon where she solves exciting science challenges in the field of workforce analytics. After obtaining a doctorate in Chemical Engineering, she transitioned to data science. She loves writing, speaking, and reading about science, career development, and leadership.