Using NLP to improve your Resume
This article discusses performing keyword matching and text analysis on job descriptions.
By David Moore, Specialist in Finance Technology implementation
Recruiters are using increasingly complicated Software and tools to scan and match Resumes to posted job positions and job specifications. If your Resume (CV) is generic, or the job specification is vague and/or generic, these tools will work against you. AI really is working against your job application, and I am not sure you know it or will accept it! But let me demonstrate some techniques that can help you balance up the odds. Naturally, we will use NLP (Natural Language Processing), Python, and some Altair visuals. Are you ready to fight back?
Consider that you are interested in a good position that you noticed online. How many others would have seen the same job? Have roughly the same experience and qualifications as you? How many applicants might have applied, do you think? Could it be less than 10 or less than 1,000?
Further, consider that the interview panel might be only 5 strong candidates. So how do you ‘weed’ out 995 applications to refine and deliver just 5 strong candidates? This is why I say you need to balance up the odds or be thrown out with the weeds!
Processing 1,000 Resumes (CV)
I suppose, first off, you could divide up those Resumes into a stack of 3 or 5. Print them off and assign them to human readers. Each reader provides one selection from their pile. With 5 readers that is a bunch of 200 Resumes — go pick the best one or two. Reading those would take a long time and probably only serve to yield an answer in the end. We can use Python to read all those Resumes in minutes!
Reading the article ‘How I used NLP (Spacy) to screen Data Science Resume’ here on Medium demonstrates that just two code lines will collect up the file names of those 1,000 Resumes.
#Function to read resumes from the folder one by one
mypath='D:/NLP_Resume/Candidate Resume'
onlyfiles = [os.path.join(mypath, f) for f in os.listdir(mypath)
if os.path.isfile(os.path.join(mypath, f))]The variable ‘onlyfiles’ is a Python list that contains the file names of all those Resumes got using the Python os library. If you study the article, you will also see how your resume can be ranked and eliminated almost automatically based on keyword analysis. Since we are trying to even up the odds, we need to focus on your desired job specification and your current resume. Do they match?
Matching the Resume and Job Description
To even up the odds, we want to scan a job description, the Resume, and measure the match. Ideally, we do it so that the output is useful to tune in the game for you.
Reading the documents
Since it is your Resume, you likely have that in either PDF or DOCX. There are Python modules available to read most data formats. Figure 1 demonstrates how to read the documents having saved the contents into a text file.
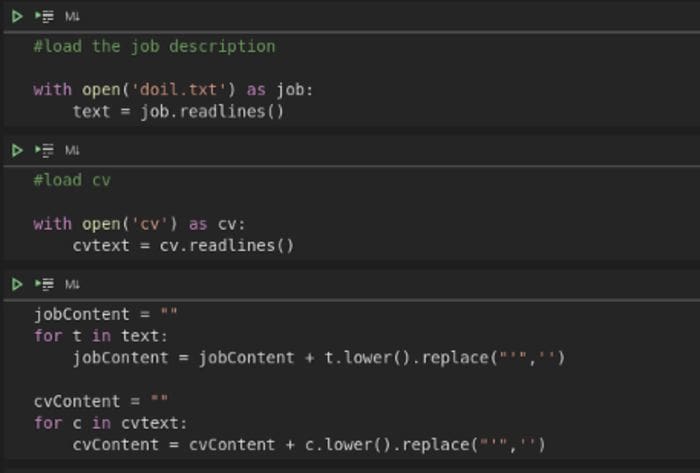
The first step is always to open the file and read the lines. The following step is to convert from a list of strings to a single text, doing some cleaning along the way. Figure 1 creates the variables ‘jobContent’, and ‘cvContent’ and these represent a string object that includes all the text. The next code snippet shows how to read a Word document directly.
import docx2txt
resume = docx2txt.process("DAVID MOORE.docx")
text_resume = str(resume)The variable ‘text_resume’ is a string object that holds all the text from the Resume, just like before. You can also use PyPDF2.
import PyPDF2Suffice it to say that a range of options exists for the practitioner to read the documents converting them to a clean treated text. Those documents could be extensive, hard to read, and frankly dull. You could start with a summary.
Processing the text
I love Gensim and use it frequently.
from gensim.summarization.summarizer import summarize
from gensim.summarization import keywordsWe created the variable ‘resume_text’ by reading a Word file. Let’s make a summary of the Resume and job posting.
print(summarize(text_resume, ratio=0.2))Gensim.summarization.summarizer.summarize will create a concise summary for you.
summarize(jobContent, ratio=0.2)Now you can read an overall summary of the job role and your existing Resume! Did you miss anything about the job role that is being highlighted in summary? Small nuanced details can help you sell yourself. Does your summarized document make sense and bring out your essential qualities?
Perhaps a concise summary alone is not sufficient. Next, let us measure how similar your Resume is to a job specification. Figure 2 provides the code.
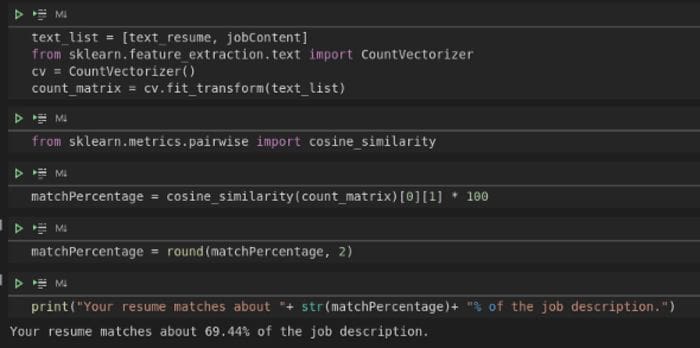
Broadly we make a list of our text objects then create an instance of the sklearn CountVectorizer() class. We also import the cosine_similarity metric, which helps us measure the similarity of the two documents. ‘Your resume matches about 69.44% of the job description’. That sounds wonderful, but I won’t get carried away. Now you can read a summary of the documents and get a similarity measurement. The odds are improving.
Next, we can look at the job description keywords and see which ones are matched in the Resume. Did we miss out on a few keywords that could strengthen the match towards 100%? Over to spacy now. It’s quite a journey so far. Gensim, sklearn and now spacy! I hope you aren’t dizzy!
from spacy.matcher import PhraseMatcher
matcher = PhraseMatcher(Spnlp.vocab)
from collections import Counter
from gensim.summarization import keywordsWe will use the PhraseMatcher feature of spacy to match critical phrases from the job description to the Resume. Gensim keywords can help to provide those phrases to match. Figure 3 shows how to run the match.
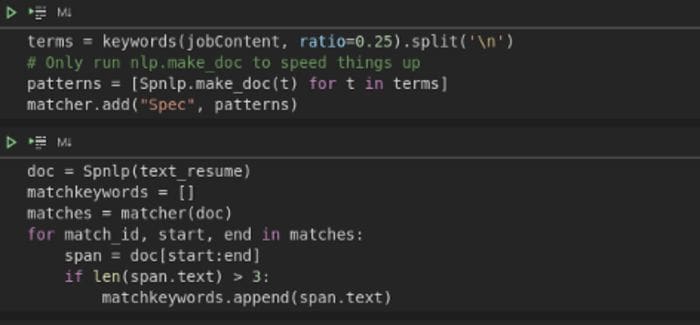
Using the snippet, in Figure 3, provides a list of matched keywords. Figure 4 shows a method to summarize those keyword matches. Using the Counter dictionary from Collections.

The term ‘reporting’ is contained in the job description, and the Resume has 3 hits. What phrases or keywords are in the job posting but aren’t on the CV (resume)? Could we add more? I used Pandas to answer this question — you can see the output in Figure 5.
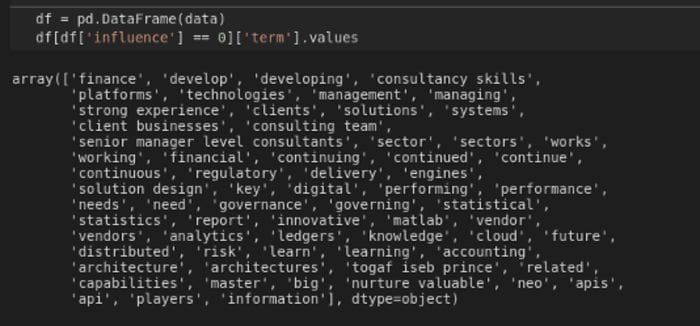
If this is true, it is also strange. The match was 69.44% at the document level but look at that long list of keywords that aren’t mentioned on the Resume. Figure 6 shows the keywords that are mentioned.
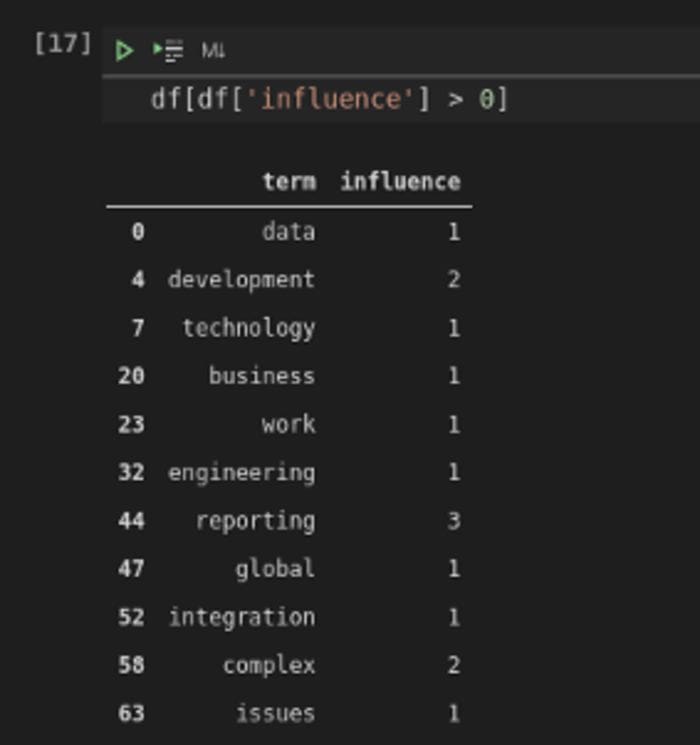
In reality, there are very few keyword matches against the job specification, which leads to my scepticism about the cosine similarity measure of 69.44%. Still, the odds are improving because we can see keywords in the job specification that aren’t in the Resume. Fewer keyword matches mean that you are more likely to wash out with the weeds. Looking at the missing keywords, you could go right ahead, strengthen the Resume, and re-run the analysis. Just peppering your resume with keywords will have a negative consequence, though, and you have to be extremely careful with your art. You might get through an initial automated screening, but you will be eliminated because of a perceived lack of writing skill. We really need to rank phrases and focus on the essential topics or words in the job specification.
Let’s look at ranked phrases next. For this exercise, I will use my own NLP class and some methods I used previously.
from nlp import nlp as nlp
LangProcessor = nlp()
keywordsJob = LangProcessor.keywords(jobContent)
keywordsCV = LangProcessor.keywords(cvContent)Using my own class, I recovered the ranked phrases from the job and Resume objects we created earlier. The snippet below provides you with the method definition. We are now using the rake module to extract ranked_phrases and scores.
def keywords(self, text):
keyword = {}
self.rake.extract_keywords_from_text(text)
keyword['ranked phrases'] = self.rake.get_ranked_phrases_with_scores()
return keywordFigure 7 provides an illustration of the output of the method call.
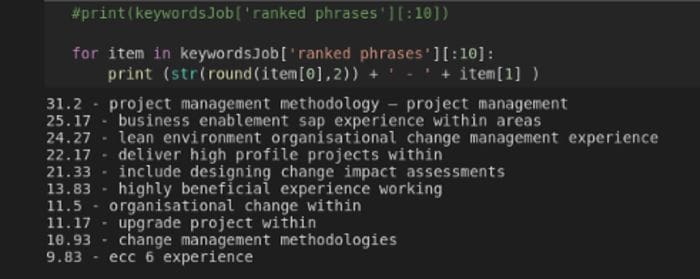
‘project management methodology — project management’ is ranked as 31.2, so this is the most crucial topic in the job posting. The critical phrases in the Resume can also be printed with a minor variation.
for item in keywordsCV['ranked phrases'][:10]:
print (str(round(item[0],2)) + ' - ' + item[1] )Reading the top phrases from both the Resume and the job posting, we can ask ourselves is there a match or the degree of the similarity? We can certainly run a sequence to find out! The following code creates a cross-reference between the ranked phrases on the job posting and from the Resume.
sims = []
phrases = []
for key in keywordsJob['ranked phrases']:
rec={}
rec['importance'] = key[0]
texts = key[1] sims=[]
avg_sim=0
for cvkey in keywordsCV['ranked phrases']:
cvtext = cvkey[1]
sims.append(fuzz.ratio(texts, cvtext))
#sims.append(lev.ratio(texts.lower(),cvtext.lower()))
#sims.append(jaccard_similarity(texts,cvtext)) count=0
for s in sims:
count=count+s
avg_sim = count/len(sims)
rec['similarity'] = avg_sim
rec['text'] = texts
phrases.append(rec)Note that we are using fuzzy-wuzzy as the match engine. The code also has a Levenshtein ratio and jaccard_similarity function. Figure 8 provides an illustration of what this can look like.
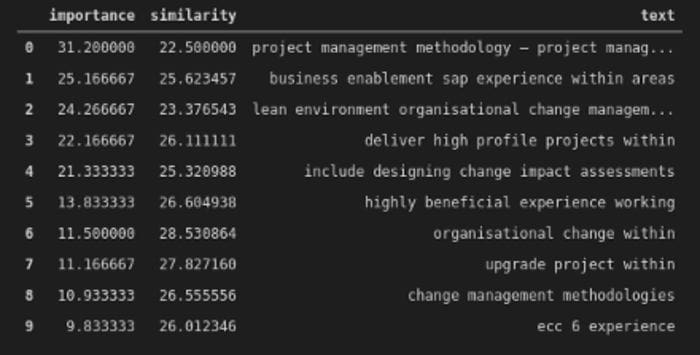
The ‘importance’ variable is the ranked phrase score from the resume. The ‘similarity’ variable is the ratio score from fuzzy-wuzzy. The term ‘project management methodology’ is ranked 31.2 but cross-referencing the rated Resume phrases only scores 22.5 on average. Whilst project management is the top priority for the job, the Resume scores more decisively on different technical items. You see how AI works against your application by doing a similar exercise.

Figure 9 shows another perspective. Working with tokens (words) shows each word’s importance in the job description versus the number of hits in the Resume — the more occurrences of a specific word in the document, the greater the influence. The phrase finance is of low importance to the job description but highly influential in the Resume. Is this a Finance guy looking for an IT job? Words can betray you with the AI!
I am sure by now that you have the picture. Using NLP tools and libraries can help to really understand a job description and measure the relative match. It certainly isn’t robust or gospel, but it does tend to even the odds. Your words matter, but you cannot pepper keywords in a Resume. You really have to write a strong resume and apply for roles that suit you. Text processing and text mining is a big topic, and we only scratch the surface of what can be done. I find text mining and text-based machine learning models to be deadly accurate. Let’s look at some visuals using Altair and then conclude.
Altair visuals
I have been using Altair a lot recently and much more so that Seaborn or Matplotlib. The grammar in Altair just clicks with me. I made three visuals to help with the discussion — figure 10 shows keyword importance and influence within the Resume. Using a colour scale, we can see that words like adoption appear twice in the CV but lower priority on the job posting.
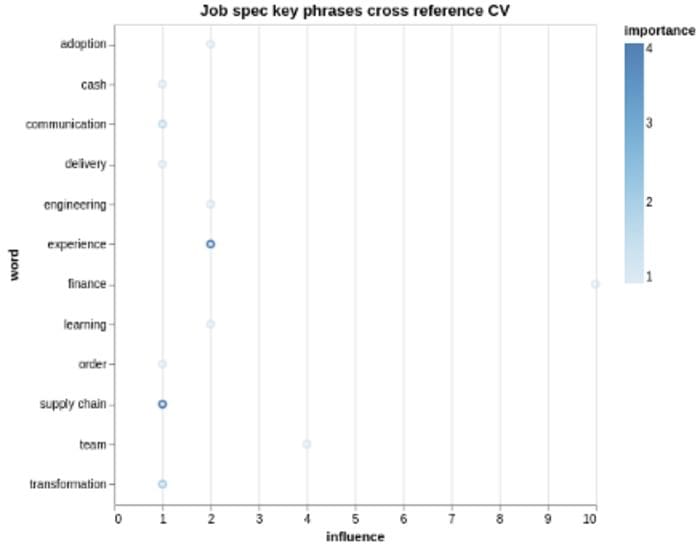
Figure 11 shows the cross-reference of ranked topics found on the job posting and those found on the Resume. The most important phrase is ‘project management..’ but that scores weakly in the ranked terms from the CV.
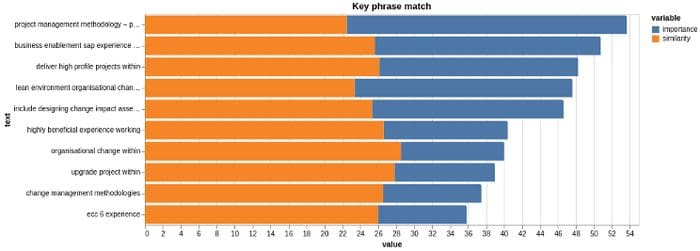
Figure 12 plots similar words. Finance is used 10 times on the Resume but not mentioned at all in the job posting. The word project is mentioned on the Resume(CV) and also appears in the job posting.
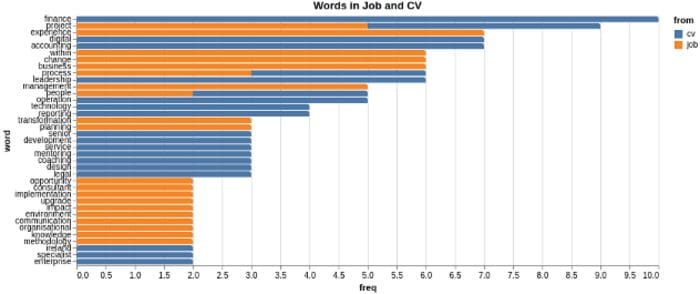
Looking at the charts, it seems to me that the Resume and job description are not a good match. Very few shared keywords and the ranked phrases look very different. This is what gets your resume washed out with the weeds!
Conclusion
Reading this article might seem more like a big-budget “shoot ’em dead CGI Hollywood” movie. All the big-name actors generally appear in those blockbusters. The big NLP libraries had a starring role in this article, and we even had cameo appearances by many more, perhaps older and more mature names such as NLTK. We used libraries such as Gensim, Spacy, sklearn and demonstrated their use. With my own class making a guest appearance, wrapping NLTK, rake, textblob and a heap of other modules, all performing and surfacing insights into text analytics,showing you how you could be separated from that opportunity to land your dream job.
Landing that dream job requires a clear and unrelenting focus on detail and careful preparation of the job application, the CV, and cover letter. Using Natural Language processing is not going to change you into the best overall candidate. That is up to you! But it can improve your chances of beating the early rounds powered by AI.

Every fisher man knows that you need good bait!
Bio: David Moore (@CognitiveDave) is a Specialist in Finance Technology implementation. David is interested in developing good Enterprise services that empower users, frees them from unnecessary work, and surfaces relevant insights.
Original. Reposted with permission.
Related:
- How to Get Data Science Interviews: Finding Jobs, Reaching Gatekeepers, and Getting Referrals
- Getting Started with 5 Essential Natural Language Processing Libraries
- 6 NLP Techniques Every Data Scientist Should Know