Awesome list of datasets in 100+ categories
With an estimated 44 zettabytes of data in existence in our digital world today and approximately 2.5 quintillion bytes of new data generated daily, there is a lot of data out there you could tap into for your data science projects. It's pretty hard to curate through such a massive universe of data, but this collection is a great start. Here, you can find data from cancer genomes to UFO reports, as well as years of air quality data to 200,000 jokes. Dive into this ocean of data to explore as you learn how to apply data science techniques or leverage your expertise to discover something new.
By Etienne D. Noumen, Senior Software Engineer.

Data science is an interdisciplinary field that uses scientific methods, processes, algorithms and systems to extract knowledge and insights from structured and unstructured data, and apply knowledge and actionable insights from data across a broad range of application domains.
In this blog, we provide links to popular open-source and public data sets, data visualizations, data analytics resources, and data lakes.
Table of Contents
- Latest complete Netflix movie dataset
- Common Crawl
- Dataset on protein prices
- CPOST dataset on suicide attacks over four decades
- Credit Card Dataset – Survey of Consumer Finances (SCF) Combined Extract Data 1989-2019
- Drone imagery with annotations for small object detection and tracking dataset
- NOAA High-Resolution Rapid Refresh (HRRR) Model
- Registry of Open Data on AWS
- Textbook Question Answering (TQA)
- Harmonized Cancer Datasets: Genomic Data Commons Data Portal
- The Cancer Genome Atlas
- Therapeutically Applicable Research to Generate Effective Treatments (TARGET)
- Genome Aggregation Database (gnomAD)
- SQuAD (Stanford Question Answering Dataset)
- PubMed Diabetes Dataset
- Drug-Target Interaction Dataset
- Pharmacogenomics Datasets
- Pancreatic Cancer Organoid Profiling
- Africa Soil Information Service (AfSIS) Soil Chemistry
- Dataset for Affective States in E-Environments
- NatureServe Explorer Dataset
- Flight Records in the US
- Worldwide flight data
- 2019 Crime statistics in the USA
- Yahoo Answers DataSets
- History of America 1400-2021
- Persian words phonetics dataset
- Historical Air Quality Dataset
- Stack Exchange Dataset
- Awesome Public Datasets
- Agriculture Datasets
- Biology Datasets
- Climate and Weather Datasets
- Complex Network Datasets
- Computer Network Datasets
- CyberSecurity Datasets
- Data Challenges Datasets
- Earth Science Datasets
- Economics Datasets
- Education Datasets
- Energy Datasets
- Entertainment Datasets
- Finance Datasets
- GIS Datasets
- Government Datasets
- Healthcare Datasets
- Image Processing Datasets
- Machine Learning Datasets
- Museums Datasets
- Natural Language Datasets
- Neuroscience Datasets
- Physics Datasets
- Prostate Cancer Datasets
- Psychology and Cognition Datasets
- Public Domains Datasets
- Search Engines Datasets
- Social Networks Datasets
- Social Sciences Datasets
- Software Datasets
- Sports Datasets
- Time Series Datasets
- Transportation Datasets
- eSports Datasets
- Complementary Collections
- Categorized list of public datasets: Sindre Sorhus /awesome List
- Platforms
- Programming Languages
- Front-End Development
- Back-End Development
- Computer Science
- Big Data
- Theory
- Books
- Editors
- Gaming
- Development Environment
- Entertainment
- Databases
- Media
- Learn
- Security
- Content Management Systems
- Hardware
- Business
- Work
- Networking
- Decentralized Systems
- Higher Education
- Events
- Testing
- Miscellaneous
- Related
- US Department of Education CRDC Dataset
- Nasa Dataset: sequencing data from bacteria before and after being taken to space
- All Trump’s twitter insults from 2015 to 2021 in CSV.
- Data is plural
- Global terrorism database
- The dolphin social network
- Dataset of 200,000 jokes
- The Million Song Dataset
- Cornell University’s eBird dataset
- UFO Report Dataset
- CDC’s Trend Drug Data
- Health and Retirement study: Public Survey data
This is a huge list, so here are here are 100+ more categories
Latest complete Netflix movie dataset
Created from 4 APIs. 11K+ rows and 30+ attributes of Netflix (Ratings, earnings, actors, language, availability, movie trailers, and many more)
Explore this dataset using FlixGem.com (this dataset is powering this webapp)
Common Crawl
A corpus of web crawl data composed of over 50 billion web pages. The Common Crawl corpus contains petabytes of data collected since 2008. It contains raw web page data, extracted metadata and text extractions.
AWS CLI Access (No AWS account required)
aws s3 ls s3://commoncrawl/ --no-sign-request
s3://commoncrawl/crawl-data/
Dataset on protein prices
Data on Primary Commodity Prices are updated monthly based on the IMF’s Primary Commodity Price System.
CPOST dataset on suicide attacks over four decades
The University of Chicago Project on Security and Threats presents the updated and expanded Database on Suicide Attacks (DSAT), which now links to Uppsala Conflict Data Program data on armed conflicts and includes a new dataset measuring the alliance and rivalry relationships among militant groups with connections to suicide attack groups. Access it here.
Credit Card Dataset – Survey of Consumer Finances (SCF) Combined Extract Data 1989-2019
You can do a lot of aggregated analysis in a pretty straightforward way there.
Drone imagery with annotations for small object detection and tracking dataset
11 TB dataset of drone imagery with annotations for small object detection and tracking
Download and more information are available here
Dataset License: CDLA-Sharing-1.0
Helper scripts for accessing the dataset: DATASET.md
Dataset Exploration: Colab
NOAA High-Resolution Rapid Refresh (HRRR) Model
The HRRR is a NOAA real-time 3-km resolution, hourly updated, cloud-resolving, convection-allowing atmospheric model, initialized by 3km grids with 3km radar assimilation. Radar data is assimilated in the HRRR every 15 min over a 1-h period adding further detail to that provided by the hourly data assimilation from the 13km radar-enhanced Rapid Refresh.
Registry of Open Data on AWS
This registry exists to help people discover and share datasets that are available via AWS resources. Learn more about sharing data on AWS.
See all usage examples for datasets listed in this registry.
See datasets from Digital Earth Africa, Facebook Data for Good, NASA Space Act Agreement, NIH STRIDES, NOAA Big Data Program, Space Telescope Science Institute, and Amazon Sustainability Data Initiative.
Textbook Question Answering (TQA)
1,076 textbook lessons, 26,260 questions, 6229 images
Documentation: https://allenai.org/data/tqa
Harmonized Cancer Datasets: Genomic Data Commons Data Portal
The GDC Data Portal is a robust data-driven platform that allows cancer researchers and bioinformaticians to search and download cancer data for analysis.
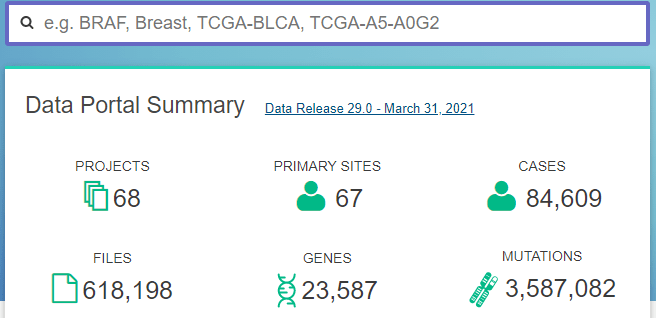
Genomic Data Commons Data Portal
The Cancer Genome Atlas
The Cancer Genome Atlas (TCGA), a collaboration between the National Cancer Institute (NCI) and National Human Genome Research Institute (NHGRI), aims to generate comprehensive, multi-dimensional maps of the key genomic changes in major types and subtypes of cancer.
AWS CLI Access (No AWS account required)
aws s3 ls s3://tcga-2-open/ --no-sign-request
Therapeutically Applicable Research to Generate Effective Treatments (TARGET)
The Therapeutically Applicable Research to Generate Effective Treatments (TARGET) program applies a comprehensive genomic approach to determine molecular changes that drive childhood cancers. The goal of the program is to use data to guide the development of effective, less toxic therapies. TARGET is organized into a collaborative network of disease-specific project teams. TARGET projects provide comprehensive molecular characterization to determine the genetic changes that drive the initiation and progression of childhood cancers. The dataset contains open Clinical Supplement, Biospecimen Supplement, RNA-Seq Gene Expression Quantification, miRNA-Seq Isoform Expression Quantification, miRNA-Seq miRNA Expression Quantification data from Genomic Data Commons (GDC), and open data from GDC Legacy Archive. Access it here.
Genome Aggregation Database (gnomAD)
The Genome Aggregation Database (gnomAD) is a resource developed by an international coalition of investigators that aggregates and harmonizes both exome and genome data from a wide range of large-scale human sequencing projects. The summary data provided here are released for the benefit of the wider scientific community without restriction on use. Downloads
SQuAD (Stanford Question Answering Dataset)
Stanford Question Answering Dataset (SQuAD) is a reading comprehension dataset, consisting of questions posed by crowdworkers on a set of Wikipedia articles, where the answer to every question is a segment of text, or span, from the corresponding reading passage, or the question might be unanswerable. Access it here.
PubMed Diabetes Dataset
The Pubmed Diabetes dataset consists of 19717 scientific publications from PubMed database pertaining to diabetes classified into one of three classes. The citation network consists of 44338 links. Each publication in the dataset is described by a TF/IDF weighted word vector from a dictionary which consists of 500 unique words. The README file in the dataset provides more details.
Drug-Target Interaction Dataset
This dataset contains interactions between drugs and targets collected from DrugBank, KEGG Drug, DCDB, and Matador. It was originally collected by Perlman et al. It contains 315 drugs, 250 targets, 1,306 drug-target interactions, 5 types of drug-drug similarities, and 3 types of target-target similarities. Drug-drug similarities include Chemical-based, Ligand-based, Expression-based, Side-effect-based, and Annotation-based similarities. Target-target similarities include Sequence-based, Protein-protein interaction network-based, and Gene Ontology-based similarities. The original task on the dataset is to predict new interactions between drugs and targets based on different types of similarities in the network. Download link
Pharmacogenomics Datasets
PharmGKB data and knowledge is available as downloads. It is often critical to check with their curators at feedback@pharmgkb.org before embarking on a large project using these data, to be sure that the files and data they make available are being interpreted correctly. PharmGKB generally does NOT need to be a co-author on such analyses; They just want to make sure that there is a correct understanding of our data before lots of resources are spent.
Pancreatic Cancer Organoid Profiling
The dataset contains open RNA-Seq Gene Expression Quantification data and controlled WGS/WXS/RNA-Seq Aligned Reads, WXS Annotated Somatic Mutation, WXS Raw Somatic Mutation, and RNA-Seq Splice Junction Quantification. Documentation
AWS CLI Access (No AWS account required)
aws s3 ls s3://gdc-organoid-pancreatic-phs001611-2-open/ --no-sign-request
Africa Soil Information Service (AfSIS) Soil Chemistry
This dataset contains soil infrared spectral data and paired soil property reference measurements for georeferenced soil samples that were collected through the Africa Soil Information Service (AfSIS) project, which lasted from 2009 through 2018. Documentation
AWS CLI Access (No AWS account required)
aws s3 ls s3://afsis/ --no-sign-request
Dataset for Affective States in E-Environments
DAiSEE is the first multi-label video classification dataset comprising of 9068 video snippets captured from 112 users for recognizing the user affective states of boredom, confusion, engagement, and frustration “in the wild”. The dataset has four levels of labels namely – very low, low, high, and very high for each of the affective states, which are crowd annotated and correlated with a gold standard annotation created using a team of expert psychologists. Download it here.
NatureServe Explorer Dataset
NatureServe Explorer provides conservation status, taxonomy, distribution, and life history information for more than 95,000 plants and animals in the United States and Canada, and more than 10,000 vegetation communities and ecological systems in the Western Hemisphere.
The data available through NatureServe Explorer represents data managed in the NatureServe Central Databases. These databases are dynamic, being continually enhanced and refined through the input of hundreds of natural heritage program scientists and other collaborators. NatureServe Explorer is updated from these central databases to reflect information from new field surveys, the latest taxonomic treatments and other scientific publications, and new conservation status assessments. Explore Data here
Flight Records in the US
Airline On-Time Performance and Causes of Flight Delays – On_Time Data.
This database contains scheduled and actual departure and arrival times, reason of delay. reported by certified U.S. air carriers that account for at least one percent of domestic scheduled passenger revenues. The data is collected by the Office of Airline Information, Bureau of Transportation Statistics (BTS).
FlightAware.com has data but you need to pay for a full dataset.
The anyflights package supplies a set of functions to generate air travel data (and data packages!) similar to nycflights13. With a user-defined year and airport, the anyflights function will grab data on:
flights: all flights that departed a given airport in a given year and monthweather: hourly meterological data for a given airport in a given year and monthairports: airport names, FAA codes, and locationsairlines: translation between two letter carrier (airline) codes and namesplanes: construction information about each plane found inflights
Airline On-Time Statistics and Delay Causes
The U.S. Department of Transportation’s (DOT) Bureau of Transportation Statistics (BTS) tracks the on-time performance of domestic flights operated by large air carriers. Summary information on the number of on-time, delayed, canceled and diverted flights appears in DOT’s monthly Air Travel Consumer Report, published about 30 days after the month’s end, as well as in summary tables posted on this website. BTS began collecting details on the causes of flight delays in June 2003. Summary statistics and raw data are made available to the public at the time the Air Travel Consumer Report is released. Access it here
Worldwide flight data
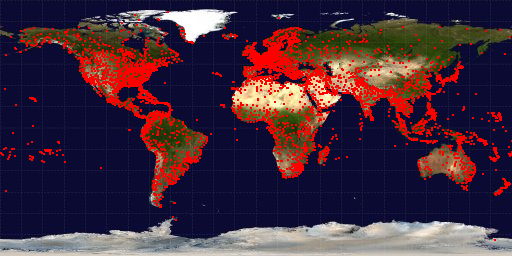
Download: airports.dat (Airports only, high quality)
Download: airports-extended.dat (Airports, train stations and ferry terminals, including user contributions)
Flightera.net seems to have a lot of good data for free. It has in-depth data on flights and doesn’t seem limited by date. I can’t speak on the validity of the data though.
flightradar24.com has lots of data, also historically, they might be willing to help you get it in a nice format.
2019 Crime statistics in the USA
Dataset with arrest in US by race and separate states. Download Excel here
Yahoo Answers DataSets
Yahoo is shutting down in 2021. This is Yahoo Answers datasets (300MB gzip) that is fairly extensive from 2015 with about 1.4m rows. This dataset has the best questions answers, I mean all the answers, including the most insane awful answers and the worst questions people put together. Download it here.
Another option here: According to the tracker, there are 77M done, 20M out(?), and 40M to go:
https://wiki.archiveteam.org/index.php/Yahoo!_Answers
History of America 1400-2021
Sources:
https://os-connect.com/pop/p2an.asp
http://www.ggdc.net/maddison/oriindex.htm
https://www.globalfirepower.com/countries-comparison.asp
Persian words phonetics dataset
This is a dataset of about 55K Persian words with their phonetics. Each word is in a line and separated from its phonetic by a tab.
Historical Air Quality Dataset
Air Quality Data Collected at Outdoor Monitors Across the US. This is a BigQuery Dataset. There are no files to download, but you can query it through Kernels using the BigQuery API. The AQS Data Mart is a database containing all of the information from AQS. It has every measured value the EPA has collected via the national ambient air monitoring program. It also includes the associated aggregate values calculated by EPA (8-hour, daily, annual, etc.). The AQS Data Mart is a copy of AQS made once per week and made accessible to the public through web-based applications. The intended users of the Data Mart are air quality data analysts in the regulatory, academic, and health research communities. It is intended for those who need to download large volumes of detailed technical data stored at EPA and does not provide any interactive analytical tools. It serves as the back-end database for several Agency interactive tools that could not fully function without it: AirData, AirCompare, The Remote Sensing Information Gateway, the Map Monitoring Sites KML page, etc.
Stack Exchange Dataset
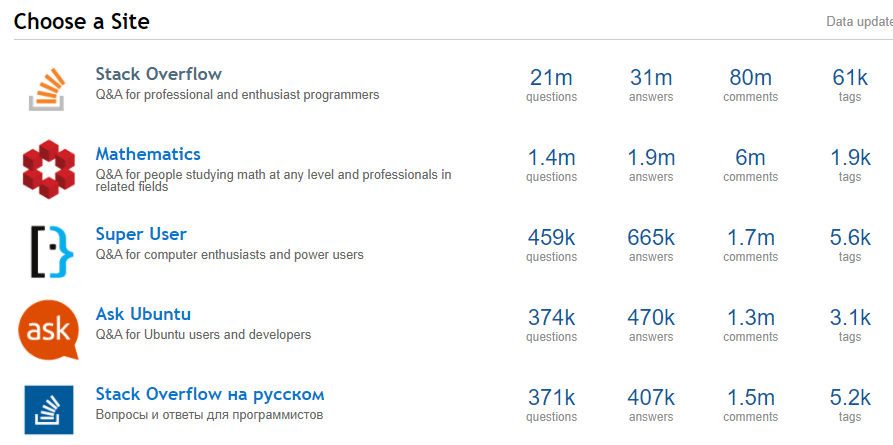
https://data.stackexchange.com/
Awesome Public Datasets
This list of a topic-centric public data sources in high quality. They are collected and tidied from blogs, answers, and user responses. Most of the data sets listed below are free, however, some are not.
Agriculture
- The global dataset of historical yields for major crops 1981–2016 – The […]
- Hyperspectral benchmark dataset on soil moisture – This dataset was […]
- Lemons quality control dataset – Lemon dataset has been prepared to […]
- Optimized Soil Adjusted Vegetation Index – The IDB is a tool for working […]
- U.S. Department of Agriculture’s Nutrient Database
- U.S. Department of Agriculture’s PLANTS Database – The Complete PLANTS […]
Biology
- 1000 Genomes – The 1000 Genomes Project ran between 2008 and 2015, […]
- American Gut (Microbiome Project) – The American Gut project is the […]
- Broad Bioimage Benchmark Collection (BBBC) – The Broad Bioimage Benchmark […]
- Broad Cancer Cell Line Encyclopedia (CCLE)
- Cell Image Library – This library is a public and easily accessible […]
- Complete Genomics Public Data – A diverse data set of whole human genomes […]
- EBI ArrayExpress – ArrayExpress Archive of Functional Genomics Data […]
- EBI Protein Data Bank in Europe – The Electron Microscopy Data Bank […]
- ENCODE project – The Encyclopedia of DNA Elements (ENCODE) Consortium is […]
- Electron Microscopy Pilot Image Archive (EMPIAR) – EMPIAR, the Electron […]
- Ensembl Genomes
- Gene Expression Omnibus (GEO) – GEO is a public functional genomics data […]
- Gene Ontology (GO) – GO annotation files
- Global Biotic Interactions (GloBI)
- Harvard Medical School (HMS) LINCS Project – The Harvard Medical School […]
- Human Genome Diversity Project – A group of scientists at Stanford […]
- Human Microbiome Project (HMP) – The HMP sequenced over 2000 reference […]
- ICOS PSP Benchmark – The ICOS PSP benchmarks repository contains an […]
- International HapMap Project
- Journal of Cell Biology DataViewer [fixme]
- KEGG – KEGG is a database resource for understanding high-level functions […]
- MIT Cancer Genomics Data
- NCBI Proteins
- NCBI Taxonomy – The NCBI Taxonomy database is a curated set of names and […]
- NCI Genomic Data Commons – The GDC Data Portal is a robust data-driven […]
- OpenSNP genotypes data – openSNP allows customers of direct-to-customer […]
- Palmer Penguins – The goal of palmerpenguins is to provide a great […]
- Pathguid – Protein-Protein Interactions Catalog
- Protein Data Bank – This resource is powered by the Protein Data Bank […]
- Psychiatric Genomics Consortium – The purpose of the Psychiatric Genomics […]
- PubChem Project – PubChem is the world’s largest collection of freely […]
- PubGene (now Coremine Medical) – COREMINE™ is a family of tools developed […]
- Sanger Catalogue of Somatic Mutations in Cancer (COSMIC) – COSMIC, the […]
- Sanger Genomics of Drug Sensitivity in Cancer Project (GDSC)
- Sequence Read Archive(SRA) – The Sequence Read Archive (SRA) stores raw […]
- Stanford Microarray Data
- Stowers Institute Original Data Repository
- Systems Science of Biological Dynamics (SSBD) Database – Systems Science […]
- The Cancer Genome Atlas (TCGA), available via Broad GDAC
- The Catalogue of Life – The Catalogue of Life is a quality-assured […]
- The Personal Genome Project – The Personal Genome Project, initiated in […]
- UCSC Public Data
- UniGene
- Universal Protein Resource (UnitProt) – The Universal Protein Resource […]
- Rfam – The Rfam database is a collection of RNA families, each […]
Climate and Climate and Weather
- Actuaries Climate Index
- Australian Weather
- Aviation Weather Center – Consistent, timely and accurate weather […]
- Brazilian Weather – Historical data (In Portuguese) – Data related to […]
- Canadian Meteorological Centre
- Climate Data from UEA (updated monthly)
- Dutch Weather – The KNMI Data Center (KDC) portal provides access to KNMI […]
- European Climate Assessment & Dataset
- German Climate Data Center
- Global Climate Data Since 1929
- Charting The Global Climate Change News Narrative 2009-2020 – These four […]
- NASA Global Imagery Browse Services
- NOAA Bering Sea Climate [fixme]
- NOAA Climate Datasets
- NOAA Realtime Weather Models
- NOAA SURFRAD Meteorology and Radiation Datasets
- The World Bank Open Data Resources for Climate Change
- UEA Climatic Research Unit
- WU Historical Weather Worldwide
- Wahington Post Climate Change – To analyze warming temperatures in the […]
- WorldClim – Global Climate Data
Complex Complex Network
- AMiner Citation Network Dataset
- CrossRef DOI URLs
- DBLP Citation dataset
- DIMACS Road Networks Collection
- NBER Patent Citations
- NIST complex networks data collection
- Network Repository with Interactive Exploratory Analysis Tools [fixme]
- Protein-protein interaction network
- PyPI and Maven Dependency Network
- Scopus Citation Database
- Small Network Data
- Stanford GraphBase
- Stanford Large Network Dataset Collection
- Stanford Longitudinal Network Data Sources [fixme]
- The Koblenz Network Collection
- The Laboratory for Web Algorithmics (UNIMI)
- UCI Network Data Repository
- UFL sparse matrix collection
- WSU Graph Database [fixme]
- Community Resource for Archiving Wireless Data At Dartmouth – Contains […]
Computer Network
- 3.5B Web Pages from CommonCrawl 2012
- 53.5B Web clicks of 100K users in Indiana Univ.
- CAIDA Internet Datasets
- CRAWDAD Wireless datasets from Dartmouth Univ. [fixme]
- ClueWeb09 – 1B web pages
- ClueWeb12 – 733M web pages
- CommonCrawl Web Data over 7 years
- Criteo click-through data
- Internet-Wide Scan Data Repository
- MIRAGE-2019 – MIRAGE-2019 is a human-generated dataset for mobile traffic […]
- OONI: Open Observatory of Network Interference – Internet censorship data
- Open Mobile Data by MobiPerf
- The Peer-to-Peer Trace Archive – Real-world measurements play a key role […]
- Rapid7 Sonar Internet Scans
- UCSD Network Telescope, IPv4 /8 net
CyberSecurity
- CCCS-CIC-AndMal-2020 – The dataset includes 200K benign and 200K malware […]
- Traffic and Log Data Captured During a Cyber Defense Exercise – This […]
Data Challenges
- Bruteforce Database
- Challenges in Machine Learning
- CrowdANALYTIX dataX [fixme]
- D4D Challenge of Orange [fixme]
- DrivenData Competitions for Social Good
- ICWSM Data Challenge (since 2009)
- KDD Cup by Tencent 2012
- Kaggle Competition Data
- Localytics Data Visualization Challenge
- Netflix Prize
- Space Apps Challenge
- Telecom Italia Big Data Challenge [fixme]
- TravisTorrent Dataset – MSR’2017 Mining Challenge
- TunedIT – Data mining & machine learning data sets, algorithms, challenges [fixme]
- Yelp Dataset Challenge [fixme]
Earth Science Datasets
- 38-Cloud (Cloud Detection) – Contains 38 Landsat 8 scene images and their […]
- AQUASTAT – Global water resources and uses
- BODC – marine data of ~22K vars
- EOSDIS – NASA’s earth observing system data
- Earth Models [fixme]
- Global Wind Atlas – The Global Wind Atlas is a free, web-based […]
- Integrated Marine Observing System (IMOS) – roughly 30TB of ocean measurements
- Marinexplore – Open Oceanographic Data
- Alabama Real-Time Coastal Observing System
- National Estuarine Research Reserves System-Wide Monitoring Program – […]
- Oil and Gas Authority Open Data – The dataset covers 12,500 offshore […]
- Smithsonian Institution Global Volcano and Eruption Database
- USGS Earthquake Archives
Economics Datasets
- American Economic Association (AEA)
- EconData from UMD
- Economic Freedom of the World Data
- Historical MacroEconomic Statistics
- INFORUM – Interindustry Forecasting at the University of Maryland
- DBnomics – the world’s economic database – Aggregates hundreds of […]
- International Trade Statistics
- Internet Product Code Database
- Joint External Debt Data Hub
- Jon Haveman International Trade Data Links
- Long-Term Productivity Database – The Long-Term Productivity database was […]
- OpenCorporates Database of Companies in the World
- Our World in Data
- SciencesPo World Trade Gravity Datasets [fixme]
- The Atlas of Economic Complexity
- The Center for International Data
- The Observatory of Economic Complexity [fixme]
- UN Commodity Trade Statistics
- UN Human Development Reports
Education Datasets
- College Scorecard Data
- New York State Education Department Data – The New York State Education […]
- Student Data from Free Code Camp
Energy Datasets
- AMPds – The Almanac of Minutely Power dataset
- BLUEd – Building-Level fully labeled Electricity Disaggregation dataset
- COMBED
- DBFC – Direct Borohydride Fuel Cell (DBFC) Dataset
- DEL – Domestic Electrical Load study datasets for South Africa (1994 – 2014)
- ECO – The ECO data set is a comprehensive data set for non-intrusive load […]
- EIA
- Global Power Plant Database – The Global Power Plant Database is a […]
- HES – Household Electricity Study, UK
- HFED
- PEM1 – Proton Exchange Membrane (PEM) Fuel Cell Dataset
- PLAID – The Plug Load Appliance Identification Dataset [fixme]
- The Public Utility Data Liberation Project (PUDL) – PUDL makes US energy […]
- REDD
- SYND – A synthetic energy dataset for non-intrusive load monitoring – […]
- Smart Meter Data Portal – The Smart Meter Data Portal is part of the […]
- Tracebase
- Ukraine Energy Centre Datasets
- UK-DALE – UK Domestic Appliance-Level Electricity
- WHITED
- iAWE
Entertainment Datasets
Finance Datasets
- BIS Statistics – BIS statistics, compiled in cooperation with central […]
- Blockmodo Coin Registry – A registry of JSON formatted information files […]
- CBOE Futures Exchange
- Complete FAANG Stock data – This data set contains all the stock data of […]
- Google Finance
- Google Trends
- NASDAQ [fixme]
- OANDA
- OSU Financial data [fixme]
- Quandl
- St Louis Federal
- Yahoo Finance
GIS Datasets
- Awesome 3D Semantic City Models – Collection of open 3D semantic city and […]
- ArcGIS Open Data portal
- Cambridge, MA, US, GIS data on GitHub
- Database of all continents, countries, States/Subdivisions/Provinces and […]
- Factual Global Location Data
- IEEE Geoscience and Remote Sensing Society DASE Website
- Geo Maps – High Quality GeoJSON maps programmatically generated
- Geo Spatial Data from ASU
- Geo Wiki Project – Citizen-driven Environmental Monitoring
- GeoFabrik – OSM data extracted to a variety of formats and areas
- GeoNames Worldwide
- Global Administrative Areas Database (GADM) – Geospatial data organized […]
- Homeland Infrastructure Foundation-Level Data
- Landsat 8 on AWS
- List of all countries in all languages
- National Weather Service GIS Data Portal
- Natural Earth – vectors and rasters of the world [fixme]
- OpenAddresses
- OpenStreetMap (OSM)
- Pleiades – Gazetteer and graph of ancient places
- Reverse Geocoder using OSM data
- Robin Wilson – Free GIS Datasets
- TIGER/Line – U.S. boundaries and roads
- TZ Timezones shapefile
- TwoFishes – Foursquare’s coarse geocoder
- UN Environmental Data
- World boundaries from the U.S. Department of State
- World countries in multiple formats
Government Datasets
- Alberta, Province of Canada
- Antwerp, Belgium
- Argentina (non official) [fixme]
- Datos Argentina – Portal de datos abiertos de la República Argentina. […]
- Austin, TX, US
- Australia (abs.gov.au)
- Australia (data.gov.au)
- Austria (data.gv.at)
- Baton Rouge, LA, US
- Beersheba, Israel – Open Data Portal (Smart7 OpenData)
- Belgium
- City of Berkeley Open Data
- Brazil
- Buenos Aires, Argentina
- Calgary, AB, Canada
- Cambridge, MA, US
- Canada
- Chicago
- Chile
- China [fixme]
- Dallas Open Data
- DataBC – data from the Province of British Columbia
- Debt to the Penny – The Debt to the Penny dataset provides information […]
- Denver Open Data
- Durham, NC Open Data
- Edmonton, AB, Canada
- England LGInform
- EuroStat
- EveryPolitician – Ongoing project collating and sharing data on every […]
- Federal Committee on Statistical Methodology (FCSM) (formerly FedStats)
- Finland
- France
- Fredericton, NB, Canada
- Gatineau, QC, Canada
- Germany
- Ghent, Belgium
- Glasgow, Scotland, UK [fixme]
- Greece
- Guardian world governments
- Halifax, NS, Canada
- Helsinki Region, Finland
- Hong Kong, China
- Houston, TX, US [fixme]
- Indian Government Data
- Indonesian Data Portal
- Iowa – Welcome to the State of Iowa’s data portal. Please explore data […]
- Ireland’s Open Data Portal
- Israel’s Open Data Portal
- Istanbul Municipality Open Data Portal
- Italy – Il Portale dati.gov.it è il catalogo nazionale dei metadati […]
- Jail deaths in America – The U.S. government does not release jail by […]
- Japan
- Laval, QC, Canada
- Lexington, KY
- London Datastore, UK
- London, ON, Canada [fixme]
- Los Angeles Open Data
- Luxembourg – Luxembourgish Open Data Portal
- MassGIS, Massachusetts, U.S.
- Metropolitan Transportation Commission (MTC), California, US
- Mexico [fixme]
- Mississauga, ON, Canada
- Moldova
- Moncton, NB, Canada
- Montreal, QC, Canada
- Mountain View, California, US (GIS)
- NYC Open Data [fixme]
- NYC betanyc
- Netherlands
- New York Department of Sanitation Monthly Tonnage – DSNY Monthly Tonnage […]
- New Zealand
- OECD
- Oakland, California, US [fixme]
- Oklahoma
- Open Data for Africa
- Open Government Data (OGD) Platform India
- OpenDataSoft’s list of 1,600 open data
- Oregon
- Ottawa, ON, Canada
- Palo Alto, California, US
- OpenDataPhilly – OpenDataPhilly is a catalog of open data in the […]
- Portland, Oregon
- Portugal – Pordata organization
- Puerto Rico Government
- Quebec City, QC, Canada [fixme]
- Quebec Province of Canada
- Regina SK, Canada
- Rio de Janeiro, Brazil
- Romania
- Russia [fixme]
- San Diego, CA
- San Antonio, TX – Community Information Now – CI:Now is a nonprofit […] [fixme]
- San Francisco Data sets
- San Jose, California, US
- San Mateo County, California, US
- Saskatchewan, Province of Canada
- Seattle
- Singapore Government Data
- South Africa Trade Statistics
- South Africa
- State of Utah, US
- Switzerland
- Taiwan gov
- Taiwan
- Tel-Aviv Open Data
- Texas Open Data
- The World Bank [fixme]
- Toronto, ON, Canada [fixme]
- Tunisia [fixme]
- U.K. Government Data
- U.S. American Community Survey
- U.S. CDC Public Health datasets
- U.S. Census Bureau
- U.S. Department of Housing and Urban Development (HUD)
- U.S. Federal Government Agencies
- U.S. Federal Government Data Catalog
- U.S. Food and Drug Administration (FDA)
- U.S. National Center for Education Statistics (NCES)
- U.S. Open Government
- UK 2011 Census Open Atlas Project
- US Counties – This is a repository of various data, broken down by US […]
- U.S. Patent and Trademark Office (USPTO) Bulk Data Products
- Uganda Bureau of Statistics [fixme]
- Ukraine
- United Nations
- Uruguay
- Valley Transportation Authority (VTA), California, US
- Vancouver, BC Open Data Catalog [fixme]
- Victoria, BC, Canada
- Vienna, Austria
- Statistics from the General Statistics Office of Vietnam – Data in […] [fixme]
- U.S. Congressional Research Service (CRS) Reports
Healthcare Datasets
- AWS COVID-19 Datasets – We’re working with organizations who make […]
- COVID-19 Case Surveillance Public Use Data – The COVID-19 case […]
- 2019 Novel Coronavirus COVID-19 Data Repository by Johns Hopkins CSSE – […]
- Coronavirus (Covid-19) Data in the United States – The New York Times is […]
- COVID-19 Reported Patient Impact and Hospital Capacity by Facility – The […]
- Composition of Foods Raw, Processed, Prepared USDA National Nutrient Database for Standard […]
- The COVID Tracking Project – The COVID Tracking Project collects and […]
- EHDP Large Health Data Sets
- GDC – GDC supports several cancer genome programs for CCG, TCGA, TARGET etc.
- Gapminder World demographic databases
- MeSH, the vocabulary thesaurus used for indexing articles for PubMed
- MeDAL – A large medical text dataset curated for abbreviation […]
- Medicare Coverage Database (MCD), U.S.
- Medicare Data Engine of medicare.gov Data
- Medicare Data File
- Number of Ebola Cases and Deaths in Affected Countries (2014)
- Open-ODS (structure of the UK NHS)
- OpenPaymentsData, Healthcare financial relationship data
- PhysioBank Databases – A large and growing archive of physiological data.
- The Cancer Imaging Archive (TCIA)
- The Cancer Genome Atlas project (TCGA)
- World Health Organization Global Health Observatory
- Yahoo Knowledge Graph COVID-19 Datasets – The Yahoo Knowledge Graph team […]
- Informatics for Integrating Biology & the Bedside [fixme]
Image Processing Datasets
- 10k US Adult Faces Database
- 2GB of Photos of Cats
- Audience Unfiltered faces for gender and age classification
- Affective Image Classification
- Animals with attributes
- CADDY Underwater Stereo-Vision Dataset of divers’ hand gestures – […]
- Cytology Dataset – CCAgT: Images of Cervical Cells with AgNOR Stain […]
- Caltech Pedestrian Detection Benchmark
- Chars74K dataset – Character Recognition in Natural Images (both English […]
- Cube++ – 4890 raw 18-megapixel images, each containing a SpyderCube color […]
- Danbooru Tagged Anime Illustration Dataset – A large-scale anime image […]
- DukeMTMC Data Set – DukeMTMC aims to accelerate advances in multi-target […] [fixme]
- ETH Entomological Collection (ETHEC) Fine Grained Butterfly (Lepidoptra) Images
- Face Recognition Benchmark
- Flickr: 32 Class Brand Logos [fixme]
- GDXray – X-ray images for X-ray testing and Computer Vision
- HumanEva Dataset – The HumanEva-I dataset contains 7 calibrated video […]
- ImageNet (in WordNet hierarchy)
- Indoor Scene Recognition
- International Affective Picture System, UFL
- KITTI Vision Benchmark Suite
- Labeled Information Library of Alexandria – Biology and Conservation – […]
- MNIST database of handwritten digits, near 1 million examples [fixme]
- Multi-View Region of Interest Prediction Dataset for Autonomous Driving – […]
- Massive Visual Memory Stimuli, MIT
- Newspaper Navigator – This dataset consists of extracted visual content […]
- Open Images From Google – Pictures with segmentation masks for 2.8 […]
- RuFa – Contains images of text written in one of two Arabic fonts (Ruqaa […]
- SUN database, MIT
- SVIRO Synthetic Vehicle Interior Rear Seat Occupancy – 25.000 synthetic […]
- Several Shape-from-Silhouette Datasets [fixme]
- Stanford Dogs Dataset
- The Action Similarity Labeling (ASLAN) Challenge
- The Oxford-IIIT Pet Dataset
- Violent-Flows – Crowd Violence / Non-violence Database and benchmark
- Visual genome
- YouTube Faces Database
Machine Learning Datasets
- All-Age-Faces Dataset – Contains 13’322 Asian face images distributed […]
- Audi Autonomous Driving Dataset – We have published the Audi Autonomous […]
- Context-aware data sets from five domains
- Delve Datasets for classification and regression
- Discogs Monthly Data
- Free Music Archive
- IMDb Database
- Iranis – A Large-scale Dataset of Farsi/Arabic License Plate Characters
- Keel Repository for classification, regression and time series
- Labeled Faces in the Wild (LFW)
- Lending Club Loan Data
- Machine Learning Data Set Repository [fixme]
- Million Song Dataset
- More Song Datasets
- MovieLens Data Sets
- New Yorker caption contest ratings
- RDataMining – “R and Data Mining” ebook data
- Registered Meteorites on Earth [fixme]
- Restaurants Health Score Data in San Francisco
- TikTok Dataset – More than 300 dance videos that capture a single person […]
- UCI Machine Learning Repository
- Yahoo! Ratings and Classification Data
- YouTube-BoundingBoxes
- Youtube 8m
- eBay Online Auctions (2012)
Museums Datasets
- Canada Science and Technology Museums Corporation’s Open Data
- Cooper-Hewitt’s Collection Database
- Metropolitan Museum of Art Collection API
- Minneapolis Institute of Arts metadata
- Natural History Museum (London) Data Portal
- Rijksmuseum Historical Art Collection
- Tate Collection metadata
- The Getty vocabularies
Natural Language Datasets
- Automatic Keyphrase Extraction
- The Big Bad NLP Database
- Blizzard Challenge Speech – The speech + text data comes from […]
- Blogger Corpus
- CLiPS Stylometry Investigation Corpus [fixme]
- ClueWeb09 FACC
- ClueWeb12 FACC
- DBpedia – 4.58M things with 583M facts
- Dirty Words – With millions of images in our library and billions of […]
- Flickr Personal Taxonomies
- Freebase of people, places, and things [fixme]
- German Political Speeches Corpus – Collection of political speeches from […]
- Google Books Ngrams (2.2TB)
- Google MC-AFP – Generated based on the public available Gigaword dataset […]
- Google Web 5gram (1TB, 2006)
- Gutenberg eBooks List [fixme]
- Hansards text chunks of Canadian Parliament
- LJ Speech – Speech dataset consisting of 13,100 short audio clips of a […]
- M-AILabs Speech – The M-AILABS Speech Dataset is the first large dataset […] [fixme]
- Microsoft MAchine Reading COmprehension Dataset (or MS MARCO)
- Machine Comprehension Test (MCTest) of text from Microsoft Research
- Machine Translation of European languages
- Making Sense of Microposts 2013 – Concept Extraction [fixme]
- Making Sense of Microposts 2016 – Named Entity rEcognition and Linking
- Multi-Domain Sentiment Dataset (version 2.0)
- Noisy speech database for training speech enhancement algorithms and TTS […] [fixme]
- Open Multilingual Wordnet
- POS/NER/Chunk annotated data
- Personae Corpus [fixme]
- SMS Spam Collection in English
- SaudiNewsNet Collection of Saudi Newspaper Articles (Arabic, 30K articles)
- Stanford Question Answering Dataset (SQuAD)
- USENET postings corpus of 2005~2011
- Universal Dependencies
- Webhose – News/Blogs in multiple languages
- Wikidata – Wikipedia databases
- Wikipedia Links data – 40 Million Entities in Context
- WordNet databases and tools
- WorldTree Corpus of Explanation Graphs for Elementary Science Questions – […]
Neuroscience Datasets
- Allen Institute Datasets
- Brain Catalogue
- Brainomics
- CodeNeuro Datasets [fixme]
- Collaborative Research in Computational Neuroscience (CRCNS)
- FCP-INDI
- Human Connectome Project
- NDAR
- NIMH Data Archive
- NeuroData
- NeuroMorpho – NeuroMorpho.Org is a centrally curated inventory of […]
- Neuroelectro
- OASIS
- OpenNEURO
- OpenfMRI
- Study Forrest
Physics Datasets
- CERN Open Data Portal
- Crystallography Open Database
- IceCube – South Pole Neutrino Observatory
- Ligo Open Science Center (LOSC) – Gravitational wave data from the LIGO […]
- NASA Exoplanet Archive
- NSSDC (NASA) data of 550 space spacecraft
- Sloan Digital Sky Survey (SDSS) – Mapping the Universe
Prostate Cancer Datasets
- EOPC-DE-Early-Onset-Prostate-Cancer-Germany – Early Onset Prostate Cancer […]
- GENIE – Data from the Genomics Evidence Neoplasia Information Exchange […]
- Genomic-Hallmarks-Prostate-Adenocarcinoma-CPC-GENE – Comprehensive […]
- MSK-IMPACT-Clinical-Sequencing-Cohort-MSKCC-Prostate-Cancer – Targeted […]
- Metastatic-Prostate-Adenocarcinoma-MCTP – Comprehensive profiling of 61 […]
- Metastatic-Prostate-Cancer-SU2CPCF-Dream-Team – Comprehensive analysis of […]
- NPCR-2001-2015 – Database from CDC’s National Program of Cancer […]
- NPCR-2005-2015 – Database from CDC’s National Program of Cancer […]
- NaF-Prostate – NaF Prostate is a collection of F-18 NaF positron emission […]
- Neuroendocrine-Prostate-Cancer – Whole exome and RNA Seq data of […]
- PLCO-Prostate-Diagnostic-Procedures – The Prostate Diagnostic Procedures […]
- PLCO-Prostate-Medical-Complications – The Prostate Medical Complications […]
- PLCO-Prostate-Screening-Abnormalities – The Prostate Screening […]
- PLCO-Prostate-Screening – The Prostate Screening dataset (177,315 […]
- PLCO-Prostate-Treatments – The Prostate Treatments dataset (13,409 […]
- PLCO-Prostate – The Prostate dataset is a comprehensive dataset that […]
- PRAD-CA-Prostate-Adenocarcinoma-Canada – Prostate Adenocarcinoma – […]
- PRAD-FR-Prostate-Adenocarcinoma-France – Prostate Adenocarcinoma – […]
- PRAD-UK-Prostate-Adenocarcinoma-United-Kingdom – Prostate Adenocarcinoma […]
- PROSTATEx-Challenge – Retrospective set of prostate MR studies. All […]
- Prostate-3T – The Prostate-3T project provided imaging data to TCIA as […]
- Prostate-Adenocarcinoma-Broad-Cornell-2012 – Comprehensive profiling of […]
- Prostate-Adenocarcinoma-Broad-Cornell-2013 – Comprehensive profiling of […]
- Prostate-Adenocarcinoma-CNA-study-MSKCC – Copy-number profiling of 103 […]
- Prostate-Adenocarcinoma-Fred-Hutchinson-CRC – Comprehensive profiling of […]
- Prostate Adenocarcinoma (MSKCC/DFCI) – Whole Exome Sequencing of 1013 […]
- Prostate-Adenocarcinoma-MSKCC – MSKCC Prostate Oncogenome Project. 181 […]
- Prostate-Adenocarcinoma-Organoids-MSKCC – Exome profiling of prostate […]
- Prostate-Adenocarcinoma-Sun-Lab – Whole-genome and Transcriptome […]
- Prostate-Adenocarcinoma-TCGA-PanCancer-Atlas – Comprehensive TCGA […]
- Prostate-Adenocarcinoma-TCGA – Integrated profiling of 333 primary […]
- Prostate-Diagnosis – PCa T1- and T2-weighted magnetic resonance images […]
- Prostate-Fused-MRI-Pathology – The Prostate Fused-MRI-Pathology […]
- Prostate-MRI – The Prostate-MRI collection of prostate Magnetic Resonance […]
- Prostate-R – The R package ‘ElemStatLearn’ contains a prostate cancer […]
- QIN-PROSTATE-Repeatability – The QIN-PROSTATE-Repeatability dataset is a […]
- QIN-PROSTATE – The QIN PROSTATE collection of the Quantitative Imaging […]
- SEER-YR1973_2015.SEER9 – The SEER November 2017 Research Data files from […]
- SEER-YR1992_2015.SJ_LA_RG_AK – The SEER November 2017 Research Data files […]
- SEER-YR2000_2015.CA_KY_LO_NJ_GA – The SEER November 2017 Research Data […]
- SEER-YR2000_2015.CA_KY_LO_NJ_GA – The July – December 2005 diagnoses for […]
- TCGA-PRAD-US – TCGA Prostate Adenocarcinoma (499 samples).
Psychology and Cognition Datasets
Public Domains Datasets
- Ably Open Realtime Data
- Amazon
- Archive.org Datasets
- Archive-it from Internet Archive
- CMU JASA data archive
- CMU StatLab collections
- Data.World
- Data360 [fixme]
- Enigma Public
- Grand Comics Database – The Grand Comics Database (GCD) is a nonprofit, […]
- Infochimps [fixme]
- KDNuggets Data Collections
- Microsoft Azure Data Market Free DataSets [fixme]
- Microsoft Data Science for Research
- Microsoft Research Open Data
- Open Library Data Dumps
- Reddit Datasets
- RevolutionAnalytics Collection [fixme]
- Sample R data sets
- StatSci.org
- Stats4Stem R data sets (archived)
- The Washington Post List
- UCLA SOCR data collection
- UFO Reports
- Wikileaks 911 pager intercepts
- Yahoo Webscope
Search Engines Datasets
- Academic Torrents of data sharing from UMB
- Datahub.io
- Domains Project – Sorted list of Internet domains
- Harvard Dataverse Network of scientific data
- ICPSR (UMICH)
- Institute of Education Sciences
- National Technical Reports Library
- Open Data Certificates (beta)
- OpenDataNetwork – A search engine of all Socrata powered data portals
- Statista.com – statistics and Studies
- Zenodo – An open dependable home for the long-tail of science
Social Networks Datasets
- 2021 Portuguese Elections Twitter Dataset – 57M+ tweets, 1M+ users – This […]
- 72 hours #gamergate Twitter Scrape
- CMU Enron Email of 150 users
- Cheng-Caverlee-Lee September 2009 – January 2010 Twitter Scrape
- China Biographical Database – The China Biographical Database is a freely […]
- A Twitter Dataset of 40+ million tweets related to COVID-19 – Due to the […]
- 43k+ Donald Trump Twitter Screenshots – This archive contains screenshots […]
- EDRM Enron EMail of 151 users, hosted on S3
- Facebook Data Scrape (2005)
- Facebook Social Connectedness Index – We use an anonymized snapshot of […]
- Facebook Social Networks from LAW (since 2007)
- Foursquare from UMN/Sarwat (2013)
- GitHub Collaboration Archive
- Google Scholar citation relations
- High-Resolution Contact Networks from Wearable Sensors
- Indie Map: social graph and crawl of top IndieWeb sites
- Mobile Social Networks from UMASS
- Network Twitter Data
- Reddit Comments
- Skytrax’ Air Travel Reviews Dataset
- Social Twitter Data
- SourceForge.net Research Data
- Twitch Top Streamer’s Data
- Twitter Data for Online Reputation Management
- Twitter Data for Sentiment Analysis
- Twitter Graph of entire Twitter site
- Twitter Scrape Calufa May 2011 [fixme]
- UNIMI/LAW Social Network Datasets
- United States Congress Twitter Data – Daily datasets with tweets of 1100+ […]
- Yahoo! Graph and Social Data
- Youtube Video Social Graph in 2007,2008
Social Sciences Datasets
- ACLED (Armed Conflict Location & Event Data Project)
- Authoritarian Ruling Elites Database – The Authoritarian Ruling Elites […]
- Canadian Legal Information Institute
- Center for Systemic Peace Datasets – Conflict Trends, Polities, State Fragility, etc [fixme]
- Correlates of War Project
- Cryptome Conspiracy Theory Items
- Datacards [fixme]
- European Social Survey
- FBI Hate Crime 2013 – aggregated data
- Fragile States Index [fixme]
- GDELT Global Events Database
- General Social Survey (GSS) since 1972
- German Social Survey
- Global Religious Futures Project
- Gun Violence Data – A comprehensive, accessible database that contains […]
- Humanitarian Data Exchange
- INFORM Index for Risk Management
- Institute for Demographic Studies
- International Networks Archive
- International Social Survey Program ISSP
- International Studies Compendium Project
- James McGuire Cross National Data
- MIT Reality Mining Dataset
- MacroData Guide by Norsk samfunnsvitenskapelig datatjeneste
- Mass Mobilization Data Project – The Mass Mobilization (MM) data are an […]
- Microsoft Academic Knowledge Graph – The Microsoft Academic Knowledge […]
- Minnesota Population Center
- Notre Dame Global Adaptation Index (ND-GAIN)
- Open Crime and Policing Data in England, Wales and Northern Ireland
- OpenSanctions – A global database of persons and companies of political, […]
- Paul Hensel General International Data Page
- PewResearch Internet Survey Project
- PewResearch Society Data Collection
- Political Polarity Data [fixme]
- StackExchange Data Explorer
- Terrorism Research and Analysis Consortium
- Texas Inmates Executed Since 1984
- Titanic Survival Data Set
- UCB’s Archive of Social Science Data (D-Lab) [fixme]
- UCLA Social Sciences Data Archive
- UN Civil Society Database
- UPJOHN for Labor Employment Research
- Universities Worldwide
- Uppsala Conflict Data Program
- World Bank Open Data
- World Inequality Database – The World Inequality Database (WID.world) […]
- WorldPop project – Worldwide human population distributions
Software Datasets
- FLOSSmole data about free, libre, and open source software development
- GHTorrent – Scalable, queryable, offline mirror of data offered through […]
- Libraries.io Open Source Repository and Dependency Metadata
- Public Git Archive – a Big Code dataset for all – dataset of 182,014 top- […]
- Code duplicates – 2k Java file and 600 Java function pairs labeled as […]
- Commit messages – 1.3 billion GitHub commit messages till March 2019
- Pull Request review comments – 25.3 million GitHub PR review comments […]
- Source Code Identifiers – 41.7 million distinct splittable identifiers […]
Sports Datasets
- American Ninja Warrior Obstacles – Contains every obstacle in the history […]
- Betfair Historical Exchange Data
- Cricsheet Matches (cricket)
- Equity in Athletics – The Equity in Athletics Data Analysis Cutting Tool […]
- Ergast Formula 1, from 1950 up to date (API)
- Football/Soccer resources (data and APIs)
- Lahman’s Baseball Database
- NFL play-by-play data – NFL play-by-play data sourced from: […]
- Pinhooker: Thoroughbred Bloodstock Sale Data
- Pro Kabadi season 1 to 7 – Pro Kabadi League is a professional-level […]
- Retrosheet Baseball Statistics
- Tennis database of rankings, results, and stats for ATP
- Tennis database of rankings, results, and stats for WTA
- USA Soccer Teams and Locations – USA soccer teams and locations. MLS, […]
Time Series Datasets
- 3W dataset – To the best of its authors’ knowledge, this is the first […]
- Databanks International Cross National Time Series Data Archive
- Hard Drive Failure Rates
- Heart Rate Time Series from MIT
- Time Series Data Library (TSDL) from MU
- Turing Change Point Dataset – Contains 42 annotated time series collected […]
- UC Riverside Time Series Dataset
Transportation
- Airlines OD Data 1987-2008
- Ford GoBike Data (formerly Bay Area Bike Share Data) [fixme]
- Bike Share Systems (BSS) collection
- Dutch Traffic Information
- GeoLife GPS Trajectory from Microsoft Research
- German train system by Deutsche Bahn
- Hubway Million Rides in MA [fixme]
- Montreal BIXI Bike Share
- NYC Taxi Trip Data 2009-
- NYC Taxi Trip Data 2013 (FOIA/FOILed)
- NYC Uber trip data April 2014 to September 2014
- Open Traffic collection
- OpenFlights – airport, airline and route data
- Philadelphia Bike Share Stations (JSON)
- Plane Crash Database, since 1920
- RITA Airline On-Time Performance data [fixme]
- RITA/BTS transport data collection (TranStat) [fixme]
- Renfe (Spanish National Railway Network) dataset
- Toronto Bike Share Stations (JSON and GBFS files)
- Transport for London (TFL)
- Travel Tracker Survey (TTS) for Chicago [fixme]
- U.S. Bureau of Transportation Statistics (BTS)
- U.S. Domestic Flights 1990 to 2009
- U.S. Freight Analysis Framework since 2007
eSports Datasets
- CS:GO Competitive Matchmaking Data – In this data set we have data about […]
- FIFA-2021 Complete Player Dataset
- OpenDota data dump
Complementary Collections
- Data Packaged Core Datasets
- Database of Scientific Code Contributions
- A growing collection of public datasets: CoolDatasets.
- DataWrangling: Some Datasets Available on the Web
- Inside-r: Finding Data on the Internet
- OpenDataMonitor: An overview of available open data resources in Europe
- Quora: Where can I find large datasets open to the public?
- RS.io: 100+ Interesting Data Sets for Statistics
- StaTrek: Leveraging open data to understand urban lives
- CV Papers: CV Datasets on the web
- CVonline: Image Databases
Categorized list of public datasets: Sindre Sorhus /awesome List
Platforms
- Node.js – Async non-blocking event-driven JavaScript runtime built on Chrome’s V8 JavaScript engine.
- Cross-Platform – Writing cross-platform code on Node.js.
- Frontend Development
- iOS – Mobile operating system for Apple phones and tablets.
- Android – Mobile operating system developed by Google.
- IoT & Hybrid Apps
- Electron – Cross-platform native desktop apps using JavaScript/HTML/CSS.
- Cordova – JavaScript API for hybrid apps.
- React Native – JavaScript framework for writing natively rendering mobile apps for iOS and Android.
- Xamarin – Mobile app development IDE, testing, and distribution.
- Linux
- Containers
- eBPF – Virtual machine that allows you to write more efficient and powerful tracing and monitoring for Linux systems.
- Arch-based Projects – Linux distributions and projects based on Arch Linux.
- macOS – Operating system for Apple’s Mac computers.
- watchOS – Operating system for the Apple Watch.
- JVM
- Salesforce
- Amazon Web Services
- Windows
- IPFS – P2P hypermedia protocol.
- Fuse – Mobile development tools.
- Heroku – Cloud platform as a service.
- Raspberry Pi – Credit card-sized computer aimed at teaching kids programming, but capable of a lot more.
- Qt – Cross-platform GUI app framework.
- WebExtensions – Cross-browser extension system.
- RubyMotion – Write cross-platform native apps for iOS, Android, macOS, tvOS, and watchOS in Ruby.
- Smart TV – Create apps for different TV platforms.
- GNOME – Simple and distraction-free desktop environment for Linux.
- KDE – A free software community dedicated to creating an open and user-friendly computing experience.
- .NET
- Amazon Alexa – Virtual home assistant.
- DigitalOcean – Cloud computing platform designed for developers.
- Flutter – Google’s mobile SDK for building native iOS and Android apps from a single codebase written in Dart.
- Home Assistant – Open source home automation that puts local control and privacy first.
- IBM Cloud – Cloud platform for developers and companies.
- Firebase – App development platform built on Google Cloud Platform.
- Robot Operating System 2.0 – Set of software libraries and tools that help you build robot apps.
- Adafruit IO – Visualize and store data from any device.
- Cloudflare – CDN, DNS, DDoS protection, and security for your site.
- Actions on Google – Developer platform for Google Assistant.
- ESP – Low-cost microcontrollers with WiFi and broad IoT applications.
- Deno – A secure runtime for JavaScript and TypeScript that uses V8 and is built in Rust.
- DOS – Operating system for x86-based personal computers that was popular during the 1980s and early 1990s.
- Nix – Package manager for Linux and other Unix systems that makes package management reliable and reproducible.
Programming Languages
- JavaScript
- Promises
- Standard Style – Style guide and linter.
- Must Watch Talks
- Tips
- Network Layer
- Micro npm Packages
- Mad Science npm Packages – Impossible sounding projects that exist.
- Maintenance Modules – For npm packages.
- npm – Package manager.
- AVA – Test runner.
- ESLint – Linter.
- Functional Programming
- Observables
- npm scripts – Task runner.
- 30 Seconds of Code – Code snippets you can understand in 30 seconds.
- Ponyfills – Like polyfills but without overriding native APIs.
- Swift – Apple’s compiled programming language that is secure, modern, programmer-friendly, and fast.
- Python – General-purpose programming language designed for readability.
- Asyncio – Asynchronous I/O in Python 3.
- Scientific Audio – Scientific research in audio/music.
- CircuitPython – A version of Python for microcontrollers.
- Data Science – Data analysis and machine learning.
- Typing – Optional static typing for Python.
- MicroPython – A lean and efficient implementation of Python 3 for microcontrollers.
- Rust
- Haskell
- PureScript
- Go
- Scala
- Scala Native – Optimizing ahead-of-time compiler for Scala based on LLVM.
- Ruby
- Clojure
- ClojureScript
- Elixir
- Elm
- Erlang
- Julia – High-level dynamic programming language designed to address the needs of high-performance numerical analysis and computational science.
- Lua
- C
- C/C++ – General-purpose language with a bias toward system programming and embedded, resource-constrained software.
- R – Functional programming language and environment for statistical computing and graphics.
- D
- Common Lisp – Powerful dynamic multiparadigm language that facilitates iterative and interactive development.
- Perl
- Groovy
- Dart
- Java – Popular secure object-oriented language designed for flexibility to “write once, run anywhere”.
- Kotlin
- OCaml
- ColdFusion
- Fortran
- PHP – Server-side scripting language.
- Composer – Package manager.
- Pascal
- AutoHotkey
- AutoIt
- Crystal
- Frege – Haskell for the JVM.
- CMake – Build, test, and package software.
- ActionScript 3 – Object-oriented language targeting Adobe AIR.
- Eta – Functional programming language for the JVM.
- Idris – General purpose pure functional programming language with dependent types influenced by Haskell and ML.
- Ada/SPARK – Modern programming language designed for large, long-lived apps where reliability and efficiency are essential.
- Q# – Domain-specific programming language used for expressing quantum algorithms.
- Imba – Programming language inspired by Ruby and Python and compiles to performant JavaScript.
- Vala – Programming language designed to take full advantage of the GLib and GNOME ecosystems, while preserving the speed of C code.
- Coq – Formal language and environment for programming and specification which facilitates interactive development of machine-checked proofs.
- V – Simple, fast, safe, compiled language for developing maintainable software.
Front-End Development
- ES6 Tools
- Web Performance Optimization
- Web Tools
- CSS – Style sheet language that specifies how HTML elements are displayed on screen.
- React – App framework.
- Relay – Framework for building data-driven React apps.
- React Hooks – A new feature that lets you use state and other React features without writing a class.
- Web Components
- Polymer – JavaScript library to develop Web Components.
- Angular – App framework.
- Backbone – App framework.
- HTML5 – Markup language used for websites & web apps.
- SVG – XML-based vector image format.
- Canvas
- KnockoutJS – JavaScript library.
- Dojo Toolkit – JavaScript toolkit.
- Inspiration
- Ember – App framework.
- Android UI
- iOS UI
- Meteor
- BEM
- Flexbox
- Web Typography
- Web Accessibility
- Material Design
- D3 – Library for producing dynamic, interactive data visualizations.
- Emails
- jQuery – Easy to use JavaScript library for DOM manipulation.
- Web Audio
- Offline-First
- Static Website Services
- Cycle.js – Functional and reactive JavaScript framework.
- Text Editing
- Motion UI Design
- Vue.js – App framework.
- Marionette.js – App framework.
- Aurelia – App framework.
- Charting
- Ionic Framework 2
- Chrome DevTools
- PostCSS – CSS tool.
- Draft.js – Rich text editor framework for React.
- Service Workers
- Progressive Web Apps
- choo – App framework.
- Redux – State container for JavaScript apps.
- webpack – Module bundler.
- Browserify – Module bundler.
- Sass – CSS preprocessor.
- Ant Design – Enterprise-class UI design language.
- Less – CSS preprocessor.
- WebGL – JavaScript API for rendering 3D graphics.
- Preact – App framework.
- Progressive Enhancement
- Next.js – Framework for server-rendered React apps.
- lit-html – HTML templating library for JavaScript.
- JAMstack – Modern web development architecture based on client-side JavaScript, reusable APIs, and prebuilt markup.
- WordPress-Gatsby – Web development technology stack with WordPress as a back end and Gatsby as a front end.
- Mobile Web Development – Creating a great mobile web experience.
- Storybook – Development environment for UI components.
- Blazor – .NET web framework using C#/Razor and HTML that runs in the browser with WebAssembly.
- PageSpeed Metrics – Metrics to help understand page speed and user experience.
- Tailwind CSS – Utility-first CSS framework for rapid UI development.
- Seed – Rust framework for creating web apps running in WebAssembly.
- Web Performance Budget – Techniques to ensure certain performance metrics for a website.
- Web Animation – Animations in the browser with JavaScript, CSS, SVG, etc.
- Yew – Rust framework inspired by Elm and React for creating multi-threaded frontend web apps with WebAssembly.
- Material-UI – Material Design React components for faster and easier web development.
- Building Blocks for Web Apps – Standalone features to be integrated into web apps.
- Svelte – App framework.
- Design systems – Collection of reusable components, guided by rules that ensure consistency and speed.
Back-End Development
- Flask – Python framework.
- Docker
- Vagrant – Automation virtual machine environment.
- Pyramid – Python framework.
- Play1 Framework
- CakePHP – PHP framework.
- Symfony – PHP framework.
- Laravel – PHP framework.
- Education
- TALL Stack – Full-stack development solution featuring libraries built by the Laravel community.
- Rails – Web app framework for Ruby.
- Gems – Packages.
- Phalcon – PHP framework.
- Useful
.htaccessSnippets - nginx – Web server.
- Dropwizard – Java framework.
- Kubernetes – Open-source platform that automates Linux container operations.
- Lumen – PHP micro-framework.
- Serverless Framework – Serverless computing and serverless architectures.
- Apache Wicket – Java web app framework.
- Vert.x – Toolkit for building reactive apps on the JVM.
- Terraform – Tool for building, changing, and versioning infrastructure.
- Vapor – Server-side development in Swift.
- Dash – Python web app framework.
- FastAPI – Python web app framework.
- CDK – Open-source software development framework for defining cloud infrastructure in code.
- IAM – User accounts, authentication and authorization.
- Chalice – Python framework for serverless app development on AWS Lambda.
Computer Science
- University Courses
- Data Science
- Machine Learning
- Tutorials
- ML with Ruby – Learning, implementing, and applying Machine Learning using Ruby.
- Core ML Models – Models for Apple’s machine learning framework.
- H3O – Open source distributed machine learning platform written in Java with APIs in R, Python, and Scala.
- Software Engineering for Machine Learning – From experiment to production-level machine learning.
- AI in Finance – Solving problems in finance with machine learning.
- JAX – Automatic differentiation and XLA compilation brought together for high-performance machine learning research.
- Speech and Natural Language Processing
- Spanish
- NLP with Ruby
- Question Answering – The science of asking and answering in natural language with a machine.
- Natural Language Generation – Generation of text used in data to text, conversational agents, and narrative generation applications.
- Linguistics
- Cryptography
- Papers – Theory basics for using cryptography by non-cryptographers.
- Computer Vision
- Deep Learning – Neural networks.
- TensorFlow – Library for machine intelligence.
- TensorFlow.js – WebGL-accelerated machine learning JavaScript library for training and deploying models.
- TensorFlow Lite – Framework that optimizes TensorFlow models for on-device machine learning.
- Papers – The most cited deep learning papers.
- Education
- Deep Vision
- Open Source Society University
- Functional Programming
- Empirical Software Engineering – Evidence-based research on software systems.
- Static Analysis & Code Quality
- Information Retrieval – Learn to develop your own search engine.
- Quantum Computing – Computing which utilizes quantum mechanics and qubits on quantum computers.
Big Data
- Big Data
- Public Datasets
- Hadoop – Framework for distributed storage and processing of very large data sets.
- Data Engineering
- Streaming
- Apache Spark – Unified engine for large-scale data processing.
- Qlik – Business intelligence platform for data visualization, analytics, and reporting apps.
- Splunk – Platform for searching, monitoring, and analyzing structured and unstructured machine-generated big data in real-time.
Theory
- Papers We Love
- Talks
- Algorithms
- Education – Learning and practicing.
- Algorithm Visualizations
- Artificial Intelligence
- Search Engine Optimization
- Competitive Programming
- Math
- Recursion Schemes – Traversing nested data structures.
Books
Editors
- Sublime Text
- Vim
- Emacs
- Atom – Open-source and hackable text editor.
- Visual Studio Code – Cross-platform open-source text editor.
Gaming
- Game Development
- Game Talks
- Godot – Game engine.
- Open Source Games
- Unity – Game engine.
- Chess
- LÖVE – Game engine.
- PICO-8 – Fantasy console.
- Game Boy Development
- Construct 2 – Game engine.
- Gideros – Game engine.
- Minecraft – Sandbox video game.
- Game Datasets – Materials and datasets for Artificial Intelligence in games.
- Haxe Game Development – A high-level strongly typed programming language used to produce cross-platform native code.
- libGDX – Java game framework.
- PlayCanvas – Game engine.
- Game Remakes – Actively maintained open-source game remakes.
- Flame – Game engine for Flutter.
- Discord Communities – Chat with friends and communities.
- CHIP-8 – Virtual computer game machine from the 70s.
- Games of Coding – Learn a programming language by making games.
Development Environment
- Quick Look Plugins – For macOS.
- Dev Env
- Dotfiles
- Shell
- Fish – User-friendly shell.
- Command-Line Apps
- ZSH Plugins
- GitHub – Hosting service for Git repositories.
- Browser Extensions
- Cheat Sheet
- Pinned Gists – Dynamic pinned gists for your GitHub profile.
- Git Cheat Sheet & Git Flow
- Git Tips
- Git Add-ons – Enhance the
gitCLI. - Git Hooks – Scripts for automating tasks during
gitworkflows. - SSH
- FOSS for Developers
- Hyper – Cross-platform terminal app built on web technologies.
- PowerShell – Cross-platform object-oriented shell.
- Alfred Workflows – Productivity app for macOS.
- Terminals Are Sexy
- GitHub Actions – Create tasks to automate your workflow and share them with others on GitHub.
Entertainment
Databases
- Database
- MySQL
- SQLAlchemy
- InfluxDB
- Neo4j
- MongoDB – NoSQL database.
- RethinkDB
- TinkerPop – Graph computing framework.
- PostgreSQL – Object-relational database.
- CouchDB – Document-oriented NoSQL database.
- HBase – Distributed, scalable, big data store.
- NoSQL Guides – Help on using non-relational, distributed, open-source, and horizontally scalable databases.
- Contexture – Abstracts queries/filters and results/aggregations from different backing data stores like ElasticSearch and MongoDB.
- Database Tools – Everything that makes working with databases easier.
- Grakn – Logical database to organize large and complex networks of data as one body of knowledge.
Media
- Creative Commons Media
- Fonts
- Codeface – Text editor fonts.
- Stock Resources
- GIF – Image format known for animated images.
- Music
- Open Source Documents
- Audio Visualization
- Broadcasting
- Pixel Art – Pixel-level digital art.
- FFmpeg – Cross-platform solution to record, convert and stream audio and video.
- Icons – Downloadable SVG/PNG/font icon projects.
- Audiovisual – Lighting, audio and video in professional environments.
Learn
- CLI Workshoppers – Interactive tutorials.
- Learn to Program
- Speaking
- Tech Videos
- Dive into Machine Learning
- Computer History
- Programming for Kids
- Educational Games – Learn while playing.
- JavaScript Learning
- CSS Learning – Mainly about CSS – the language and the modules.
- Product Management – Learn how to be a better product manager.
- Roadmaps – Gives you a clear route to improve your knowledge and skills.
- YouTubers – Watch video tutorials from YouTubers that teach you about technology.
Security
- Application Security
- Security
- CTF – Capture The Flag.
- Malware Analysis
- Android Security
- Hacking
- Honeypots – Deception trap, designed to entice an attacker into attempting to compromise the information systems in an organization.
- Incident Response
- Vehicle Security and Car Hacking
- Web Security – Security of web apps & services.
- Lockpicking – The art of unlocking a lock by manipulating its components without the key.
- Cybersecurity Blue Team – Groups of individuals who identify security flaws in information technology systems.
- Fuzzing – Automated software testing technique that involves feeding pseudo-randomly generated input data.
- Embedded and IoT Security
- GDPR – Regulation on data protection and privacy for all individuals within EU.
- DevSecOps – Integration of security practices into DevOps.
Content Management Systems
- Umbraco
- Refinery CMS – Ruby on Rails CMS.
- Wagtail – Django CMS focused on flexibility and user experience.
- Textpattern – Lightweight PHP-based CMS.
- Drupal – Extensible PHP-based CMS.
- Craft CMS – Content-first CMS.
- Sitecore – .NET digital marketing platform that combines CMS with tools for managing multiple websites.
- Silverstripe CMS – PHP MVC framework that serves as a classic or headless CMS.
Hardware
- Robotics
- Internet of Things
- Electronics – For electronic engineers and hobbyists.
- Bluetooth Beacons
- Electric Guitar Specifications – Checklist for building your own electric guitar.
- Plotters – Computer-controlled drawing machines and other visual art robots.
- Robotic Tooling – Free and open tools for professional robotic development.
- LIDAR – Sensor for measuring distances by illuminating the target with laser light.
Business
- Open Companies
- Places to Post Your Startup
- OKR Methodology – Goal setting & communication best practices.
- Leading and Managing – Leading people and being a manager in a technology company/environment.
- Indie – Independent developer businesses.
- Tools of the Trade – Tools used by companies on Hacker News.
- Clean Tech – Fighting climate change with technology.
- Wardley Maps – Provides high situational awareness to help improve strategic planning and decision making.
- Social Enterprise – Building an organization primarily focused on social impact that is at least partially self-funded.
- Engineering Team Management – How to transition from software development to engineering management.
- Developer-First Products – Products that target developers as the user.
Work
- Slack – Team collaboration.
- Remote Jobs
- Productivity
- Niche Job Boards
- Programming Interviews
- Code Review – Reviewing code.
- Creative Technology – Businesses & groups that specialize in combining computing, design, art, and user experience.
Networking
- Software-Defined Networking
- Network Analysis
- PCAPTools
- Real-Time Communications – Network protocols for near simultaneous exchange of media and data.
Decentralized Systems
- Bitcoin – Bitcoin services and tools for software developers.
- Ripple – Open source distributed settlement network.
- Non-Financial Blockchain – Non-financial blockchain applications.
- Mastodon – Open source decentralized microblogging network.
- Ethereum – Distributed computing platform for smart contract development.
- Blockchain AI – Blockchain projects for artificial intelligence and machine learning.
- EOSIO – A decentralized operating system supporting industrial-scale apps.
- Corda – Open source blockchain platform designed for business.
- Waves – Open source blockchain platform and development toolset for Web 3.0 apps and decentralized solutions.
- Substrate – Framework for writing scalable, upgradeable blockchains in Rust.
Higher Education
- Computational Neuroscience – A multidisciplinary science which uses computational approaches to study the nervous system.
- Digital History – Computer-aided scientific investigation of history.
- Scientific Writing – Distraction-free scientific writing with Markdown, reStructuredText and Jupyter notebooks.
Events
- Creative Tech Events – Events around the globe for creative coding, tech, design, music, arts and cool stuff.
- Events in Italy – Tech-related events in Italy.
- Events in the Netherlands – Tech-related events in the Netherlands.
Testing
- Testing – Software testing.
- Visual Regression Testing – Ensures changes did not break the functionality or style.
- Selenium – Open-source browser automation framework and ecosystem.
- Appium – Test automation tool for apps.
- TAP – Test Anything Protocol.
- JMeter – Load testing and performance measurement tool.
- k6 – Open-source, developer-centric performance monitoring and load testing solution.
- Playwright – Node.js library to automate Chromium, Firefox and WebKit with a single API.
- Quality Assurance Roadmap – How to start & build a career in software testing.
Miscellaneous
- JSON – Text based data interchange format.
- CSV – A text file format that stores tabular data and uses a comma to separate values.
- Discounts for Student Developers
- Radio
- Awesome – Recursion illustrated.
- Analytics
- REST
- Continuous Integration and Continuous Delivery
- Services Engineering
- Free for Developers
- Answers – Stack Overflow, Quora, etc.
- Sketch – Design app for macOS.
- Boilerplate Projects
- Readme
- Design and Development Guides
- Software Engineering Blogs
- Self Hosted
- FOSS Production Apps
- Gulp – Task runner.
- AMA – Ask Me Anything.
- Open Source Photography
- OpenGL – Cross-platform API for rendering 2D and 3D graphics.
- GraphQL
- Transit
- Research Tools
- Data Visualization
- Social Media Share Links
- Microservices
- Unicode – Unicode standards, quirks, packages and resources.
- Beginner-Friendly Projects
- Katas
- Tools for Activism
- Citizen Science – For community-based and non-institutional scientists.
- MQTT – “Internet of Things” connectivity protocol.
- Hacking Spots
- For Girls
- Vorpal – Node.js CLI framework.
- Vulkan – Low-overhead, cross-platform 3D graphics and compute API.
- LaTeX – Typesetting language.
- Economics – An economist’s starter kit.
- Funny Markov Chains
- Bioinformatics
- Cheminformatics – Informatics techniques applied to problems in chemistry.
- Colorful – Choose your next color scheme.
- Steam – Digital distribution platform.
- Bots – Building bots.
- Site Reliability Engineering
- Empathy in Engineering – Building and promoting more compassionate engineering cultures.
- DTrace – Dynamic tracing framework.
- Userscripts – Enhance your browsing experience.
- Pokémon – Pokémon and Pokémon GO.
- ChatOps – Managing technical and business operations through a chat.
- Falsehood – Falsehoods programmers believe in.
- Domain-Driven Design – Software development approach for complex needs by connecting the implementation to an evolving model.
- Quantified Self – Self-tracking through technology.
- SaltStack – Python-based config management system.
- Web Design – For digital designers.
- Creative Coding – Programming something expressive instead of something functional.
- No-Login Web Apps – Web apps that work without login.
- Free Software – Free as in freedom.
- Framer – Prototyping interactive UI designs.
- Markdown – Markup language.
- Dev Fun – Funny developer projects.
- Healthcare – Open source healthcare software for facilities, providers, developers, policy experts, and researchers.
- Magento 2 – Open Source eCommerce built with PHP.
- TikZ – Graph drawing packages for TeX/LaTeX/ConTeXt.
- Neuroscience – Study of the nervous system and brain.
- Ad-Free – Ad-free alternatives.
- Esolangs – Programming languages designed for experimentation or as jokes rather than actual use.
- Prometheus – Open-source monitoring system.
- Homematic – Smart home devices.
- Ledger – Double-entry accounting on the command-line.
- Web Monetization – A free open web standard service that allows you to send money directly in your browser.
- Uncopyright – Public domain works.
- Crypto Currency Tools & Algorithms – Digital currency where encryption is used to regulate the generation of units and verify transfers.
- Diversity – Creating a more inclusive and diverse tech community.
- Open Source Supporters – Companies that offer their tools and services for free to open source projects.
- Design Principles – Create better and more consistent designs and experiences.
- Theravada – Teachings from the Theravada Buddhist tradition.
- inspectIT – Open source Java app performance management tool.
- Open Source Maintainers – The experience of being an open source maintainer.
- Calculators – Calculators for every platform.
- Captcha – A type of challenge–response test used in computing to determine whether or not the user is human.
- Jupyter – Create and share documents that contain code, equations, visualizations and narrative text.
- FIRST Robotics Competition – International high school robotics championship.
- Humane Technology – Open source projects that help improve society.
- Speakers – Conference and meetup speakers in the programming and design community.
- Board Games – Table-top gaming fun for all.
- Software Patreons – Fund individual programmers or the development of open source projects.
- Parasite – Parasites and host-pathogen interactions.
- Food – Food-related projects on GitHub.
- Mental Health – Mental health awareness and self-care in the software industry.
- Bitcoin Payment Processors – Start accepting Bitcoin.
- Scientific Computing – Solving complex scientific problems using computers.
- Amazon Sellers
- Agriculture – Open source technology for farming and gardening.
- Product Design – Design a product from the initial concept to production.
- Prisma – Turn your database into a GraphQL API.
- Software Architecture – The discipline of designing and building software.
- Connectivity Data and Reports – Better understand who has access to telecommunication and internet infrastructure and on what terms.
- Stacks – Tech stacks for building different apps and features.
- Cytodata – Image-based profiling of biological phenotypes for computational biologists.
- IRC – Open source messaging protocol.
- Advertising – Advertising and programmatic media for websites.
- Earth – Find ways to resolve the climate crisis.
- Naming – Naming things in computer science done right.
- Biomedical Information Extraction – How to extract information from unstructured biomedical data and text.
- Web Archiving – An effort to preserve the Web for future generations.
- WP-CLI – Command-line interface for WordPress.
- Credit Modeling – Methods for classifying credit applicants into risk classes.
- Ansible – A Python-based, open source IT configuration management and automation platform.
- Biological Visualizations – Interactive visualization of biological data on the web.
- QR Code – A type of matrix barcode that can be used to store and share a small amount of information.
- Veganism – Making the plant-based lifestyle easy and accessible.
- Translations – The transfer of the meaning of a text from one language to another.
Related
- All Awesome Lists – All the Awesome lists on GitHub.
- Awesome Indexed – Search the Awesome dataset.
- Awesome Search – Quick search for Awesome lists.
- StumbleUponAwesome – Discover random pages from the Awesome dataset using a browser extension.
- Awesome CLI – A simple command-line tool to dive into Awesome lists.
- Awesome Viewer – A visualizer for all of the above Awesome lists.
US Department of Education CRDC Dataset
The US Department of Ed has a dataset called the CRDC that collects data from all the public schools in the US and has demographic, academic, financial and all sorts of other fun data points. They also have corollary datasets that use the same identifier—an expansion pack if you may. It comes out every 2-3 years. Access it here.
Nasa Dataset: sequencing data from bacteria before and after being taken to space
NASA has some sequencing data from bacteria before and after being taken to space, to look at genetic differences caused by lack of gravity, radiation and others. Very fun if you want to try your hand at some bio data science. Access it here.
All Trump’s twitter insults from 2015 to 2021 in CSV.
Extracted from the NYT story: here
Data is plural
Data is Plural is a really good newsletter published by Jeremy Singer-Vine. The datasets are very random, but super interesting. Access it here.
Global terrorism database
Huge list of terrorism incidents from inside the US and abroad. Each entry has date and location of the incident, motivations, whether people or property were lost, the size of the attack, type of attack, etc. Access it here.
Terrorist Attacks Dataset: This dataset consists of 1293 terrorist attacks each assigned one of 6 labels indicating the type of the attack. Each attack is described by a 0/1-valued vector of attributes whose entries indicate the absence/presence of a feature. There are a total of 106 distinct features. The files in the dataset can be used to create two distinct graphs. The README file in the dataset provides more details. Download Link
Terrorists: This dataset contains information about terrorists and their relationships. This dataset was designed for classification experiments aimed at classifying the relationships among terrorists. The dataset contains 851 relationships, each described by a 0/1-valued vector of attributes where each entry indicates the absence/presence of a feature. There are a total of 1224 distinct features. Each relationship can be assigned one or more labels out of a maximum of four labels making this dataset suitable for multi-label classification tasks. The README file provides more details. Download Link
The dolphin social network
This network dataset is in the category of Social Networks. A social network of bottlenose dolphins. The dataset contains a list of all of links, where a link represents frequent associations between dolphins. Access it here
Dataset of 200,000 jokes
There are about 208 000 jokes in this database scraped from three sources.
The Million Song Dataset
The Million Song Dataset is a freely-available collection of audio features and metadata for a million contemporary popular music tracks.
Its purposes are:
- To encourage research on algorithms that scale to commercial sizes
- To provide a reference dataset for evaluating research
- As a shortcut alternative to creating a large dataset with APIs (e.g. The Echo Nest’s)
- To help new researchers get started in the MIR field
Cornell University’s eBird dataset
Decades of observations of birds all around the world, truly an impressive way to leverage citizen science. Access it here.
UFO Report Dataset
NUFORC geolocated and time standardized ufo reports for close to a century of data. 80,000 plus reports. Access it here
CDC’s Trend Drug Data
The CDC has a public database called NAMCS/NHAMCS that allows you to trend drug data. It has a lot of other data points so it can be used for a variety of other reasons. Access it here.
Health and Retirement study: Public Survey data
A listing of publicly available biennial, off-year, and cross-year data products.
Example: COVID-19 Data
| Year | Product |
|---|---|
| 2020 | 2020 HRS COVID-19 Project |
Original. Reposted with permission.
Related: