Why You Should Not Overuse List Comprehensions in Python
List comprehensions in Python are super helpful one-liners. But if overused, they can make your code a pain to maintain. Here’s why.
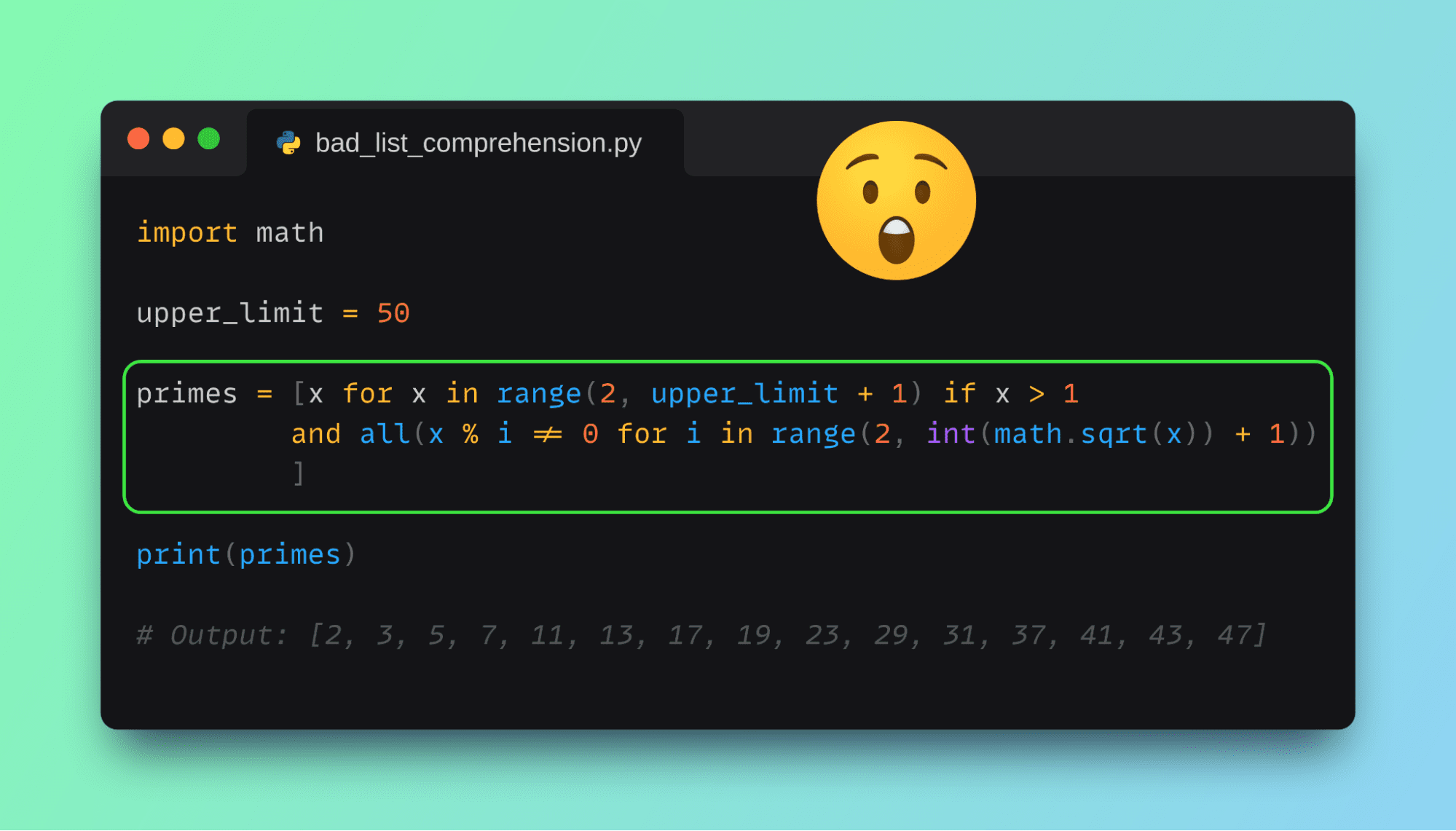
Image by Author
In Python, list comprehensions provide a concise syntax to create new lists from existing lists and other iterables. However, once you get used to list comprehensions you may be tempted to use them even when you shouldn't.
Remember, your goal is to write simple and maintainable code; not complex code. It’s often helpful to revisit the Zen of Python, a set of aphorisms for writing clean and elegant Python, especially the following:
- Beautiful is better than ugly.
- Simple is better than complex.
- Readability counts.
In this tutorial, we’ll code three examples—each more complex than the previous one—where list comprehensions make the code super difficult to maintain. We’ll then try to write a more maintainable version of the same.
So let’s start coding!
Python List Comprehensions: A Quick Review
Let's start by reviewing list comprehensions in Python. Suppose you have an existing iterable such as a list or a string. And you’d like to create a new list from it. You can loop through the iterable, process each item, and append the output to a new list like so:
new_list = []
for item in iterable:
new_list.append(output)
But less comprehensions provide a concise one-line alternative to do the same:
new_list = [output for item in iterable]
In addition, you can also add filtering conditions.
The following snippet:
new_list = []
for item in iterable:
if condition:
new_list.append(output)
Can be replaced by this list comprehension:
new_list = [output for item in iterable if condition]
So list comprehensions help you write Pythonic code—often make your code cleaner by reducing visual noise.
Now let's take three examples to understand why you shouldn't be using list comprehensions for tasks that require super complex expressions. Because in such cases, list comprehensions—instead of making your code elegant—make your code difficult to read and maintain.
Example 1: Generating Prime Numbers
Problem: Given a number upper_limit, generate a list of all the prime numbers up to that number.
You can break down this problem into two key ideas:
- Checking if a number is prime
- Populating a list with all the prime numbers
The list comprehension expression to do this is as shown:
import math
upper_limit = 50
primes = [x for x in range(2, upper_limit + 1) if x > 1 and all(x % i != 0 for i in range(2, int(math.sqrt(x)) + 1))]
print(primes)
And here’s the output:
Output >>>
[2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47]
At first glance, it is difficult to see what is going on…Let’s make it better.
Perhaps, better?
import math
upper_limit = 50
primes = [
x
for x in range(2, upper_limit + 1)
if x > 1 and all(x % i != 0 for i in range(2, int(math.sqrt(x)) + 1))
]
print(primes)
Easier to read, certainly. Now let’s write a truly better version.
A Better Version
Though a list comprehension is actually a good idea to solve this problem, the logic to check for primes in the list comprehension is making it noisy.
So let's write a more maintainable version that moves the logic for checking if a number is prime to a separate function is_prime(). And call the function is_prime() in the comprehension expression:
import math
def is_prime(num):
return num > 1 and all(num % i != 0 for i in range(2, int(math.sqrt(num)) + 1))
upper_limit = 50
primes = [
x
for x in range(2, upper_limit + 1)
if is_prime(x)
]
print(primes)
Output >>>
[2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47]
Is the better version good enough? This makes the comprehension expression much easier to understand. It's now clear that the expression collects all numbers up to upper_limit that are prime (where is_prime() returns True).
Example 2: Working with Matrices
Problem: Given a matrix, find the following:
- All the prime numbers
- The indices of the prime numbers
- Sum of the primes
- Prime numbers sorted in descending order
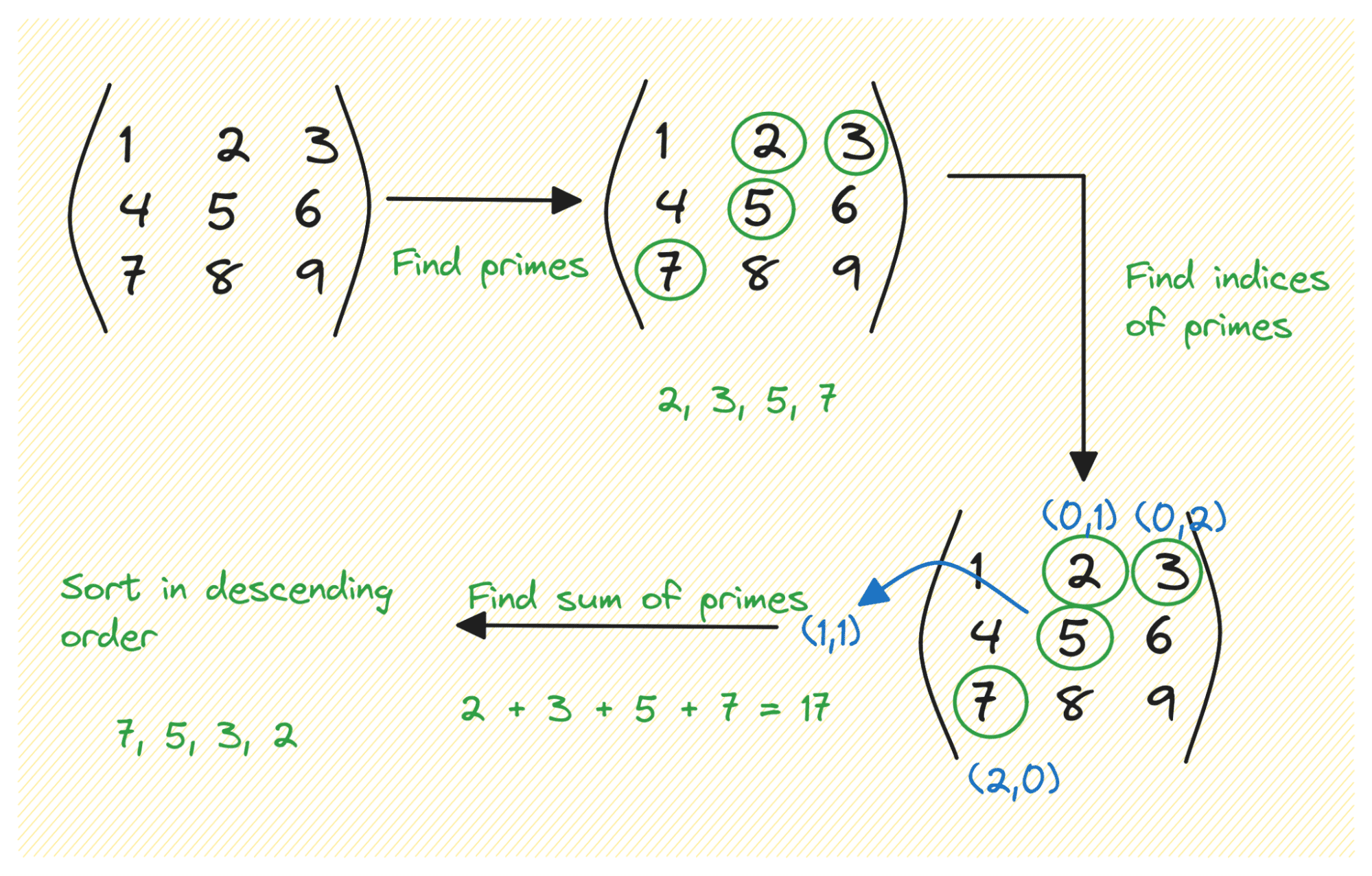
Image by Author
To flatten the matrix and collect the list of all prime numbers, we can use a logic similar to the previous example.
However, to find the indices, we have another complex list comprehension expression (I’ve formatted the code such that it is easy to read).
You can combine checking for primes and getting their indices in a single comprehension. But that will not make things any simpler.
Here’s the code:
import math
from pprint import pprint
my_matrix = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
def is_prime(num):
return num > 1 and all(num % i != 0 for i in range(2, int(math.sqrt(num)) + 1))
# Flatten the matrix and filter to contain only prime numbers
primes = [
x
for row in my_matrix
for x in row
if is_prime(x)
]
# Find indices of prime numbers in the original matrix
prime_indices = [
(i, j)
for i, row in enumerate(my_matrix)
for j, x in enumerate(row)
if x in primes
]
# Calculate the sum of prime numbers
sum_of_primes = sum(primes)
# Sort the prime numbers in descending order
sorted_primes = sorted(primes, reverse=True)
# Create a dictionary with the results
result = {
"primes": primes,
"prime_indices": prime_indices,
"sum_of_primes": sum_of_primes,
"sorted_primes": sorted_primes
}
pprint(result)
And the corresponding output:
Output >>>
{'primes': [2, 3, 5, 7],
'prime_indices': [(0, 1), (0, 2), (1, 1), (2, 0)],
'sum_of_primes': 17,
'sorted_primes': [7, 5, 3, 2]}
So what is a better version?
A Better Version
Now for the better version, we can define a series of functions to separate out concerns. So that if there’s a problem, you know which function to go back to and fix the logic.
import math
from pprint import pprint
def is_prime(num):
return num > 1 and all(n % i != 0 for i in range(2, int(math.sqrt(num)) + 1))
def flatten_matrix(matrix):
flattened_matrix = []
for row in matrix:
for x in row:
if is_prime(x):
flattened_matrix.append(x)
return flattened_matrix
def find_prime_indices(matrix, flattened_matrix):
prime_indices = []
for i, row in enumerate(matrix):
for j, x in enumerate(row):
if x in flattened_matrix:
prime_indices.append((i, j))
return prime_indices
def calculate_sum_of_primes(flattened_matrix):
return sum(flattened_matrix)
def sort_primes(flattened_matrix):
return sorted(flattened_matrix, reverse=True)
my_matrix = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
primes = flatten_matrix(my_matrix)
prime_indices = find_prime_indices(my_matrix, primes)
sum_of_primes = calculate_sum_of_primes(primes)
sorted_primes = sort_primes(primes)
result = {
"primes": primes,
"prime_indices": prime_indices,
"sum_of_primes": sum_of_primes,
"sorted_primes": sorted_primes
}
pprint(result)
This code also gives the same output as before.
Output >>>
{'primes': [2, 3, 5, 7],
'prime_indices': [(0, 1), (0, 2), (1, 1), (2, 0)],
'sum_of_primes': 17,
'sorted_primes': [7, 5, 3, 2]}
Is the better version good enough? While this works for a small matrix such as the one in this example, returning a static list is generally not recommended. And for generalizing to larger dimensions, you can use generators instead.
Example 3: Parsing Nested JSON Strings
Problem: Parse a given nested JSON string based on conditions and get a list of required values.
Parsing nested JSON strings is challenging because you have to account for the different levels of nesting, the dynamic nature of the JSON response, and diverse data types in your parsing logic.
Let's take an example of parsing a given JSON string based on conditions to get a list of all values that are:
- Integers or list of integers
- Strings or list of strings
You can load a JSON string into a Python dictionary using the loads function from the built-in json module. So we’ll have a nested dictionary over which we have a list comprehension.
The list comprehension uses nested loops to iterate over the nested dictionary. For each value, it constructs a list based on the following conditions:
- If the value is not a dictionary and the key starts with 'inner_key', it uses
[inner_item]. - If the value is a dictionary with 'sub_key', it uses
[inner_item['sub_key']]. - If the value is a string or integer, it uses
[inner_item]. - If the value is a dictionary, it uses
list(inner_item.values()).
Have a look at the code snippet below:
import json
json_string = '{"key1": {"inner_key1": [1, 2, 3], "inner_key2": {"sub_key": "value"}}, "key2": {"inner_key3": "text"}}'
# Parse the JSON string into a Python dictionary
data = json.loads(json_string)
flattened_data = [
value
if isinstance(value, (int, str))
else value
if isinstance(value, list)
else list(value)
for inner_dict in data.values()
for key, inner_item in inner_dict.items()
for value in (
[inner_item]
if not isinstance(inner_item, dict) and key.startswith("inner_key")
else [inner_item["sub_key"]]
if isinstance(inner_item, dict) and "sub_key" in inner_item
else [inner_item]
if isinstance(inner_item, (int, str))
else list(inner_item.values())
)
]
print(f"Values: {flattened_data}")
Here’s the output:
Output >>>
Values: [[1, 2, 3], 'value', 'text']
As seen, the list comprehension is very difficult to wrap your head around.
Please do yourself and others on the team a favor by never writing such code.
A Better Version
I think the following snippet using nested for loops and if-elif ladder is better. Because it’s easier to understand what’s going on.
flattened_data = []
for inner_dict in data.values():
for key, inner_item in inner_dict.items():
if not isinstance(inner_item, dict) and key.startswith("inner_key"):
flattened_data.append(inner_item)
elif isinstance(inner_item, dict) and "sub_key" in inner_item:
flattened_data.append(inner_item["sub_key"])
elif isinstance(inner_item, (int, str)):
flattened_data.append(inner_item)
elif isinstance(inner_item, list):
flattened_data.extend(inner_item)
elif isinstance(inner_item, dict):
flattened_data.extend(inner_item.values())
print(f"Values: {flattened_data}")
This gives the expected output, too:
Output >>>
Values: [[1, 2, 3], 'value', 'text']
Is the better version good enough? Well, not really.
Because if-elif ladders are often considered a code smell. You may repeat logic across branches and adding more conditions will only make the code more difficult to maintain.
But for this example, the if-elif ladders and nested loops the version is easier to understand than the comprehension expression, though.
Wrapping Up
The examples we’ve coded thus far should give you an idea of how overusing a Pythonic feature such as list comprehension can often become too much of a good thing. This is true not just for list comprehensions (they’re the most frequently used, though) but also for dictionary and set comprehensions.
You should always write code that’s easy to understand and maintain. So try to keep things simple even if it means not using some Pythonic features. Keep coding!
Bala Priya C is a developer and technical writer from India. She likes working at the intersection of math, programming, data science, and content creation. Her areas of interest and expertise include DevOps, data science, and natural language processing. She enjoys reading, writing, coding, and coffee! Currently, she's working on learning and sharing her knowledge with the developer community by authoring tutorials, how-to guides, opinion pieces, and more. Bala also creates engaging resource overviews and coding tutorials.