 Why and how should you learn “Productive Data Science”?
Why and how should you learn “Productive Data Science”?
 Why and how should you learn “Productive Data Science”?
Why and how should you learn “Productive Data Science”?What is Productive Data Science and what are some of its components?

Image source: Pixabay (Free image)
Efficiency in data science workflow
Data science and machine learning can be practiced with varying degrees of efficiency and productivity. Irrespective of the application area or specialization, a data scientist — beginner or seasoned professional — should strive to enhance his/her efficiency at all aspects of typical data science tasks,
- statistical analysis,
- visualization,
- model selection, feature engineering,
- code quality testing, modularization,
- parallel processing,
- easy web-app deployment

Image source: Pixabay (Free image)
This means performing all of these tasks,
- at higher speed
- with faster debugging
- in a synchronized manner
- by taking full advantage of any and all available hardware resources
What should you expect to learn in this process?
Let’s imagine somebody is teaching a "Productive Data Science" course or writing a book about it — using Python as the language framework. What should the typical expectations be from such a course or book?

Image source: Pixabay (Free image)
The course/book should be intended for those who wish to leapfrog beyond the standard way of performing data science and machine learning tasks and utilize the full spectrum of the Python data science ecosystem for a much higher level of productivity.
Readers should be taught how to look out for inefficiencies and bottlenecks in the standard process and how to think beyond the box.
Automation of repetitive data science tasks is a key mindset that the readers will develop from reading this book. In many cases, they will also learn how to extend the existing coding practice to handle larger datasets with high efficiency with the help of advanced software tools that already exist in the Python ecosystem but are not taught in any standard data science.
This should not be a regular Python cookbook teaching standard libraries like Numpy or Pandas.
Rather, it should focus on useful techniques such as how to measure the memory footprint and execution speed of ML models, quality test a data science pipeline, modularize a data science pipeline for app development, etc. It should also cover Python libraries which come in very handy for automating and speeding up the day-to-day tasks of any data scientist.
Furthermore, it should touch upon tools and packages which help a data scientist tackling large and complex datasets in a far more optimal way than what would have been possible by following standard Python data science technology wisdom.
Some specific skills to master

Image source: Pixabay (Free image)
To put things in concrete terms, let us summarize some specific skills to master for learning and practicing Productive Data Science. I have also tried to throw in the links to some representative articles to go with each skill as a reference.
- How to write fast and efficient code for data science/ML and how to measure their speed and efficiency (see this article)
- How to build modularized and expressive data science pipelines to improve productivity (see this article)
- How to write testing modules for data science and ML models (see this article)
- How to handle large and complex datasets efficiently (which would have been difficult with traditional DS tools)
- How to fully utilize GPU and multi-core processors for all kinds of data science and analytics tasks, and not just for specialized deep learning modeling (see this article)
- How to whip up quick GUI apps for the demo of a data science/ML idea or model tuning (see this article), or how to easily (and quickly) deploy ML models and data analysis code at an app-level (see this article)
An ideal book on this topic will…

Image source: Pixabay (Free image)
- Teach how to look out for inefficiencies and bottlenecks in the standard data science code and how to think beyond the box to solve those problems.
- Teach how to write modularized, efficient data analysis and machine learning code to improve productivity in a variety of situations — exploratory data analysis, visualization, deep learning, etc.
- Cover a wide range of side topics such as software testing, module development, GUI programming, ML model deployment as web-app, which are invaluable skillsets for budding data scientists to possess and which are hard to find collectively in any one standard data science book.
- Cover parallel computing (e.g., Dask, Ray), scalability (e.g, Vaex, Modin), and GPU-powered data science stack (RAPIDS) with hands-on examples.
- Expose and guide the readers to a larger and ever-expanding Python ecosystem of data science tools that are connected to the broader aspects of software engineering and production-level deployment.
A concrete example: GPU-powered and distributed data science
While the use of GPUs and distributed computing is widely discussed in the academic and business circles for core AI/ML tasks, they have found less coverage in their utility for regular data science and data engineering tasks. However, using GPUs for regular day-to-day statistical analyses or other data science tasks can go a long way towards becoming the proverbial "Productive Data Scientist".
For example, the RAPIDS suite of software libraries and APIs give you — a regular data scientist (and not necessarily a deep learning practitioner) — the option and flexibility to execute end-to-end data science and analytics pipelines entirely on GPUs.

Image source: Author created collage
When used even with a modest GPU, these libraries show remarkable improvement in speed over their regular Python counterparts. Naturally, we should embrace these whenever we can for Productive Data Science workflow.

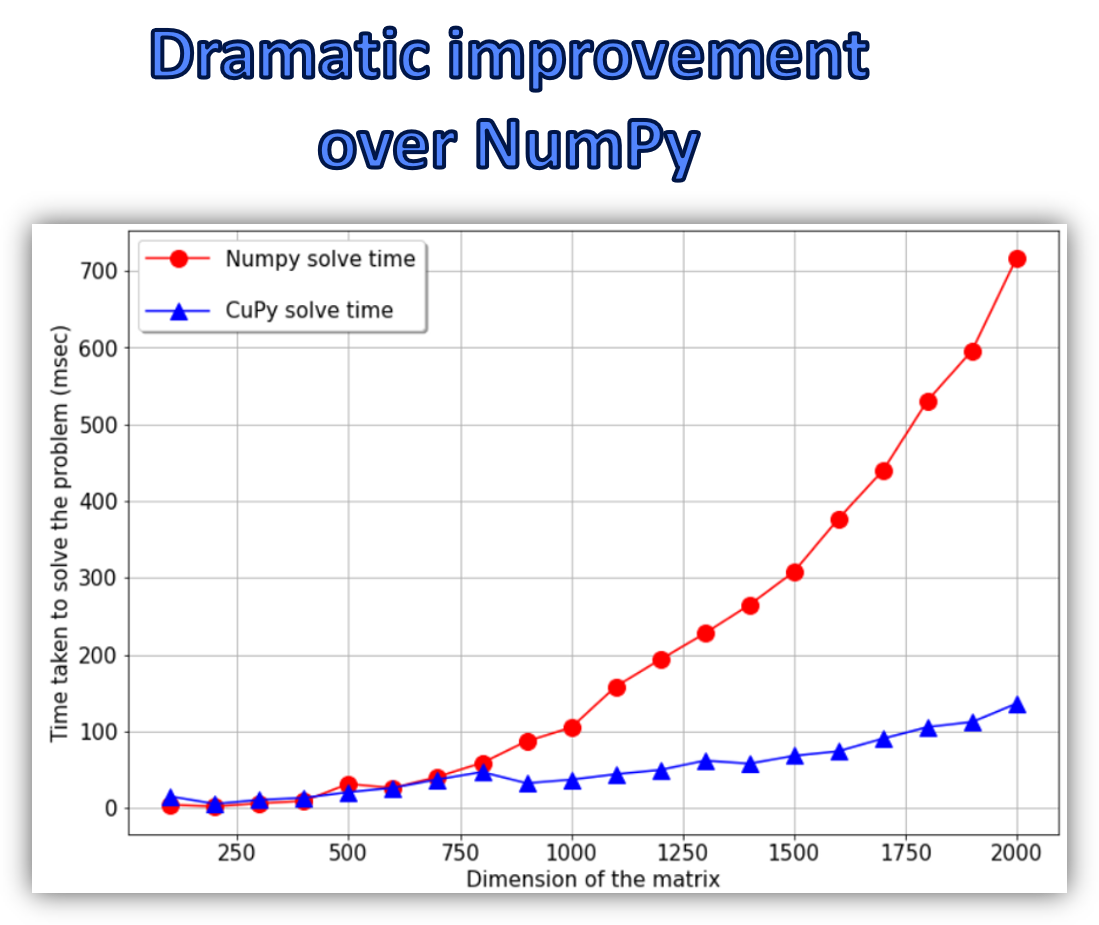
Similarly, there are excellent open-source opportunities to go beyond the limits of the single-core nature of Python language and embrace the parallel computing paradigm without shifting away from the quintessential data scientist persona.

Image source: Author created collage
Summary
We discussed the utilities and core components of a Productive Data Science workflow. We imagined what an ideal course or book on this topic would offer to the readers. We touched upon some concrete examples and illustrated the benefits. Some related resources were also provided in the context of skills to master.
You can check the author’s GitHub repositories for code, ideas, and resources in machine learning and data science. If you are, like me, passionate about AI/machine learning/data science, please feel free to add me on LinkedIn or follow me on Twitter.
Original. Reposted with permission.
Related:
- How Can You Distinguish Yourself from Hundreds of Other Data Science Candidates?
- How Much Memory is your Machine Learning Code Consuming?
- How a Single Mistake Wasted 3 Years of My Data Science Journey