 Not Only for Deep Learning: How GPUs Accelerate Data Science & Data Analytics
Not Only for Deep Learning: How GPUs Accelerate Data Science & Data Analytics
 Not Only for Deep Learning: How GPUs Accelerate Data Science & Data Analytics
Not Only for Deep Learning: How GPUs Accelerate Data Science & Data AnalyticsModern AI/ML systems’ success has been critically dependent on their ability to process massive amounts of raw data in a parallel fashion using task-optimized hardware. Can we leverage the power of GPU and distributed computing for regular data processing jobs too?

How GPUs Accelerate Data Science & Data Analytics
Artificial intelligence (AI) is set to transform global productivity, working patterns, and lifestyles and create enormous wealth. Research firm Gartner expects the global AI economy to increase from about $1.2 trillion last year to about $3.9 Trillion by 2022, while McKinsey sees it delivering global economic activity of around $13 trillion by 2030. In many ways, at its core, this transformation is fueled by powerful Machine Learning (ML) tools and techniques.
It is now well established that the modern AI/ML systems’ success has been critically dependent on their ability to process massive amounts of raw data in a parallel fashion using task-optimized hardware. Therefore, use of specialized hardware like Graphics Processing Units (GPUs) played a significant role in this early success. Since then, a lot of emphasis has been given on building highly optimized software tools and customized mathematical processing engines (both hardware and software) to leverage the power and architecture of GPUs and parallel computing.
While the use of GPUs and distributed computing is widely discussed in the academic and business circles for core AI/ML tasks (e.g. running a 100-layer deep neural network for image classification or billion-parameter BERT speech synthesis model), they find less coverage when it comes to their utility for regular data science and data engineering tasks. These data-related tasks are the essential precursor to any ML workload in an AI pipeline and they often constitute a majority percentage of the time and intellectual effort spent by a data scientist or even a ML engineer.
In fact, recently, the famous AI pioneer Andrew Ng talked about moving from a model-centric to a data-centric approach for AI tools development. This means spending much more time with the raw data and preprocessing it before an actual AI workload executes on your pipeline.
You can watch Andrew’s interview here: https://www.youtube.com/watch?v=06-AZXmwHjo

This brings us to an important question...
Can we leverage the power of GPU and distributed computing for regular data processing jobs too?
The answer is not trivial, and needs some special consideration and knowledge sharing. In this article, we will try to show some of the tools and platforms that can be used for this purpose.

Image source
RAPIDS: Leverage GPU for Data Science
The RAPIDS suite of open source software libraries and APIs gives you the ability to execute end-to-end data science and analytics pipelines entirely on GPUs. NVIDIA incubated this project and built tools to take advantage of CUDA primitives for low-level compute optimization. It specifically focuses on exposing GPU parallelism and high-bandwidth memory speed features through the friendly Python language popular with all the data scientists and analytics professionals.
Common data preparation and wrangling tasks are highly valued in the RAPIDS ecosystem as they take up a significant amount of time in a typical data science pipeline. A familiar dataframe-like API has been developed with a lot of optimization and robustness built-in. It has also been customized to integrate with a variety of ML algorithms for end-to-end pipeline accelerations with incurring serialization costs.
RAPIDS also includes a significant amount of internal support for multi-node, multi-GPU deployment and distributed processing. It integrates with other libraries which make out-of-memory (i.e. dataset size larger than individual computer RAM) data processing easy and accessible for individual data scientists.
Here are the most prominent libraries that are included in the RAPIDS ecosystem.
CuPy
A CUDA-powered array library that looks and feels like Numpy, the foundation of all numerical computing and ML with Python. It uses CUDA-related libraries including cuBLAS, cuDNN, cuRand, cuSolver, cuSPARSE, cuFFT and NCCL to make full use of the GPU architecture with the goal of providing GPU-accelerated computing with Python.
CuPy’s interface is highly similar to that of NumPy and can be used as a simple drop-in replacement for most use cases. Here is the module-level detailed list of API compatibility between CuPy and NumPy.
View the CuPy Comparison Table.
The speedup over NumPy can be mind-boggling depending on the data type and use case. Here is a speedup comparison between CuPy and NumPy for two different array sizes and for various common numerical operations - FFT, slicing, sum and standard deviation, matrix multiplication, SVD - that are widely used by almost all ML algorithms.
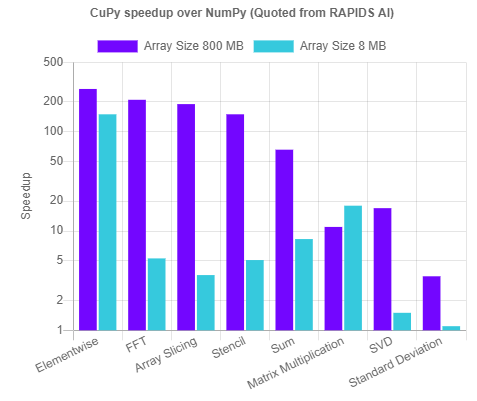
CuPy speeds compared to NumPy, Image source
CuDF
Built based on the Apache Arrow columnar memory format, cuDF is a GPU DataFrame library for loading, joining, aggregating, filtering, and otherwise manipulating data. It provides a pandas-like API that will be familiar to almost all data engineers & data scientists, so they can use it to easily accelerate their workflows using powerful GPUs without going into the details of CUDA programming.
Currently, cuDF is supported only on Linux, and with Python versions 3.7 and later. Other requirements are,
- CUDA 11.0+
- NVIDIA driver 450.80.02+
- Pascal architecture or better (Compute Capability >=6.0)
View more about this powerful library in the API docs for CuDF.
Finally, data scientists and analysts (i.e. those who do not necessarily use deep learning in any of their daily tasks) can rejoice and use powerful AI-workstations like the following to enhance their productivity.

Data science workstation from Exxact Corporation, Image source
CuML
cuML enables data scientists, analysts, and researchers to run traditional/ classical ML algorithmic tasks with (mostly) tabular datasets on GPUs without going into the details of CUDA programming. In most cases, cuML's Python API matches that of the popular Python library Scikit-learn to make the transition to GPU hardware fast and painless.
View the GitHub repo for CuML documentation to learn more.
CuML also integrates with Dask, wherever it can, to offer multi-GPU and multi-node-GPU support for an ever-increasing set of algorithms that takes advantage of such distributed processing.
CuGraph
CuGraph is a collection of GPU accelerated graph algorithms that process data found in GPU DataFrames. The vision of cuGraph is to make graph analysis ubiquitous to the point that users just think in terms of analysis and not technologies or frameworks.
Data scientists familiar with Python will quickly pick up how cuGraph integrates with the Pandas-like API of cuDF. Likewise, users familiar with NetworkX will quickly recognize the NetworkX-like API provided in cuGraph, with the goal to allow existing code to be ported with minimal effort into RAPIDS.
Currently, it supports all kinds of graph analytics algorithms,
- Centrality
- Community
- Link analysis
- Link prediction
- Traversal
Many scientific and business analytics tasks involve use of extensive graph algorithms on large datasets. Libraries like cuGraph lend the assurance of higher productivity to those engineers when they invest in GPU-powered workstations.

Empower social graph analytics using GPU-accelerated computing, Image source
The Overall Pipeline for GPU Data Science
RAPIDS envisions a whole pipeline for GPU-powered data science task flow as follows. Note that deep learning, which has traditionally been the primary focus of GPU-based computing, is only a sub-component of this system.
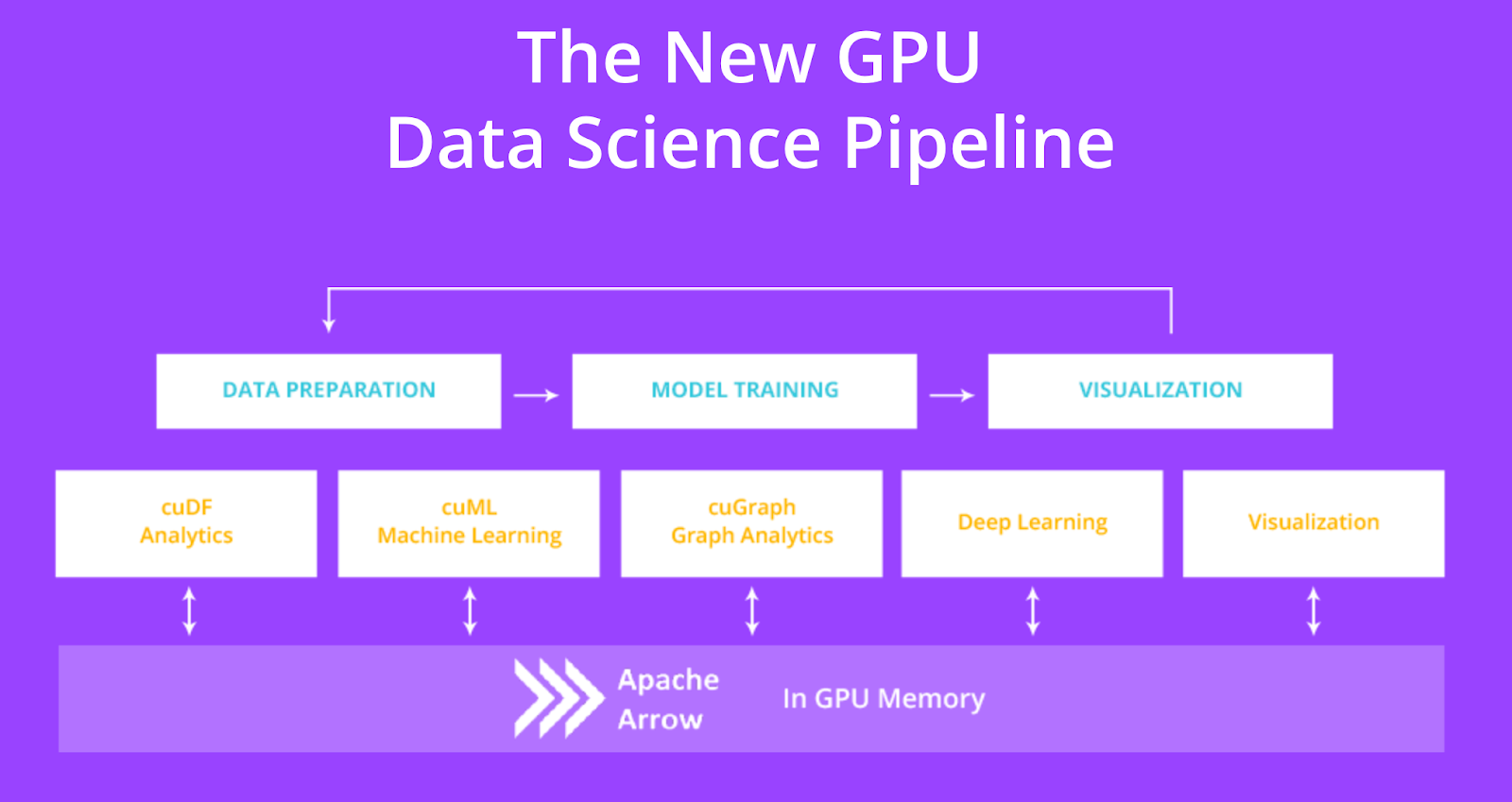
The GPU Data Science Pipeline, Image source
Dask: Distributed Analytics With Python
As we observed, modern data processing pipelines can often benefit from distributed processing of large data chunks. This is slightly different from the parallelism offered by the thousands of cores in a single GPU. This is more about how to split up a mundane data processing (which may occur much before the dataset is ready for ML algorithms) into chunks and process in using multiple compute nodes.
These computing nodes can be GPU cores or they can even be simple logical/ virtual cores of CPU.
By design, most widely popular data science libraries like Pandas, Numpy, and Scikit-learn cannot take advantage of truly distributed processing easily. Dask tries to solve this problem by bringing the features of intelligent task scheduling and big data chunk handling into regular Python code. Naturally, it is composed of two parts:
- Dynamic task scheduling optimized for computation. This is similar to Airflow, Luigi, Celery, or Make, but optimized for interactive computational workloads.
- “Big Data” collections like parallel arrays, dataframes, and lists that extend common interfaces like NumPy, Pandas, or Python iterators to larger-than-memory or distributed environments. These parallel collections run on top of the aforementioned dynamic task schedulers.
Here is an illustrative diagram of a typical Dask task-flow.
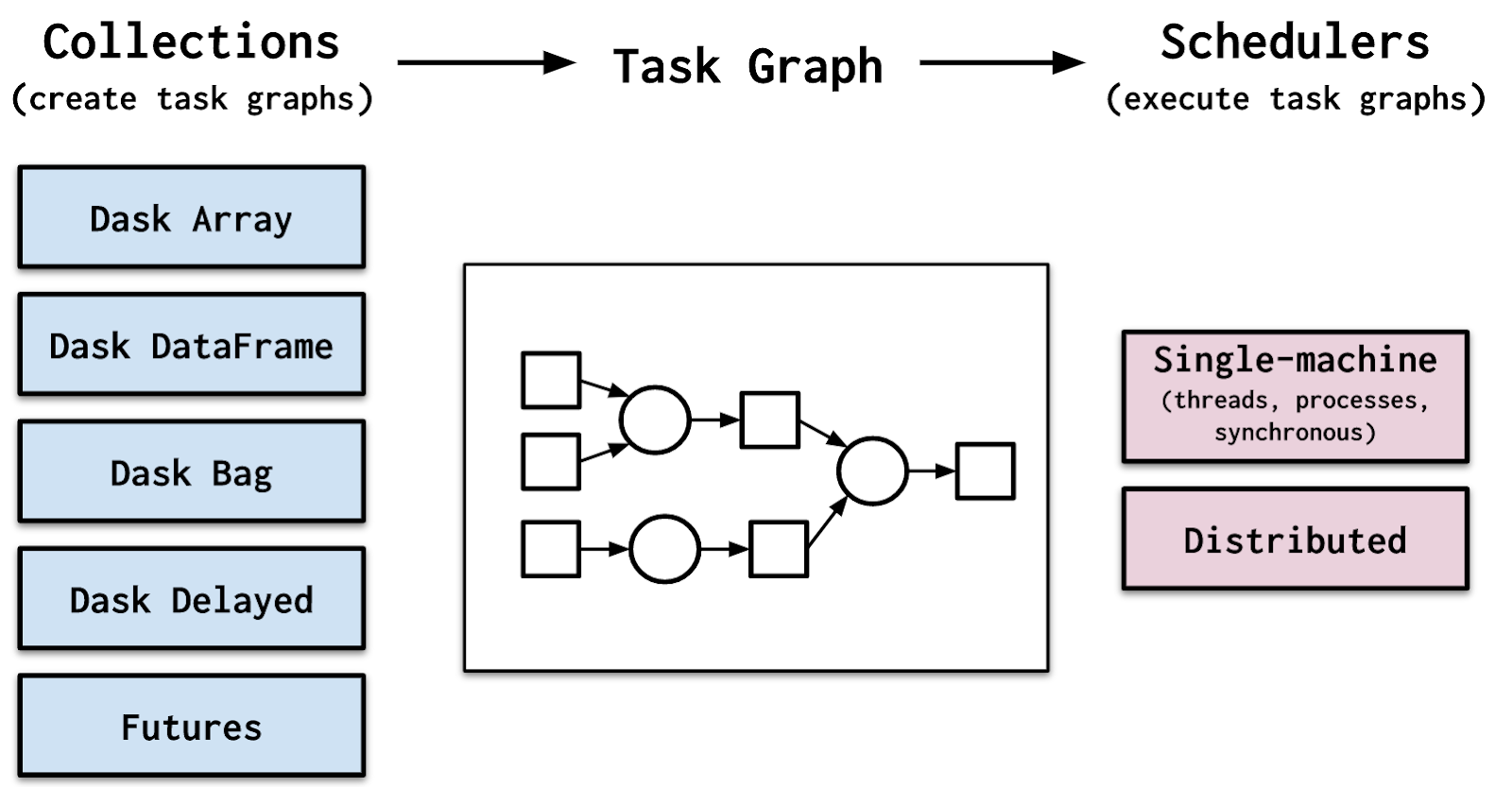
Official Dask Flow Documentation, Image source
Easy to Convert Existing Codebase
Familiarity is at the core of the Dask design, so that a typical data scientist can just pick up his/her existing Pandas/Numpy based codebase and convert it to Dask code following a minimal learning curve. Here are some of the canonical examples from their official documentation.
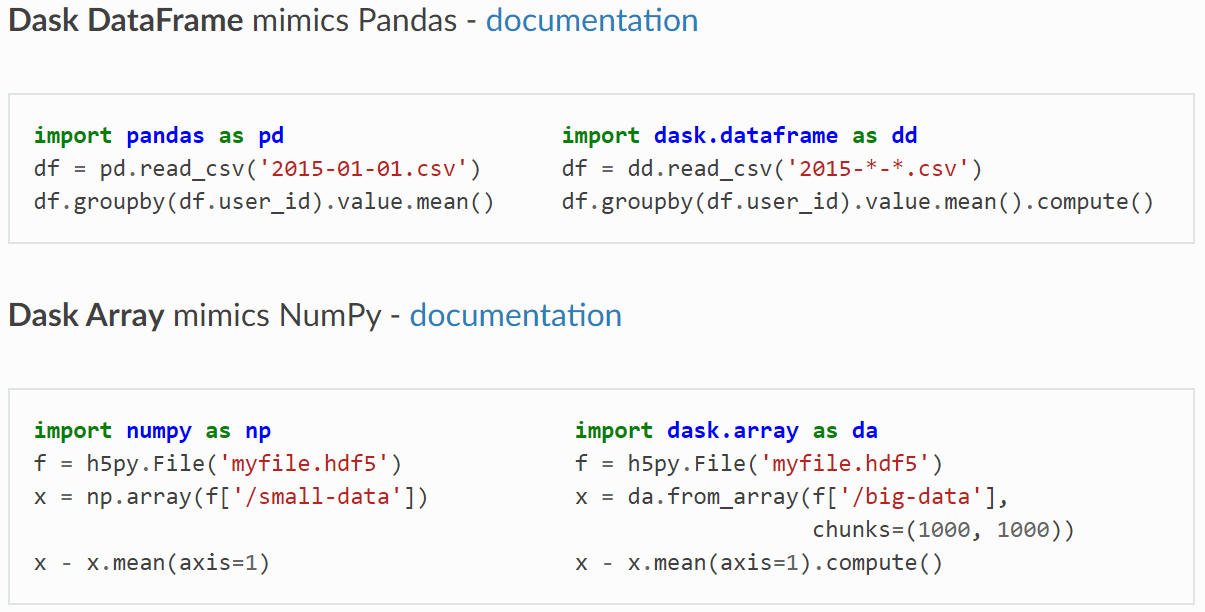
Dask Documentation comparing Pandas and NumPy, Image source
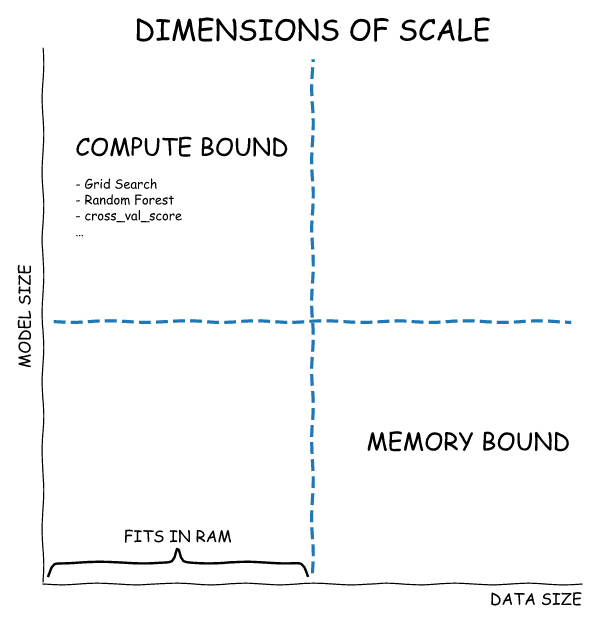
Dask-ML for Scalability Challenges
There are different kinds of scalability challenges for ML engineers. The following figure illustrates them. The machine learning library Dask-ML offers something for each of these scenarios. Therefore, one can focus on either model-centric exploration or data-centric development based on the unique business or research requirements.
Most importantly, focus on familiarity again plays a role here and the DASK-ML API is designed to mimic that of the widely popular Scikit-learn API.

Dask Documentation for XGBRegressor, Image source
Dask Benefits from Multi-Core CPU Systems
It is to be noted that the primary attractiveness of Dask comes from its role as a high-level, efficient task scheduler that can work with any Python code or data structure. Consequently, it is not dependent on a GPU to boost existing data science workloads with distributed processing.
Even multi-core CPU systems can take full advantage of Dask if the code is written to focus on that. Major changes in the code are not required.
You can distribute your convex optimization routine or hyperparameter search among many cores of your laptop using Dask. Or, you can just process different parts of a simple DataFrame based on some filtering criteria using the full multi-core parallelism. This opens up the possibility of boosting the productivity of all the data scientists and analysts who do not need to buy expensive graphics cards for their machine but can just invest in a workstation with 16 or 24 CPU cores.
Summary of Distributed Data Science Powered by GPUs
In this article, we discussed some exciting new developments in the Python data science ecosystem which enables common data scientists, analysts, science researchers, academics, to use GPU-powered hardware systems for a much wider variety of data related tasks than just what is related to image classification and natural language processing. This will surely broaden the appeal of such hardware systems to these large sections of users and democratize the data science user base even more.
We also touched upon the possibilities of distributed analytics with the Dask library which can leverage multi-core CPU workstations.
Hopefully, this kind of convergence of powerful hardware and modern software stack will open up endless possibilities for highly efficient data science workflows.
Original. Reposted with permission.
Related:
- How to Use NVIDIA GPU Accelerated Libraries
- Good-bye Big Data. Hello, Massive Data!
- Abstraction and Data Science: Not a great combination