High-Performance Deep Learning: How to train smaller, faster, and better models – Part 2
As your organization begins to consider building advanced deep learning models with efficiency in mind to improve the power delivered through your solutions, the software and hardware tools required for these implementations are foundational to achieving high-performance.

In Part 1, we discussed why efficiency is important for deep learning models to achieve high-performance models that are pareto-optimal. Let us further dive deeper into the tools and techniques for achieving efficiency.
Focus Areas of Efficiency in Deep Learning
We can think of the work on efficiency to be categorized in roughly four pillars of modelling techniques and a foundation of infrastructure and hardware.
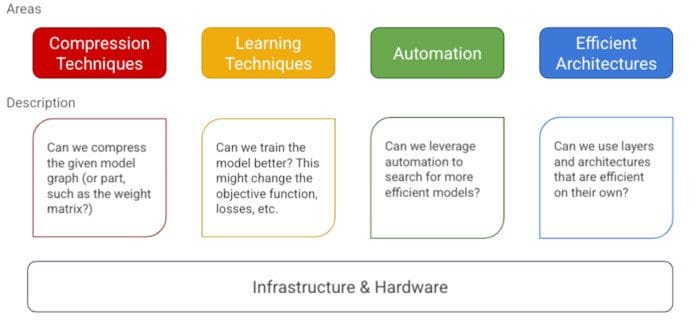
Focus Areas of Efficient Deep Learning.
- Compression Techniques: These are general techniques and algorithms that look at optimizing the architecture itself, typically by compressing its layers. Often, these approaches are generic enough to be used across architectures. A classic example is quantization [1,2], which tries to compress the weight matrix of a layer by reducing its precision (e.g., from 32-bit floating-point values to 8-bit unsigned integers). Quantization can generally be applied to any network which has a weight matrix.
- Learning Techniques: These are algorithms that focus on training the model differently so as to make fewer prediction errors. Improved accuracy can then be exchanged for a smaller footprint or a more efficient model by trimming the number of parameters if needed. An example of a learning technique is Distillation [3], which, as mentioned earlier, helps a smaller model learn from a larger, more accurate model.
- Automation: These are tools for automatically improving the core metrics of the given model using automation. An example is a hyper-parameter search [4], where the model architecture remains the same, but optimizing the hyper-parameters helps increase the accuracy, which could then be exchanged for a model with fewer parameters. Similarly, architecture search [5,6] falls in this category, where the architecture itself is tuned, and the search helps find a model that optimizes both the loss/accuracy and some other objective function. An example of a secondary objective function could be the model latency/size, etc.
- Efficient Model Architectures & Layers: These form the crux of efficiency in deep learning and are the fundamental blocks that were designed from scratch (Convolutional Layers, Attention, etc.), which are a significant leap over the baseline methods used before them. As an example, convolutional layers introduce parameter sharing and filters for use in image models, which avoids having to learn separate weights for each input pixel. This clearly saves the number of parameters when you compare it to a standard multi-layer perceptron (MLP) network. Avoiding over-parameterization further helps in making the networks more robust. In this pillar, we would look at layers and architectures that have been designed specifically with efficiency in mind.
Infrastructure & Hardware
Finally, we also need a foundation of infrastructure and tools that help us build and leverage efficient models. This includes the model training framework, such as Tensorflow, PyTorch, etc., as introduced earlier. Often these frameworks will be paired with the tools required specifically for deploying efficient models. For example, Tensorflow has tight integration with Tensorflow Lite (TFLite) [7] and related libraries, which allow exporting and running models on mobile devices. Similarly, TFLite Micro [8] helps in running these models on DSPs. Just like Tensorflow, PyTorch also offers PyTorch Mobile for quantizing and exporting models for inference on mobile and embedded devices.
We often depend on this infrastructure and tooling to leverage the gains from efficient models. For example, for obtaining both size and latency improvements with quantized models, we need the inference platform to support common neural net layers in quantized mode. TFLite supports quantized models by allowing the export of models with 8-bit unsigned int weights and having integration with libraries like GEMMLOWP [8] and XNNPACK [9] for fast inference. Similarly, PyTorch uses QNNPACK [10] to support quantized operations.
On the hardware front, we rely on devices like CPUs, GPUs, and Tensor Processing Units (TPUs) [11] to allow us to train and deploy these models. On the mobile and embedded front, we have ARM-based processors, mobile GPUs, and other accelerators [12] that let us leverage efficiency gains for deployment (inference).
In our next part, we will go over examples of tools and techniques that fit in each of these pillars. Also, feel free to go over our survey paper that explores this topic in detail.
References
[1] Benoit Jacob, Skirmantas Kligys, Bo Chen, Menglong Zhu, Matthew Tang, Andrew Howard, Hartwig Adam, and Dmitry Kalenichenko. 2018. Quantization and training of neural networks for efficient integer-arithmetic-only inference. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2704–2713.
[2] Raghuraman Krishnamoorthi. 2018. Quantizing deep convolutional networks for efficient inference: A whitepaper. arXiv (Jun 2018). arXiv:1806.08342
[3] Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. 2015. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531 (2015)
[4] Daniel Golovin, Benjamin Solnik, Subhodeep Moitra, Greg Kochanski, John Karro, and D Sculley. 2017. Google vizier: A service for black-box optimization. In Proceedings of the 23rd ACM SIGKDD international conference on knowledge discovery and data mining. 1487–1495.
[5] Barret Zoph and Quoc V Le. 2016. Neural architecture search with reinforcement learning. arXiv preprint arXiv:1611.01578 (2016).
[6] Mingxing Tan, Bo Chen, Ruoming Pang, Vijay Vasudevan, Mark Sandler, Andrew Howard, and Quoc V Le. 2019. Mnasnet: Platform-aware neural architecture search for mobile. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2820–2828.
[7] ML for Mobile and Edge Devices. https://www.tensorflow.org/lite
[8] GEMMLOWP. - https://github.com/google/gemmlowp
[9] XNNPACK. - https://github.com/google/XNNPACK
[10] Marat Dukhan, Yiming Wu Wu, and Hao Lu. 2020. QNNPACK: Open source library for optimized mobile deep learning - Facebook Engineering. https://engineering.fb.com/2018/10/29/ml-applications/qnnpack
[11] Norman P Jouppi, Cliff Young, Nishant Patil, David Patterson, Gaurav Agrawal, Raminder Bajwa, Sarah Bates, Suresh Bhatia, Nan Boden, Al Borchers, et al. 2017. In-datacenter performance analysis of a tensor processing unit. In Proceedings of the 44th annual international symposium on computer architecture. 1–12.
[12] EdgeTPU. https://cloud.google.com/edge-tpu
Bio: Gaurav Menghani (@GauravML) is a Staff Software Engineer at Google Research, where he leads research projects geared towards optimizing large machine learning models for efficient training and inference on devices ranging from tiny microcontrollers to Tensor Processing Unit (TPU)-based servers. His work has positively impacted > 1 Billion active users across YouTube, Cloud, Ads, Chrome, etc. He is also an author of an upcoming book with Manning Publication on Efficient Machine Learning. Before Google, Gaurav worked at Facebook for 4.5 years and has contributed significantly to Facebook’s Search system and large-scale distributed databases. He has an M.S. in Computer Science from Stony Brook University.
Related: