High Performance Deep Learning, Part 1
Advancing deep learning techniques continue to demonstrate incredible potential to deliver exciting new AI-enhanced software and systems. But, training the most powerful models is expensive--financially, computationally, and environmentally. Increasing the efficiency of such models will have profound impacts in many ways, so developing future models with this intension in mind will only help to further expand the reach, applicability, and value of what deep learning has to offer.

Machine Learning is being used in countless applications today. It is a natural fit in domains where there is no single algorithm that works perfectly, and there is a large amount of unseen data that the algorithm needs to do a good job predicting the right output. Unlike traditional algorithm problems where we expect exact optimal answers, machine learning applications can tolerate approximate answers. Deep Learning with neural networks has been the dominant methodology of training new machine learning models for the past decade. Its rise to prominence is often attributed to the ImageNet [1] competition in 2012. That year, a University of Toronto team submitted a deep convolutional network (AlexNet [2], named after the lead developer Alex Krizhevsky), performing 41% better than the next best submission.
Deep and convolutional networks had been tried prior to this but somehow never delivered on the promise. Convolutional Layers were first proposed by LeCun et al. in the 90s [3]. Likewise, several neural networks had been proposed in the 80s, 90s, and so on. What took so long for deep networks to outperform hand-tuned feature-engineered models?
What was different this time around was a combination of multiple things:
- Compute: AlexNet was one of the earlier models to rely on Graphics Processing Units (GPUs) for training.
- Algorithms: A critical fix was that the activation function used ReLU. This allows the gradient to back-propagate deeper. Previous iterations of deep networks used sigmoid or the tanh activation functions, which saturate at either 1.0 or -1.0 except a very small range of input. As a result, changing the input variable leads to a very tiny gradient (if any), and when there are a large number of layers, the gradient essentially vanishes.
- Data: ImageNet has > 1M images over 1000 classes. With the advent of internet-based products, collecting labeled data from user actions also became cheaper.
Rapid Growth of Deep Learning Models
As a result of this trailblazing work, there was a race to create deeper networks with an ever-larger number of parameters. Several model architectures such as VGGNet, Inception, ResNet etc., successively beat previous records at ImageNet competitions in the subsequent years. These models have also been deployed in the real world.

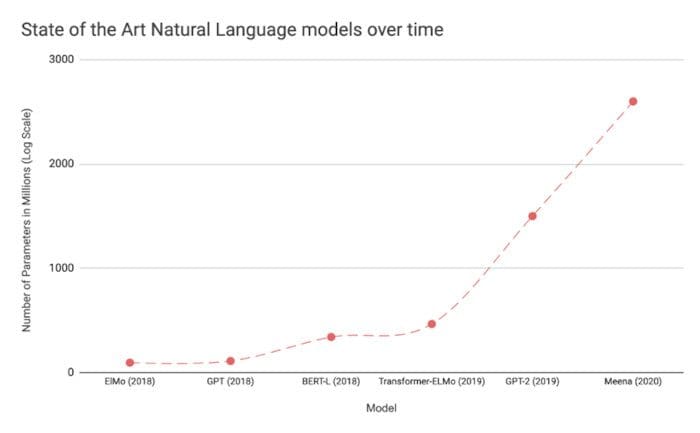
Figure 1: Growth of the number of parameters in popular computer vision and natural language deep learning models over time [4].
We have seen a similar effect in the world of natural language understanding (NLU), where the Transformer architecture significantly beat previous benchmarks on the GLUE tasks. Subsequently, BERT and GPT models have both demonstrated improvements on NLP-related tasks. BERT spawned several related model architectures optimizing its various aspects. GPT-3 has captured the attention by generating realistic text accompanying given prompts. Both have been deployed in production. BERT is used in Google Search to improve the relevance of results, and GPT-3 is available as an API for interested users to consume.
As it can be inferred, deep learning research has been focused on improving on state of the art, and as a result, we have seen progressive improvements on benchmarks like image classification, text classification, etc. Each new breakthrough in neural networks has led to an increase in the network complexity, the number of parameters, the amount of training resources required to train the network, prediction latency, etc.
Natural language models such as GPT-3 now cost millions of dollars [5] to train just one iteration. This does not include the cost of trying combinations of different hyper-parameters (tuning) or experimenting with the architecture manually or automatically. These models also often have billions (or trillions) of parameters.
At the same time, the incredible performance of these models also drives the demand for applying them on new tasks that were earlier bottlenecked by the available technology. This creates an interesting problem, where the spread of these models is rate-limited by their efficiency.
More concretely, we face the following problems as we go into this new era of deep learning where models are becoming larger and are spreading across different domains:
- Sustainable Server-Side Scaling: Training and deploying large deep learning models is costly. While training could be a one-time cost (or could be free if one is using a pre-trained model), deploying and letting inference run for over a long period of time could still turn out to be expensive. There is also a very real concern around the carbon footprint of data centers that are used for training and deploying these large models. Large organizations like Google, Facebook, Amazon, etc., spend several billion dollars each per year in capital expenditure on their data centers. Hence, any efficiency gains are very significant.
- Enabling On-Device Deployment: With the advent of smartphones, IoT devices, and the applications deployed on them have to be real-time. Hence, there is a need for on-device ML models (where the model inference happens directly on the device), which makes it imperative to optimize the models for the device they will run on.
- Privacy & Data Sensitivity: Being able to use as little data for training is critical when the user data might be sensitive to handling / subject to various restrictions such as the GDPR law in Europe. Hence, efficiently training models with a fraction of the data means lesser data-collection required. Similarly, enabling on-device models would imply that the model inference can be run completely on the user’s device without the need to send the input data to the server-side.
- New Applications: Efficiency would also enable applications that couldn’t have otherwise been feasible with the existing resource constraints.
- Explosion of Models: Often, there might be multiple ML models being served concurrently on the same device. This further reduces the available resources for a single model. This could happen on the server-side where multiple models are co-located on the same machine or could be in an app where different models are used for different functionalities.
Efficient Deep Learning
The core challenge that we identified above is efficiency. While efficiency can be an overloaded term, let us investigate two primary aspects.
- Inference Efficiency: This primarily deals with questions that someone deploying a model for inference (computing the model outputs for a given input) would ask. Is the model small? Is it fast, etc.? More concretely, how many parameters does the model have? What is the disk size, RAM consumption during inference, inference latency, etc.?
- Training Efficiency: This involves questions someone training a model would ask, such as how long does the model take to train? How many devices are required for the training? Can the model fit in memory? It might also include questions like, how much data would the model need to achieve the desired performance on the given task?
If we were to be given two models performing equally well on a given task, we might want to choose a model which does better in either one or ideally both of the above aspects. If one were to be deploying a model on devices where inference is constrained (such as mobile and embedded devices) or expensive (cloud servers), it might be worth paying attention to inference efficiency. Similarly, if one is training a large model from scratch on either with limited or costly training resources, developing models that are designed for training efficiency would help.
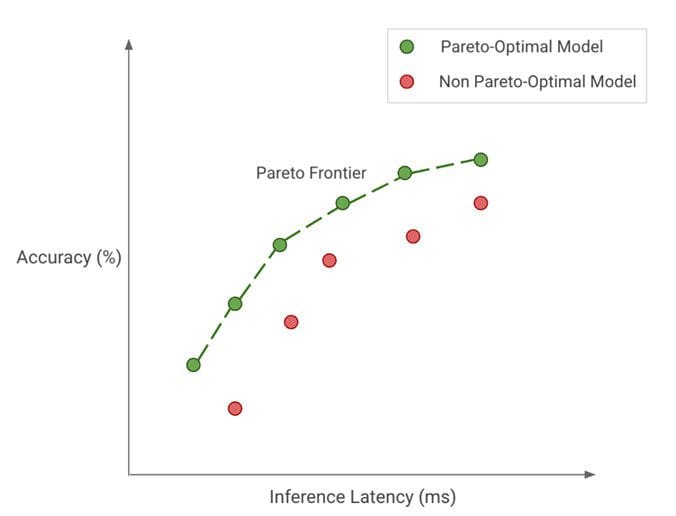
Figure 2: Pareto-optimality: Green dots represent pareto-optimal models (together forming the pareto-frontier), where none of the other models (red dots) get better accuracy with the same inference latency or the other way around.
Regardless of what one might be optimizing for, we want to achieve pareto-optimality. This implies that any model that we choose is the best for the tradeoffs that we care about. As an example in Figure 2, the green dots represent pareto-optimal models, where none of the other models (red dots) get better accuracy with the same inference latency or the other way around. Together, the pareto-optimal models (green dots) form our pareto-frontier. The models in the pareto-frontier are by definition more efficient than the other models since they perform the best for their given tradeoff. Hence, when we seek efficiency, we should be thinking about discovering and improving on the pareto-frontier.
Efficient Deep Learning can, in turn, be defined as a collection of algorithms, techniques, tools, and infrastructure that work together to allow users to train and deploy pareto-optimal models that simply cost lesser resources to train and/or deploy while achieving similar results.
Now that we have motivated the problem, in the next post, we will discuss the five pillars of efficiency in Deep Learning.
References
[1] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. 2009. ImageNet: A large-scale hierarchical image database. In 2009 IEEE Conference on Computer Vision and Pattern Recognition. 248–255. https://doi.org/10.1109/CVPR.2009.5206848
[2] Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. 2012. Imagenet classification with deep convolutional neural networks. Advances in neural information processing systems 25 (2012), 1097–1105.
[3] Convolutional Networks: http://yann.lecun.com/exdb/lenet/index.html
[4] PapersWithCode: https://paperswithcode.com/
[5] Tom B Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners. arXiv preprint arXiv:2005.14165 (2020).
Bio: Gaurav Menghani (@GauravML) is a Staff Software Engineer at Google Research, where he leads research projects geared towards optimizing large machine learning models for efficient training and inference on devices ranging from tiny microcontrollers to Tensor Processing Unit (TPU)-based servers. His work has positively impacted > 1 billion active users across YouTube, Cloud, Ads, Chrome, etc. He is also an author of an upcoming book with Manning Publication on Efficient Machine Learning. Before Google, Gaurav worked at Facebook for 4.5 years and has contributed significantly to Facebook’s Search system and large-scale distributed databases. He has an M.S. in Computer Science from Stony Brook University.
Related: