People Management for AI: Building High-Velocity AI Teams
Practical advice for managers and directors who are looking to build AI/ML teams.
This article describes how ML infrastructure, people, and processes can be meld together to enable MLOps that works for your organization. It provides practical advice to managers and directors looking to build a robust AI/ML practice with high-velocity AI teams.
The advice we share in this post is based on the experience of the Provectus AI team that has worked with multiple customers on different stages of their AI journeys.
What Is a Balanced AI Team?
Only a couple of years ago, a considerable portion of AI/ML projects were the responsibility of data scientists. While some teams relied on a more advanced combination of roles and tools, data scientists handling models in notebooks was the industry norm.
Today, hiring only a data scientist is not enough to deliver a viable AI/ML project to production quickly, efficiently, and at scale. It requires a cross-functional, high-performing team with multiple roles, each handling their own portion of ML infrastructure and MLOps.
In a modern team, a data scientist or citizen data scientist is still an essential member. Data scientists are subject matter experts who understand the data and the business holistically. They are hands-on in data mining, data modeling, and data visualization. They also stay on top of data quality and data bias issues, analyze experiments and model outputs, validate hypotheses, and contribute to the ML engineering roadmap.
A balanced AI team should also include an ML engineer whose skillset is different from that of a data scientist. They should have deep expertise in particular AI and ML applications and use cases. For example, if you build a Computer Vision application, the ML engineer should possess extensive knowledge of state-of-the-art deep learning models for Computer Vision.
Note: Every ML engineer should have MLOps expertise, but the ML/MLOps infrastructure itself, including its tools and components, should be the domain of a dedicated MLOps professional.
A project manager should also be trained to execute ML and AI projects. A traditional Scrum or Kanban project workflow does not work for ML projects. For instance, at Provectus we have a specific methodology for managing an ML project’s scope and timeline, and for setting the expectations of its business stakeholders.
We will explore each of these (and other) roles in more detail, and explain how they map onto the ML infrastructure, the MLOps enablement process, and ML delivery. The takeaway message here is that AI teams need a balanced composition, in order to enable MLOps and accelerate AI adoption.
Further reading: How Provectus and GoCheck Kids Built ML Infrastructure for Improved Usability During Vision Screening
Management Challenges of Building AI Teams
Aside from the actual team composition, effective management is vital to making AI teams work in sync with the ML infrastructure and MLOps foundation.
A typical organizational structure from a management perspective consists of:
- Business units and traditional software engineers who report to the VP of Engineering
- DevOps professionals and infrastructure experts who report to the VP of Infrastructure
- Data scientists who handle data and, as a rule, work directly with business stakeholders
- Data engineers who build systems designed to convert raw data into usable information for data scientists and business analysts
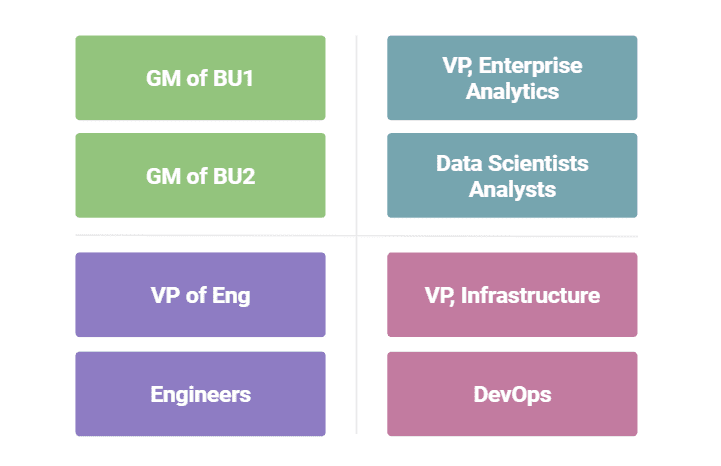
This structure creates massive cross-departmental silos and other challenges.
- Because companies’ understanding of ML workflow and AI project management is limited, no one from the above groups fully understands how to translate business goals into launching an AI product in production. As a result, it becomes impossible to manage the project’s scope and KPIs, resulting in failure to meet the expectations of business stakeholders.
- Some companies try to delegate AI projects to existing data science teams that historically work in their own silos and rely on Data Science approaches that do not work for AI/ML projects. As a result, they end up with unfinished products and projects that cannot be deployed to production.
- Other companies often assign AI projects to traditional Java and .NET developers, or leverage third party ML APIs. This approach also tends to fail, because you still need a deep understanding of data and its underlying algorithms to use these APIs efficiently. As a result, they end up with a growing technical debt in the form of Data Science code that will never see production.
The solution to these challenges lies in finding the right balance between people and tools. In the context of this article, this means a balanced AI team that utilizes an end-to-end MLOps infrastructure to collaborate and iterate.
Bear in mind that you cannot simply hire an MLOps Specialist, or buy an MLOps platform. You need both: a robust infrastructure and a balanced AI team to get your AI/ML projects off the ground.
How a Balanced AI team and MLOps Infrastructure Work Together
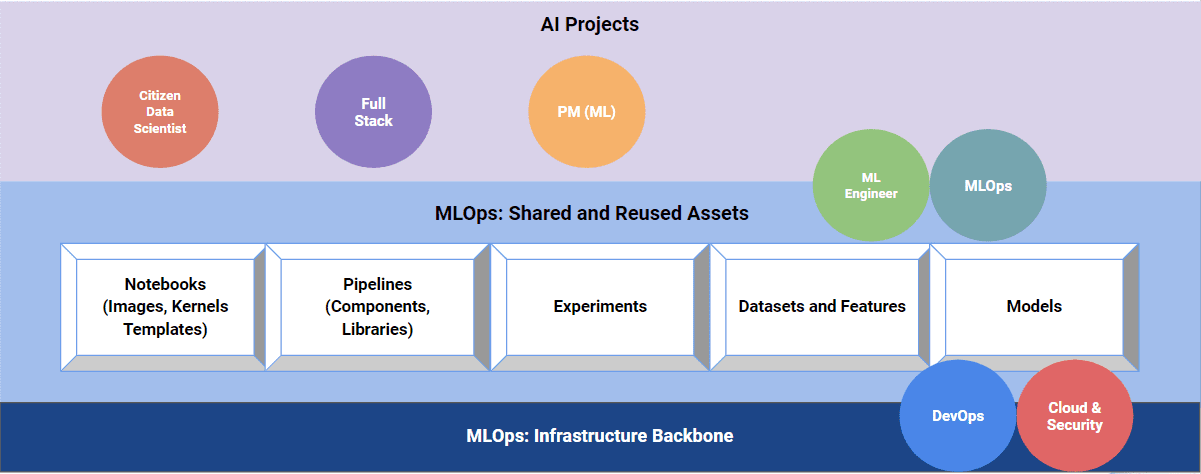
The synergy of specific roles in a balanced AI team and MLOps infrastructure can be visualized as a three-tiered ecosystem:

- The first tier is the infrastructure backbone of MLOps, supported by Cloud & Security professionals, and DevOps. This tier hosts baseline infrastructure components such as access, networking, security, and CI/CD pipelines.
- The second tier is the shared and reused assets of MLOps. This tier is managed by ML engineers and MLOps professionals, and includes notebooks with various images, kernels, and templates; pipelines with components and libraries that are treated as shared assets; experiments; datasets and features; and models. Every asset of this tier can be used and reused by different teams, which accelerates AI development and adoption.
- The third tier is AI projects, which is the responsibility of data scientists, full-stack software developers, and project managers. This tier is independent of the other two, yet is enabled by them.
Note that the Cloud & Security, DevOps, ML engineer, and MLOps roles are placed between tiers, and contribute to each of them. For example:
- Cloud & Security owns the infrastructure backbone, but they are also responsible for the reused assets layer, ensuring that all components and checks are in place.
- DevOps professionals handle the automation parts of the two bottom tiers, from automating builds to managing environments.
- ML engineers have both MLOps infrastructure and project expertise. They are responsible for individual components of the reused asset tier.
- MLOps specialists work hand-in-hand with ML engineers, but they own the entire infrastructure (e.g. Amazon SageMaker, Kubeflow). Their ultimate goal is to stick everything together.
At the same time, citizen data scientists can prioritize the implementation of a specific AI/ML project, working primarily in notebooks. They can own a particular part of the ML pipeline, but are not pressed to get into the weeds of MLOps. Full-stack engineers can work on the regular software portion of an AI product, ranging from UI to APIs. ML-trained project managers work on the product’s implementation.
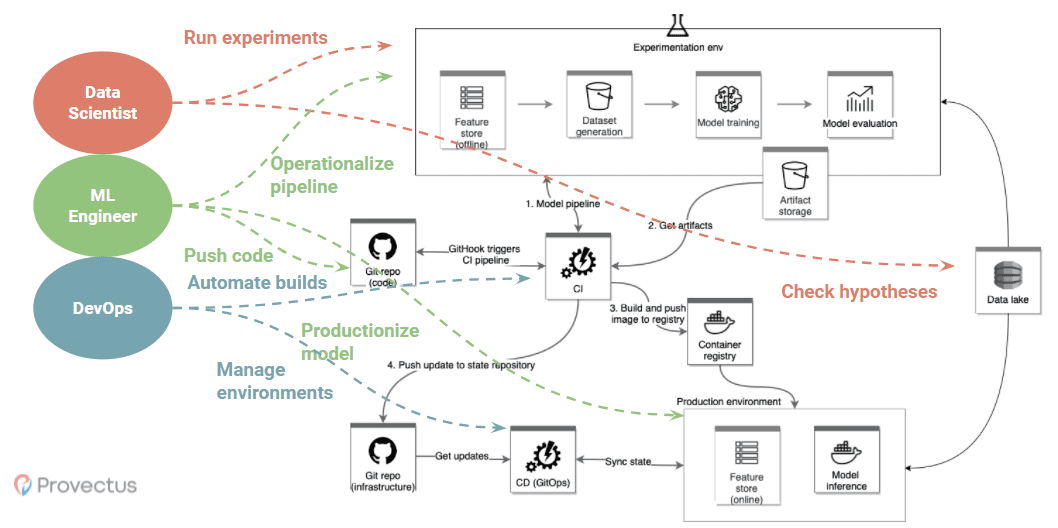
Of course, this is just an abstract representation. Below is a reference infrastructure that demonstrates the infrastructure backbone.
Here we see that data scientists have the tools to work with raw data, perform data analysis in notebooks, and check hypotheses. They can easily run experiments in an experimentation environment managed by ML engineers. The experimentation environment consists of shared and reused components such as feature store, dataset generation, model training, model evaluation, and pre-configured data access patterns. This enables the automation of tedious, error-prone tasks while not pushing data scientists out of their comfort zones.
ML engineers are responsible for productionalizing ML models, meaning that they prepare algorithm code and data pre-processing code to be served in the production environment. They also build and operationalize various pipelines for the experimentation environment.
DevOps professionals help to efficiently manage all of the infrastructure components. For example, in our reference architecture, numbers from one to four demonstrate a CI workflow that is handled by a DevOps.
Summing It All Up
The enablement of MLOps takes time and resources. Most importantly, it requires an understanding that MLOps is as much about people and processes as it is about actual technologies on the ground. It is not overly complicated if you can organize specific roles and functions, matching them to corresponding components of your machine learning infrastructure. Remember: People + Infrastructure = MLOps.At Provectus, we help businesses build state-of-the-art AI/ML solutions while nurturing high-velocity AI teams, supported by a robust infrastructure for MLOps. Kindly reach out to us to start assessing options for your organization!
If you are interested in building high-velocity AI teams and MLOps, we recommend that you also request this on-demand webinar. It is free!
Stepan Pushkarev is CEO, CTO, and co-founder of Provectus, an AI consultancy and solutions provider that help businesses accelerate AI adoption and empower growth. At Provectus, Pushkarev spearheads the vision for industry-specific AI solutions that reimagine the way businesses operate, compete, and deliver customer value. Pushkarev stands as a thought leader with deep expertise in machine learning, cloud computing and distributed data processing systems and has a successful track record of building professional services businesses and founding SaaS startups.