Streamlit Tips, Tricks, and Hacks for Data Scientists
Today, I am going to talk about a few tips that I learned within more than a year of using Streamlit, that you can also use to unleash your powerful DS/AI/ML (whatever they may be) applications.
By Kaveh Bakhtiyari, PhD Candidate in Artificial Intelligence, Data Scientist at SSENSE
The data science team at SSENSE usually builds very complex tools and dashboards. On the other hand, their maintenance was a challenge for the team. It has been more than a year since the SSENSE data science team has been using Streamlit actively. Before employing Streamlit, we were using Dash, Flask, R Shiny, etc. to build our tools and make them available to stakeholders within the company. In October 2019, we started to evaluate the potential power of Streamlit for our projects by understanding its benefits and how to integrate it into our data science infrastructure. At the end of 2019, we began some pilot projects on Streamlit instead of Flask and Dash.
After the evaluation period of Streamlit, we quickly realized that it had a lot of potentials and that it could increase development pace, and decrease the maintenance effort significantly. Besides all the cool features and being easy to work with, Streamlit does not provide the customized behaviors, events, and UI designs that you could get from other web development libraries such as Flask. And eventually, because of the same limitations, it has been much easier to develop clean apps and maintain them easily in the long term. Its uniform UI was also a positive point from my point of view. Firstly, it is clear, clean, and responsive. Secondly, all team members can build tools with uniform designs. But still, how can we provide such custom elements which we had in our Flask applications? Well, the short answer is that it is not quite possible, but we can use some tricks and tips, which can help you to customize more on what you are designing.
Today, I am going to talk about a few tips that I learned within more than a year of using Streamlit, that you can also use to unleash your powerful DS/AI/ML (whatever they may be) applications.
Streamlit is an active open-source project and the community is providing new updates frequently. I personally have bookmarked their Changelog page to keep track of new updates and features. Some of what we are discussing today are not natively supported in
Streamlit (0.82.0), which may not be the case in the future.
Page Config
This feature was initially introduced in the beta version, and it was moved to the Streamlit namespace in version 0.70.0. This cool feature allows you to set the page title, favicon, page layout mode, and sidebar state.
By default, Streamlit sets the page title as the original python file name, with Streamlit favicon. Having this line of code, you can customize your page title, which is very beneficial if your users bookmark your apps. Then favicon allows them to differentiate the apps if they have many apps open in multiple browser tabs. Setting the layout and initial state of the sidebar can also run your app in the way you desire.
Before introducing this functionality, some of these features could only be possible by injecting CSS into the page. For example, if you wanted to make a widescreen, you could do the following:
This line must be the first Streamlit command on your page, and it can only be set once. Regardless of what you set for the layout (either centered or wide), users have control over them in the settings.
Empty component
There are multiple occasions when you want to generate new elements on the page, or you want to replace an existing text or element with another. This is possible using st.empty(). This method creates an empty placeholder on your page, and moving forward you can replace it with any object or text that you want.
The above code initially creates a placeholder on your page, then it writes “this is a sample text.” in that same place, and after that, it replaces it with an input number object.
This is very useful to have dynamic objects on the page, or simply showing the progress of some calculations such as progress percentage.
Query Strings
Setting and retrieving query strings in your Streamlit apps is an experimental feature at the moment. I hope that it will be moved into the main namespace in the future since I personally love this feature. If you have wondered why we need query strings in Streamlit, you are not alone.
When you set your customized inputs in query strings, it makes it possible for the users to share the links with the exact same parameters that they had. Otherwise, they have to enter their parameters as well.
The other use-case that I personally use is to share information between different Streamlit apps. In our team, each data scientist may work on different projects, and we may need to redirect users from one app to another. When we provide the link to the user to navigate to the other Streamlit app, we want to make sure that the user’s experience is as seamless as possible. Therefore, we pass the required parameters to the new app so that it loads with the data and analysis they are looking for.
For example, a few of our tools are related to the products that we have on the website (what a surprise). When they are viewing some analysis on Product 1 on App 1, we want to make sure that once they go to App 2 to get more details or different analysis, it automatically shows Product 1, and the user does not need to reenter the information.
Running Streamlit in a Subfolder
There are scenarios in data science projects that we may need to have our Streamlit apps in a subfolder. In this case, since Streamlit runs the apps from a subfolder, the app does not have access to the libraries in the parent folders. In order to overcome this problem, we may need to either have our Streamlit main app file in the project root or add the root folder into the system path at the beginning of our Streamlit apps.
Sessions
Streamlit is a session-based application. It means that once a user comes to the app, Streamlit assigns him/her a session ID, and other consecutive actions and data transfers are associated with that session. Because of that when you have a process, it won’t affect the other simultaneous users unless you use caching. We will discuss Caching later.
By default, you do not have standard access to the Session controls in Streamlit, and it is not documented officially yet, and it is used for internal purposes only. However, you can still access them and make some benefits by using them.
Streamlit apps are developed in a script-like format. It means that every interaction with the app will trigger the whole code to re-run from start to bottom. This makes Streamlit extremely easy to work with, but at the same time, very tricky to control consecutive events since there is no event handling capability for the developers.
Assume that you have a button (st.button) to start a process, and in the resulting screen, you want to give the user some interactive options to work with, for example, another checkbox, radio button, or simply another button. In this case, when you click on the first button (let’s call it button_run) becomes True when it reruns the whole code. There is nothing wrong, and the app runs smoothly.
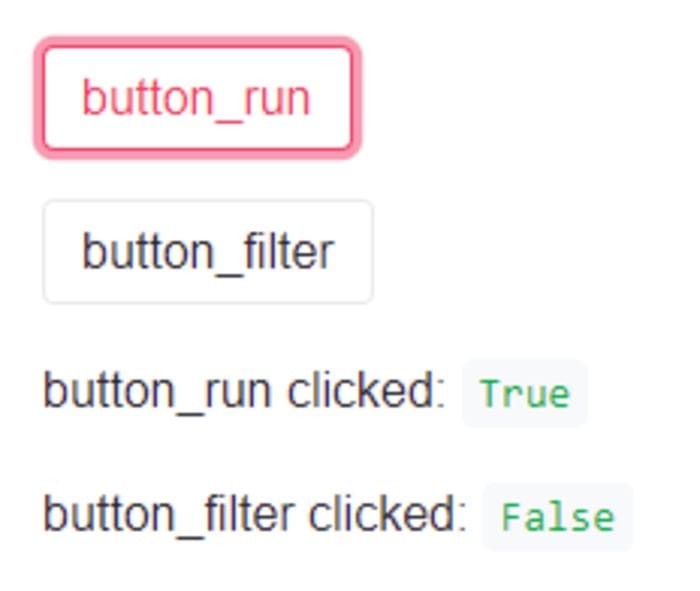
Now, on the resulting page, there is another button (let’s call it button_filter) to filter the results. If you now click on the second button (button_filter), its value becomes True, and Streamlit runs the whole code again. But the problem is that now the first button (button_run) has become False because we did not click on that. In this case, when Streamlit reruns the whole code, there is the assumption that button_run is not clicked, and button_filter is clicked. And it does not remember that button_run was previously clicked. Therefore, button_filter clicked code will never be executed, because button_filter itself was the result of the first button, button_runclick.
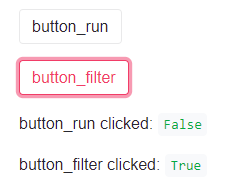
In such cases, we should register the events, so that Streamlit can remember when a user clicks on the first button, and once the next button is clicked, it can understand that these are two consecutive actions and both buttons should be considered as clicked.
You may think that, well, we can save that information in a DB or temporary text file. It is possible, but how do you differentiate the potential different users?
Streamlit has a built-in undocumented Session object that can store some temporary information for every user. In this case, when a user clicks on button_run, we store the clicked event in the Session, and once button_filter is clicked, we can check if button_run was previously clicked to control the correct flow of data.
Here is the session class that you can include in your app:
Once you have the session class added, you can use the session to store and retrieve the information.
SQLAlchemy
SQLAlchemy is one of the standard popular libraries to connect to multiple types of databases such as SQLite, MySQL, etc. SQLAlchemy can be used for multiple platforms as desktop apps, web apps, or even mobile apps. If you have used this library before, you have realized that it is pretty simple, but when it comes to web development it may become a bit tricky. The main challenge of using this library for web applications is to control the number of database connections.
For that purpose, we have separate libraries for Flask (sqlalchemy-flask) and Tornado (sqlalchemy-tornado) which developers can use without any worry. But to my knowledge, we do not have any specific library for Streamlit. Since Streamlit is built upon Tornado, maybe we can use the tornado version, but I personally did not test that.
As you remember, Streamlit is session-based, which means that it runs a separate instance for every user. SQLAlchemy here is no exception. If you’re not careful, Streamlit will create a database connection for every user and maybe for every interaction. Depending on your database, your connections may get rejected if there are so many active connections available. As a result, python may end up with some strange error such as “double free or corruption” and crash your application.
In the Streamlit forum, there is a suggestion of caching the connection, which works well on SQLLite, but not very well on MySQL for example. When you cache your database connection, it won’t be open for an unlimited time, so that you may solve that issue with ttl. In this case, you can make sure that your connection object has expired before hitting a wall on the database side because the connection was already killed. Theoretically, this works fine if you have a very limited number of simultaneous users.
The main problem with caching the connection starts when two users run the code which caches the object at the same time. And at the end, the cached connection may not be the right one, but the expired one since there were two connections created at the same time, but only one was cached.
SQLAlchamy has an object called Session, in which we can create our database connections (engines) and execute our SQL queries. This would check if the new connection is already existing in the pool, and if it is existing, it won’t create a new connection to prevent the database connection saturation issue. In this case, you do not need to use Streamlit caching anymore to store your database connection. The following code snippet will help you understand how to use Session to connect to MySQL.
Remember that, prior to using Session in SQLAlchemy, if you were using engine only, you had to return conn = engine.connect() instead of the session, and you could use df = pd.read_sql(query, conn) to run the query. However, these methods are not working on SQLAlchemy Sessions.
Caching
Streamlit has very thorough, useful documentation on Caching, and honestly, it is one of its most useful features. Not using or misusing it can hugely impact the app performance and load/running time. I do not want to go through the details of caching which is already available in Streamlit documentation but only mentioning a few tips and findings.
App Wide Access
Unlike Session objects, cached objects are app-wide accessible. It means that once you cache information, it is accessible to all users of the app. So it is important not to cache user-specific settings and data, and instead, we can use Session as we discussed earlier.
Caching Parameters
Caching mechanism has few parameters which can control how an object must be cached.
- ttl
<float, None>: This stands for Time-to-Live and sets how long a cached object must be alive. This expiry is set in seconds. - max_entries
<int, None>: Once you start calling a function with different parameters, it starts caching all those variations, and in a short time, it can be a huge amount of cached data. This parameter can set how many variations of a function can be cached, and the old ones will be deleted. This controls and limits the amount of memory consumed. - persistent
<bool>: It is a boolean parameter to set if the cached data must be stored in a hard drive or memory. Just remember that, once you set it to True, Streamlit is pickling the object and storing it on the hard drive, and not all objects (such as SQLAlchamy database connection) can be pickled. So you may get an error for some persistent caching functions. - allow_output_mutation
<bool>: Once the output of a function is cached, if you change the output (mutate), the results will be stored in the cached object and as I mentioned earlier, this is accessible to all users. So the best practice is to avoid changing the cached object. But still, there are some cases where you need to change the cached object directly. In this case, this parameter would allow Streamlit to mutate the cached object. - suppress_st_warning
<bool>: Sometimes Streamlit raises some warnings to the user/developer so that they are aware of some consequences of caching. Setting this to False will stop those warnings. - show_spinner
<bool>: Each time that Streamlit runs functions that are supposed to be cached, you will see a message on your UI saying “Running function_name”. It may not bother you that much unless you have lots of functions. Then you will see all those kinds of messages on your UI. Setting this parameter to False will prevent showing those messages.
The above code only caches the results for 60 seconds, and it only keeps the last 20 variations of this function. It also does not show any warning, does not show you any message on Streamlit UI when running this function.
Since we set allow_output_mutation to False, the following code is not allowed, and we can not update (mutate) the result of the function.
Clearing Cache
There are some cases that you may need to clear the cache programmatically. Clearing all cached data is manually possible through the hamburger menu at the top right of the Streamlit apps, but if you want to do it programmatically, you can use the following undocumented method.
SQLAlchemy Session / Scoped Session
Now that you could successfully connect to the database using SQLAlchemy Session, Scoped Session, and Pooling, you may need to cache your sessions or the functions that are using the database connection. As discussed earlier, since we are using Pool and Scoped Session, we may not need to cache the connection, but we may still need to cache our functions. Below, we are suggesting two recommendations on caching the functions that are using sessions.
The following example would use hash_funcs to identify which parameter of Session must be monitored for hashing.
If the above example is not working, for example in the case of using scoped_session, you can simply ask Streamlit to ignore hashing session as below:
UI Hacks

The simplicity of Streamlit is because you do not need to deal with UI, and it comes with pre-built-in responsive UI elements which will be placed elegantly on your page. Even though in the recent versions, they have provided new beta updates which enable you to create columns and arrange your elements in them, there is not much customization to do with its UI.
When I deploy my apps, there is a wide range of users in the company to work with them. I heavily use caching mechanisms to control the performance and speed of my apps. Some of my functions take a few minutes to run, and I use a caching mechanism to make sure that other users won’t wait again for the same request and will have a high-performance experience with the app. But, if a user clicks on that hamburger menu button at the top right, and selects “Clear Cache’’, it can hugely impact the performance of the app for the other users, until the function caches the results again. Or for example, some of my apps are designed to be shown the best in the wide mode, and if a user selects the “center” mode, it can affect how my app looks.
Besides all those that can directly affect my app, there are other options in the hamburger menu that a normal user may not need to have access to. For example, access to the Streamlit Github, documentation, etc.
There is a proposed idea on Streamlit Github to limit those hamburger menu options once the app is deployed, but until today, this issue is still open, and we can not manage them directly. Therefore, I came with my CSS solution to solve this issue.

In my proposed solution, you can remove (hide) the Streamlit footer, and control the items in the hamburger menu. You simply need to inject the following CSS into your application using st.markdown and allowing “unsafe” HTML codes.
The numbers mentioned above in li:nth-of-type(n) are referring to the item element in the hamburger menu and their order may change in the future updates of Streamlit.

Also, currently, there is an option in the hamburger menu (3rd item) called “Deploy this app”. This item is shown only if the app is accessed via a loopback local IP address (either localhost or 127.0.0.1). If you access your app through your LAN/WAN IP address, this item will not be shown.
Record a Screencast
This feature was introduced in version 0.55.0, and I was personally thrilled by this feature which would allow us to record our apps for training and presentation purposes. Soon, we realized that this feature is not working for the other users accessing our Streamlit apps, and they get the following message upon clicking on that option.

Because of the privacy restrictions implemented and imposed by the browsers, this feature works on the following conditions only:
- Only on recent versions of Chrome, Firefox, and Edge
- Accessing either on
localhostor127.0.0.1 - If it is not being accessed locally, it must be behind an SSL certificate (https)
If you are serving your apps behind a proxy — such as Nginx — and you are aiming to use this feature, make sure that it is secured with an SSL certificate. Currently, Streamlit does not natively support SSL, but it can be deployed behind a proxy with an SSL certificate.
Components
Since the introduction of Streamlit components, developers have started building amazing components which can be served on Streamlit apps. If you would like, you can build your own components using Streamlit Component API. Streamlit has also a component gallery that presents some of the useful and interesting components which are publicly available. Among them, I have selected a few of them that I use to build amazing apps in SSENSE.
ACE Editor
This editor is providing a color-coded editor for different programming languages. I personally use a lot of JSON data in my apps, and I use this editor to view and edit my JSON content. It is amazing since it can also capture my formatting structures and errors.
https://github.com/okld/streamlit-ace
If you are tired of Streamlit standard multi-line text box, this component can be a very good alternative.
Ag-Grid
Streamlit can handle data frames, and it can show them in a table-based format either using st.write or st.dataframe. However, by default, Streamlit does not provide customized controllers on the presentation of your data frame except sorting by clicking on the column names.
Ag-Grid is a grid component that can be imported into Streamlit. Using this component, not only can you present your data frame, but also include links, images, checkboxes, etc into your grid cells as well as filtering the data, searching, aggregate, and grouping them.
https://github.com/PablocFonseca/streamlit-aggrid
If you are dealing with showing data frames a lot, maybe it is time to give Ag-Grid a try to see its huge potential in your applications.
Lottie Animations
Last, but not least, in my list of components is Lottie Animations. If you check lottiefiles.com, you will see thousands of vector-based animations in multiple formats such as JSON, which can be placed in your apps. This component would allow you to serve those Lottie animations by simply giving its JSON file.

https://lottiefiles.com/968-loading
I personally use these animations to show beautifully designed spinners while I am loading or calculating stuff. These animations will give a more vibrant and dynamic look to your next data science project.
Final Words
Here, I presented some tips and tricks on how to develop Streamlit applications. Some of these tricks may become natively available in the future versions of Streamlit, so that we may not need to do the hacks, or on the other hand, they may come with some updates to prevent our hacks. Who knows, but we can enjoy them for now, and hope for new amazing features in Streamlit.
I would also like to thank the Streamlit community for building such an amazing tool.
Bio: Kaveh Bakhtiyari is a PhD Candidate in Artificial Intelligence and a Data Scientist at SSENSE.
Original. Reposted with permission.
Related:
- Deploying Streamlit Apps Using Streamlit Sharing
- Topic Modeling with Streamlit
- Deploying Secure and Scalable Streamlit Apps on AWS with Docker Swarm, Traefik and Keycloak