Answering Questions with HuggingFace Pipelines and Streamlit
See how easy it can be to build a simple web app for question answering from text using Streamlit and HuggingFace pipelines.

Image by Arek Socha from Pixabay
There are so many possibilities of projects to build when you put together a few prominent data science libraries, some good ideas, and Python. This article will show just how easy this can be, and how few lines of code are needed to achieve something interesting.
HuggingFace's Transformers library is full of SOTA NLP models which can be used out of the box as-is, as well as fine-tuned for specific uses and high performance. The library's pipelines can be summed up as:
The pipelines are a great and easy way to use models for inference. These pipelines are objects that abstract most of the complex code from the library, offering a simple API dedicated to several tasks, including Named Entity Recognition, Masked Language Modeling, Sentiment Analysis, Feature Extraction and Question Answering.
We won't give any further explanation of the Transformer pipelines here, but you can read this article for an overview of creating a simple sentiment analysis API app, leveraging HuggingFace's library to do so.
If you don't know about Streamlit, this is the 30,000 foot overview:
Streamlit turns data scripts into shareable web apps in minutes. All in Python. All for free. No front‑end experience required.
You can read a more in-depth introduction to implementing a project with Streamlit here.
Both Streamlit and the Transformer library's pipelines can help make data science projects much easier to implement. Combine the two, and this ease of implementation is even more noteworthy.
Let's have a look at the complete code required to create a functioning web app. This concise script below does everything needed to create the question answering app.
import streamlit as st
from transformers import pipeline
def load_file():
"""Load text from file"""
uploaded_file = st.file_uploader("Upload Files",type=['txt'])
if uploaded_file is not None:
if uploaded_file.type == "text/plain":
raw_text = str(uploaded_file.read(),"utf-8")
return raw_text
if __name__ == "__main__":
# App title and description
st.title("Answering questions from text")
st.write("Upload text, pose questions, get answers")
# Load file
raw_text = load_file()
if raw_text != None and raw_text != '':
# Display text
with st.expander("See text"):
st.write(raw_text)
# Perform question answering
question_answerer = pipeline('question-answering')
answer = ''
question = st.text_input('Ask a question')
if question != '' and raw_text != '':
answer = question_answerer({
'question': question,
'context': raw_text
})
st.write(answer)
Now let's get the web app up and running. Assuming you have saved the above script as nlp_question_answering.py, this will do it:
streamlit run nlp_question_answering.py
This should open up your browser and the web app. For demonstration purposes, I will click the "browse files" button and select a recent popular KDnuggets article, "Avoid These Five Behaviors That Make You Look Like A Data Novice," which I have copied and cleaned of all non-essential text. Once this happens, the Transformer question answering pipeline will be built, and so the app will run for a few seconds.
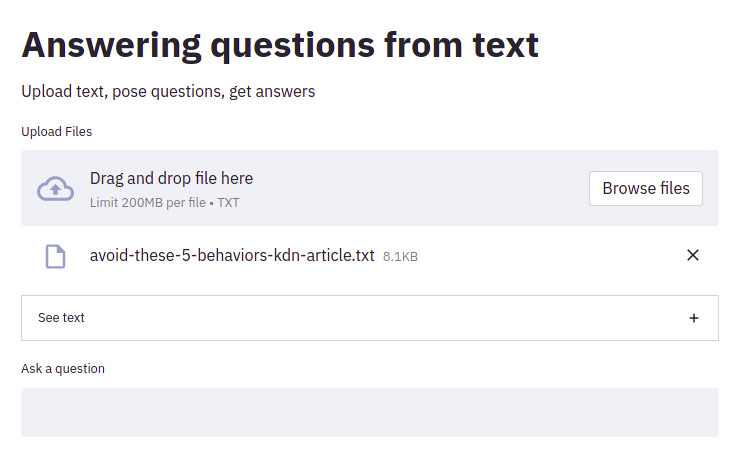
You can read the entire article if the topic is of interest (it's very good); otherwise, here is a relevant excerpt:
Unless it’s a focus group with people that are representative of your customer base (I even have doubts about survey results from focus groups, but that’s another topic), 30 data points usually won’t give you any robust insights.Now let's ask a question, using the "ask a question" field, and check the response:
What usually won’t give you any robust insights?
{
"score":0.9823936820030212
"start":1891
"end":1905
"answer":"30 data points"
}
And we have a fairly confident answer to our first question. Excellent!
Now have a look at this excerpt:
Try this instead: Talk to your stakeholders before building any data product. Understand the business’ needs at the current stage: If it’s a startup, I bet your stakeholder won’t care too much about the format and color of the data visualizations you build but wants to instead focus on the accuracy of the data behind the visualizations and insights from them. Similarly, truly understand the audience and use case; for example, you would spend more time on a polished and simple user interface if the data product is intended to be used regularly by non-technical audiences.Let's ask a few questions related to this second excerpt and check out the responses.
Who should you talk to before you start building any data products?
{
"score":0.7892400026321411
"start":6930
"end":6947
"answer":"your stakeholders"
}
The stakeholder will want to focus on what?{
"score":0.3485959768295288
"start":7195
"end":7264
"answer":"accuracy of the data behind the visualizations and insights from them"
}
What should you truly understand?{
"score":0.599153995513916
"start":7294
"end":7319
"answer":"the audience and use case"
}
You can see the varying confidence scores for the different answers to the questions we posed. Try out the app for yourself, and see what happens when you ask questions it doesn't have answers for.
I hope this has been a helpful demonstration of how easy it is to patch together Python libraries with some good ideas. With some added layers of complexity, such projects can be useful additions to a portfolio of projects to share with other data scientists or prospective employers.
Matthew Mayo (@mattmayo13) is a Data Scientist and the Editor-in-Chief of KDnuggets, the seminal online Data Science and Machine Learning resource. His interests lie in natural language processing, algorithm design and optimization, unsupervised learning, neural networks, and automated approaches to machine learning. Matthew holds a Master's degree in computer science and a graduate diploma in data mining. He can be reached at editor1 at kdnuggets[dot]com.