The Significance of Data-centric AI
How a systematic way of maintaining data quality can do wonders to your model performance.

Source: https://www.youtube.com/watch?v=06-AZXmwHjo&ab_channel=DeepLearningAI
Andrew Ng is probably the reason most aspiring data scientists find it easy to break into this field. The ease with which he explains the most technical concepts is unparalleled.
I look up to him for reasons more than one, but primarily my technical writing skills derive a major motivation from him i.e. to make it easy for everyone to understand the difficult jargon. He literally makes learning data science an art rather than a tedious gamut of the vast curriculum that often gets overwhelming.
I recently watched the recording where he introduced the difference between model-centric and data-centric AI. This was something I had observed in the ML projects I have delivered, however, could not talk about it in principle with such detail, thanks to the imposter syndrome. But when Andrew explained the importance of working more on data rather than frantically trying the cutting edge and advanced algorithms, it totally resonated with me.
I am writing this article with the intent to keep the notes and summary from his talk, maybe you find it useful too.
The current model-centric state of the data science projects tends to hit the wall beyond a certain point. There is only little you can do with trying multiple sophisticated models when your data is not allowing you to go further.
The whole spectrum of experimenting with different models and checking what works best for the given data and business case does not keep the ball rolling for long. If your best model does not meet the metric that the business wants to be able to give a go-ahead for the project, understand that it is time to go closer to the data and dig deeper as to what part of the data is not qualified enough to make it to the training set. This is the part where you analyze if there are some specific attributes of the test data where your predictions are far from reality.
Data-centric Approach
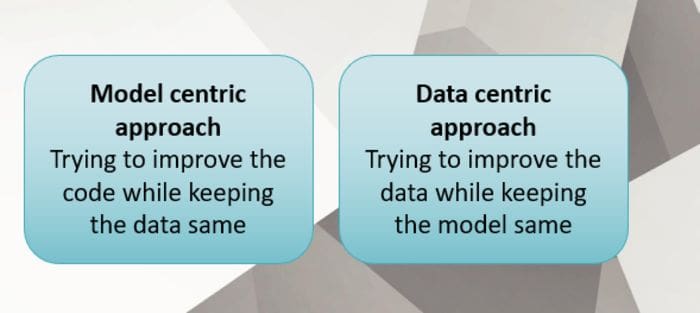
Source: created by the author using PowerPoint
Let us see what all can we do with data under 'data-centric approach:
Data label quality: It could be entirely possible that the different labelers gave different labels to a different section of data. If there is inconsistency in terms of how the human experts see a particular problem, there is a slim chance that machines will pick it either.
Data Augmentation: Generate the data that your model has not seen during the training time. Adding data is not the only solution always. Removing the noisy observations leading to the high variance also helps the model's ability to generalize better on the unseen data.
Data Sources: I have struggled a lot with this one in particular, as the field I work in involves multiple data sources that undergo rigorous data understanding, discussions with Subject Matter Experts (SME), finding the right business logic to join them together and create one flat structure for training the machine learning models. There are myriad ways things can go wrong here in terms of schemas, data accumulation, the business logic to make the data coherent, and data storage.
Feature Engineering: Data quality involves improving both - the input data as well as the target/labels. Feature engineering plays a critical role in terms of introducing features that might not exist in raw form, but the curated features can add to noteworthy improvement.
How Much Data is Sufficient?
We often try to find the right amount of data needed to build meaningful models. The perception of 'the more, the merrier' is not necessarily always true. Quality of data supersedes the quantity of data. One can have millions of rows in the dataset with a lot of noisy observations that lead to obscured learning process. On the other hand, the smaller dataset but with good quality labels tends to give much better results.
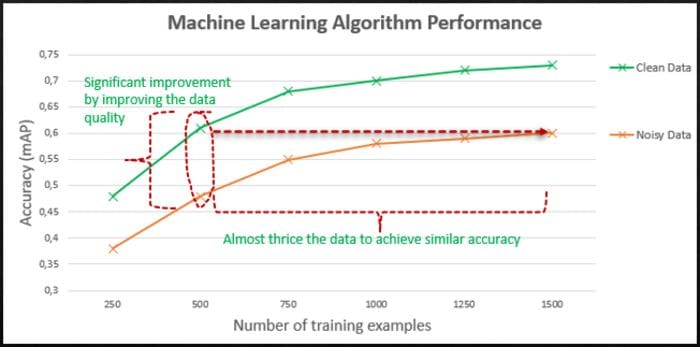
Source: Author has highlighted in red and green + https://www.youtube.com/watch?v=06-AZXmwHjo&ab_channel=DeepLearningAI
Key Takeaways

Source: mentioned in references
- Work on improving the data quality; cover the corner cases
- Consistent labels are the key
- Assess the samples where the model is drifting in production. Evaluate the errors by categorizing the subset of the data responsible for such deviation. Try to improve that piece of data.
- Improving data quality can limit the need for exorbitant data samples. Lesser but meaningful data observations will aid faster learning
My 2 Cents
Being an industry practitioner, I agree that we need not restrict ourselves unidirectionally in the model experimentation phase. Once, you have the baseline model and a decent understanding of how your data behaves across candidate models, do not push your data to more advanced models. Pick the best-performing model and let it guide you to pick the instances where your best model is failing to perform.
Now, analyze those data points and check for corner cases, whether your training data has enough samples to learn for such cases. If not, maybe your next best bet is to synthetically create those data points that need to be available during model training to be able to better perform on previously failed predictions. Or modify the ones that exist in the current dataset but are not legit entries.
There is no thumb rule to choose between model-centric and data-centric experimentation approaches, as is typically the case for the majority of data science projects. However, the talks from the AI/ML experts like the one Andrew shared definitely helps set up a framework and guiding principles for the data scientists to think along, but we all have to iterate, experiment, and learn on our own for long before we are able to build that intuition for future projects.
References:
- https://www.youtube.com/watch?v=06-AZXmwHjo&ab_channel=DeepLearningAI
- https://www.youtube.com/watch?v=Yqj7Kyjznh4&ab_channel=DeepLearningAI
Vidhi Chugh is an award-winning AI/ML innovation leader and an AI Ethicist. She works at the intersection of data science, product, and research to deliver business value and insights. She is an advocate for data-centric science and a leading expert in data governance with a vision to build trustworthy AI solutions.