How causal inference lifts augmented analytics beyond flatland
In our quest to better understand and predict business outcomes, traditional predictive modeling tends to fall flat. However, causal inference techniques along with business analytics approaches can unravel what truly changes your KPIs.
By Michael Klaput, Chief Science Officer and Co-Founder at Kausa.

If the world was two-dimensional, life would be very odd indeed. Think about it: The earth would not be a sphere but a circle — just like all other stars and planets in a 2D universe. Beings would be flattened, too, navigating a plane landscape and existence. For example, to pass somebody on the street, you would have to jump over that person as there would be no depth whatsoever. For the same reason, to just look behind you, you would literally have to turn yourself upside down. Fortunately, this is not the world we live in. But unfortunately, this is the basis on which most enterprises are run today — perhaps even yours. In any technology-driven business, the quality of your decision-making is inevitably based on the quality of your data insights. However, in too many companies, those ’insights’ are effectively two-dimensional: flat, impractical, and hopelessly inconclusive.
Businesses usually measure their performance in terms of a KPI. It has thus become an objective in data analytics to find the best predictive models of future KPI values given historical data. While these models might perform surprisingly well, extracting value out of them is just as hard. Aside from a lack of explainability, this is also because predictive models are unable to capture reality and are limited to low-dimensional explanations. In this article, we will give two arguments why this is the case based on bad scaling and unrealistic assumptions made in most predictive models.
But why bother? It is not the well-performing model that improves business performance. Instead, the only way to improve a business is through decisions, which should ultimately be done by a human. The objective of data analytics in business should be to inform decisions by uncovering insights. Unfortunately, these are hidden in your data like needles in a haystack. This far from trivial problem motivated a relatively young branch of data analytics has been coined augmented analytics and has been pushed in a recent Gartner report [1].

Figure 1. Cover of Flatland: a romance of many dimensions / with illustrations by the author, A Square. By Edwin Abbott Abbott (1838-1926). Published: London: Seeley & Co., 1884. *EC85 Ab264 884f Houghton Library, Harvard University
We want to challenge the perception that predictive models should be the default option used to inform business decisions. They introduce a costly detour in the search for insights and might even render it practically infeasible. We will highlight in a simple problem that predictive modeling can offer only little aside from a massive overhead. Instead, we will try to mimic how a business analyst would operate. This will naturally bring us to methods from causal inference.
The Impactful Change
We will consider the problem of diagnosing errors in regression models in big data scenarios. Most of the readers should have encountered the following scenario:
Figure 2. Key performance indicator actual vs. prediction using a single model.
Clearly, there has been an impactful change in the KPI that seems to persist for the time being. On the technical side, a reasonable reaction would be to retrain your predictive model on the data after the change point. Do you agree? If so, maybe keep this in mind.
Figure 3. Key performance indicator actual vs. prediction using two models.
The good news is that your model seems to be accurate. The bad news is that your manager will inevitably ask what happened to the KPI. But do not be afraid. This is an ideal situation for proving your value to the company. Can you identify the reason behind this change? Can you uncover insights that will inform the correct decision?
The Quest of Why
Let's say your company’s dataset looks something like this:
import pandas as pd
df = pd.read_csv("..\\dataset\\ecommerce_sample.csv")
df.head()
Table 1. Sample company data.
Let us further assume that you are dealing with the simplest case: The KPI values of data points before and after the jump are perfectly fit using a linear regression model. Here, you are dealing with categorical data which you need to handle appropriately to use in the regression. A standard approach for this is one-hot encoding of categorical values: for each category value, you introduce a feature that can be either true or false. For example, in the dataset above you would define the feature
customer_country = Germany.
To finally enable feature selection, it is necessary to use a form of regularisation. Here, you will use lasso regularisation (with ten-fold cross-validation).
After training two lasso regularised linear regression models, one before and one after the jump, you can look at a ranked list of feature weight differences between these.
from sklearn.linear_model import LassoCV
from bokeh.io import show
from bokeh.plotting import figure
#get kpi_axis
kpi_axis = 'kpi'
time_axis = 'time'
df[time_axis] = pd.to_datetime(df[time_axis],format = '%d/%m/%Y')
y_before = df[df[time_axis] <= '2019-09-11'][kpi_axis] y_after = df[df[time_axis] > '2019-09-11'][kpi_axis]
#one-hot encoding categorical features
for col in df.drop([kpi_axis,time_axis],axis=1).columns:
one_hot = pd.get_dummies(df[col])
df = df.drop(col,axis = 1)
df = df.join(one_hot)
X_before = df[df[time_axis] <= '2019-09-11'].drop([kpi_axis,time_axis],axis = 1).to_numpy() X_after = df[df[time_axis] > '2019-09-11'].drop([kpi_axis,time_axis],axis = 1).to_numpy()
#training left and right
regression_model_before = LassoCV(cv = 10)
regression_model_after = LassoCV(cv = 10)
regression_model_before.fit(X_before,y_before)
regression_model_after.fit(X_after,y_after)
#plotting results
features = df.columns
dweights =regression_model_after - regression_model_before
index = np.argsort(-abs(dweights))
x_axis = features[index[0:3]].to_list()
p = figure(x_range=x_axis,title = "Feature weights difference",plot_width=1000)
p.vbar(x=x_axis, top=(abs(dweights[index[0:3]])),width = 0.8)
show(p)
Figure 4. Feature weights using one-hot encoding.
It looks like subgroups such as android customers or customers older than 46+ performed differently before and after the jump. Great, looks like you found the reasons for the KPI jump … or did you?
The Curse of Dimensionality
In fact, this is a more non-trivial situation than we have appreciated so far. Imagine presenting this to the KPI owner. They will be very happy that you have delivered them reasons for the KPI change, and they will now be wondering about what to do based on this information. It will automatically lead them to questions like the following:
“Are the actual drivers for the KPI change all android-tv customers, all customers older 46, and all customers who made a purchase before? Maybe it could be the repeat customers older than 46 and the android-tv customers… or the Android-TV customers who purchased something before? Worse, are there maybe other combinations of features which you have missed?”

Figure 5. Kausa - Because you know better.
Therefore, to be able to more confidently answer such questions, you would have to repeat your regression analysis with more complex one-hot encoded features … now representing finer subgroups than before. Thereby, you are searching among deeper subgroups of the dataset, see Figure 6, with new features like
customer_age = 46+ and first_order_made = yes, customer_age = 18−−21 and first_order_made = no.
Again these subgroups enter via one-hot encoding. This is obviously problematic, as you are now falling victim to the curse of dimensionality. It is the era of big data, and you just increased your number of features by a factorial amount [2]. A piece of code that can be used to generate these refined subgroups is
def binarize(df,cols,kpi_axis,time_axis,order):
cols = cols.drop([kpi_axis,time_axis])
features = []
for k in range(0,order):
features.append(cols)
fs = []
for f in itertools.product(*features):
# list(set(f)).sort()
f = np.unique(f)
fs.append(tuple(f))
fs = tuple(set(i for i in fs))
print(fs)
for f in fs:
print(len(f))
states =[]
for d in f:
states.append(tuple(set(df[d].astype('category'))))
for state in itertools.product(*states):
z = 1
name = str()
for d in range(0,len(f)):
z = z*df[f[d]]==state[d]
name += f[d] + " == " +str(state[d])
if d<len(f)-1:
name += " AND "
df[name] = z
for d in cols:
df = df.drop([d],axis = 1)
return df
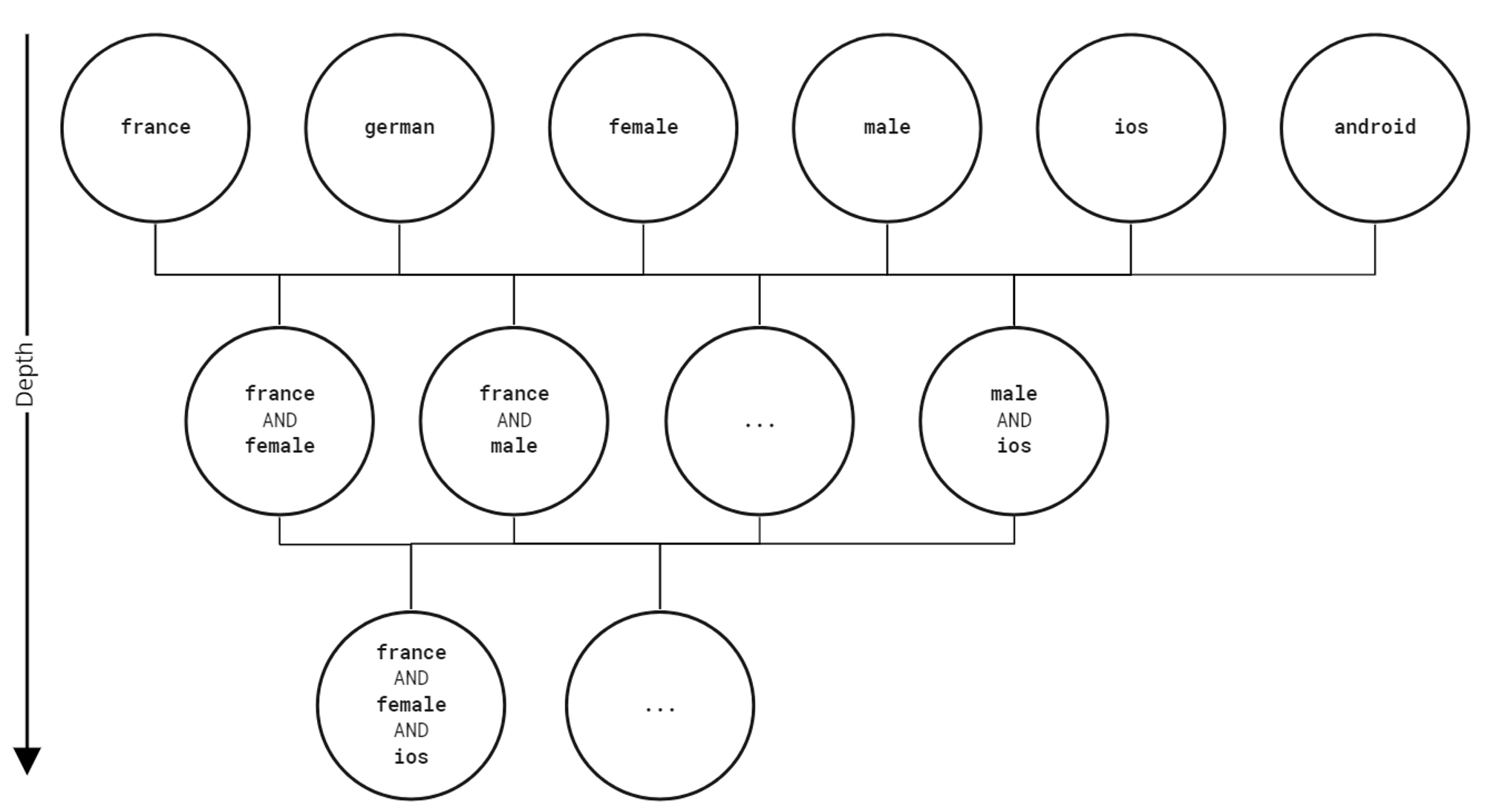
Figure 6. Subgroup depth.
Remember that linear regression is based on an inversion of a covariance matrix among all features - which scales
O(d3),
with d being the number of features, i.e. in our case the number of possible subgroups. This introduces significant opportunity cost in comparison to non-predictive feature selection methods - as will be discussed later.
df = pd.read_csv("..\\dataset\\ecommerce_sample.csv")
df[time_axis] = pd.to_datetime(df[time_axis],format = '%d/%m/%Y')
#get kpi_axis
kpi_axis = 'kpi'
time_axis = 'time'
y_before = df[df[time_axis] <= '2019-09-11'][kpi_axis] y_after = df[df[time_axis] > '2019-09-11'][kpi_axis]
#one-hot encoding categorical features
df = binarize(df,df.columns,kpi_axis,time_axis,3)
X_before = df[df[time_axis] <= '2019-09-11'].drop([kpi_axis,time_axis],axis = 1).to_numpy() X_after = df[df[time_axis] > '2019-09-11'].drop([kpi_axis,time_axis],axis = 1).to_numpy()
#training left and right
regression_model_before = LassoCV(cv = 10)
regression_model_after = LassoCV(cv = 10)
regression_model_before.fit(X_before,y_before)
regression_model_after.fit(X_after,y_after)
#plotting results
features = df.columns
dweights =regression_model_after - regression_model_before
index = np.argsort(-abs(dweights))
x_axis = features[index[0:3]].to_list()
p = figure(x_range=x_axis,title = "Feature weights difference",plot_width=1000)
p.vbar(x=x_axis, top=(abs(dweights[index[0:3]])),width = 0.8)
show(p)
Figure 7. Feature weights of intersections using one-hot encoding.
After some time, your computation finishes. While your earlier computation took just 0.1 seconds, searching for third-order features already took over a minute. But it seems to be worth it. You find that the number of groups driving the KPI change was actually one, as in Figure 7. Presenting this insight to your manager, he could quickly point to an update that directly affected the subgroup you reported.
By refining the subgroup, you could render it actionable
While your regression approach finally worked out - it took extremely long to compute, resulting in opportunity cost to your company. In a realistic scenario of big data, your approach would have failed horribly. Additionally, original sets containing only shallow subgroups painted an incorrect picture. Only after refining sets and enormous computational effort could you pinpoint the actual subgroup that drove the jump in the KPI.
This begs several questions:
- Do you actually need to learn a predictive model to answer why the jump happened?
- How can you reduce opportunity costs?
- How can you find subgroups at the appropriate level of granularity?
- Is it economical to retrain models at every jump for this piece of information?
While answering all these questions is out-of-scope for this post, we will offer a new point-of-view that can help to resolve these issues. For this, we will develop an approach to feature selection that improves on linear regression. Augmented analytics depends on it.
Learning from Business Analysts and Causal Inference
Let’s take a step back… what happened here? You started off with a predictive model, and you saw that it could neither predict nor explain the observed jump in the KPI. Why is that? Because predictive models are unable to capture reality. They assume that all data is independently and identically distributed [3]. However, in real-life applications, this is often incorrect, as this example shows. Data before and after the jump was generated under different conditions. You even intuitively made use of this fact, when you used two separate predictive models, which (after some tricks) helped us to uncover the reason for that jump.
As you had to give up on prediction and ultimately did not predict anything, what did the prediction models actually do for you? If you think about it, the key is that you are not interested in predicting the KPI as a function of all possible subgroups - you are interested in subgroups affecting the KPI! Thus, to search for insights at deeper levels, you have to get away from predictive modeling. This is where the data scientist can learn from the business analyst.
A business analyst searches for insights through dashboards containing meaningful summaries of data. Instead of correlating all features together, as in the regression approach above, the business analyst will try to pinpoint what changes happened in the data based on summaries (like means, histograms, or metrics) by iteratively filtering the data for different conditions. Most importantly, the business analyst will never have to look at all features at once. How do you teach a machine to do that? How can you learn from a business analyst?
Let us formalise the above in mathematical notation. Let X be a subgroup, e.g.
X = customer_age = 46+ and first_order_made = yes
and
f(KPIbefore, KPIafter)
some summary of the KPI distributions before and after the jump in the KPI. Then, you introduce conditional summaries
f(KPIbefore, KPIafter ∣ X)
where you compute summaries of subsets of KPI values for which X is true. All that our method needs to do now, is to compute conditional summaries for each subgroup and rank them. I want to stress, that in practice these abstract summaries can be objects as means, histograms etc.
The procedure detailed above is actually a common technique from causal inference [4]. You thereby implicitly changed our point of view. Now, you consider the mysterious jump in the KPI as an intervention that is now assumed to have happened due to external or internal treatments. An example for an external treatment might be the holiday season, an internal treatment might be an ad campaign, a change in pricing, or, as in our case, a software update. You are thus explicitly lifting the wrong assumption that all data is independently and identically distributed. You are now searching for subgroups that are causal to the change in KPI.
The Quest of Why, Revisited
Now that you have a model of how a business analyst operates, let us proceed with the actual implementation. For now, you will use a standard summary used in causal inference called Conditional Average Treatment Effect (CATE) [5], for which our summary becomes
f(KPIbefore, KPIafter ∣ X) = E[KPIafter ∣ X] − E[KPIbefore ∣ X]
The CATE corresponds to the change in the mean of the KPI, conditioned on that subgroup X is true. Ranking by magnitude then gives us the correct subgroup as a result. To detect multiple subgroups, we repeat this procedure after removing the best performing subgroup after each iteration:
df = pd.read_csv("..\\dataset\\ecommerce_sample.csv")
df[time_axis] = pd.to_datetime(df[time_axis],format = '%d/%m/%Y')
#get kpi_axis
kpi_axis = 'kpi'
time_axis = 'time'
y_before = df[df[time_axis] <= '2019-09-11'][kpi_axis] y_after = df[df[time_axis] > '2019-09-11'][kpi_axis]
df = binarize(df,df.columns,kpi_axis,time_axis,3)
df_before = df[df[time_axis] <= '2019-09-11'] df_after = df[df[time_axis] > '2019-09-11']
features = copy(df.drop([time_axis,kpi_axis], axis=1).columns)
K = 3 #number of subgroups to detect
subgroups=[]
score=[]
for k in range(0,K):
CATE = []
y_before = df_before[kpi_axis]
y_after= df_after[kpi_axis]
#compute CATEs for all subgroups
for d in features:
g = df_before[d] == True
m_before = np.mean(y_before[g])
g = df_after[d] == True
m_after = np.mean(y_after[g])
CATE.append(m_after-m_before)
#find subgroup with biggest CATE
index = np.argsort(-abs(np.array(CATE)))
subgroups.append(features[index[0]])
score.append(abs( CATE [index[0]]))
#remove found subgroups from dataset
df_before = df_before[df_before[features[index[0]]] == False]
df_after = df_after[df_after[features[index[0]]] == False]
features = features.drop(features[index[0]])
p = figure(x_range=subgroups,title = "Conditional Average Treatment Effect",plot_width=1200,)
p.vbar(x=subgroups, top=score,width = 0.8,color='black')
show(p)
Figure 8. CATE Scores using the one-hot encoding of intersections.
This takes a fraction of the cost of our predictive model. The computation for first-order features took just 0.02 seconds, searching for third-order features took less than a second.
Let us take a step back and compare this approach with the earlier one based on regression and what their respective objectives are. Feature selection via regression answers the question: ” Which subgroups best predict your KPI?”. While taking the view of causal inference answers the question: “Which subgroups had the biggest causal effect on the KPI?”. Comparing run-times of a naive implementation of CATE with the optimised sklearn implementation of linear regression in Figure 9, we find that they lie order of magnitudes apart. This makes it clear that these questions, while superficially similar, have fundamental differences.
Figure 9. Log-runtime over subgroup depth of linear regression (sklearn) vs. CATE for exhaustive subgroup search.
Conclusion
Predictive models have strong shortcomings as means to understand KPI changes, especially in multi-dimensional contexts. These models fundamentally answer the wrong questions under the wrong assumptions. Instead, business analytics focuses on why did something happen rather than what will happen. Having their mind free of the auxiliary task of predicting future KPI values, analytics finds reasons in the data to understand why the KPI changed, trying to find the answers for the right question.
Be wary next time you want to explain anything. Firstly, you should ask the right question. In addition, multi-dimensional contexts require a scalable technique based on causal inference and business analytics methods. This is our mission at Kausa: scale business analytics logic and couple it with causal inference to provide the right answers to KPI changes.
PS: Code and data to reproduce results from this article are available in our GitHub repository [6].
Original. Reposted with permission.
Bio: Michael Klaput is the co-founder and CTO at Kausa (www.kausa.ai), former VP Quantitative Analyst at Bank of America Merrill Lynch, and Ph.D. in Theoretical Physics Oxford University.
Related: