3 Data Acquisition, Annotation, and Augmentation Tools
Check out these 3 projects found around GitHub that can help with your data acquisition, annotation, and augmentation tasks.
Being able to quickly get your hands on datasets for testing algorithms and building models has become a vital skill for contemporary data scientists and machine learning engineers. Being able to move a semi-complete dataset to one that is fully annotated, fleshed out with additional augmented data, and ready to move on to building models with is equally important.
For those of us holding incomplete data, and needing some help getting it from "not quite" to "let's go!", here are 3 projects found around GitHub that can help with your data acquisition, annotation, and augmentation tasks.
1. Google Images Download
Need to build yourself a custom image dataset for your project? Google Images Download might be able to help.
Python Script to download hundreds of images from 'Google Images'. It is a ready-to-run code!
Feed your requirements into either the command line or call it from within a Python script, and Google Images Download will... download Google images. Read the documentation here and great scraping, but remember to do so within the confines of Google terms of use and copyright laws.

2. LabelImg
Once you have acquired yourself some images, annotation might become a concern. This is where LabelImg comes in.
LabelImg is a graphical image annotation tool and label object bounding boxes in images.
Built with Python and Qt, LabelImg is a standalone application with a graphical user interface meant for annotating images.
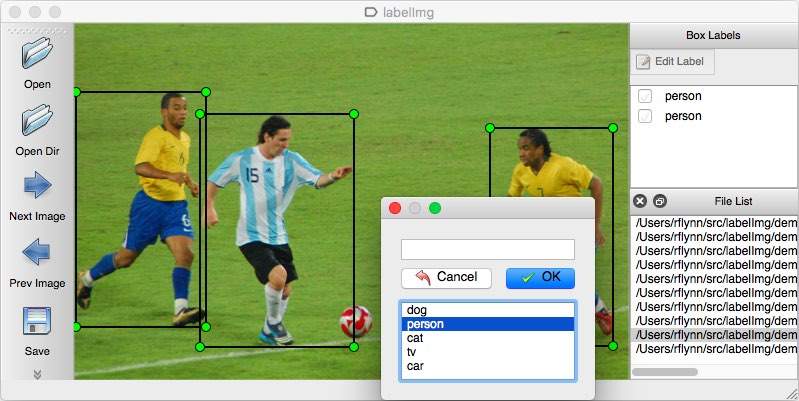
Annotations are saved as XML files in PASCAL VOC format, the format used by ImageNet. Besides, it also supports YOLO and CreateML formats.
The GitHub repo has installation and usage info, and LabelImg seems to be an application you can get up and running — and using — quickly, allowing you to maximize time spent working on your dataset. Happy annotating!
3. TextAttack
Turning our attention from computer vision dataset tasks to natural language processing, let's have a look at what TextAttack can do.
TextAttack is a Python framework for adversarial attacks, data augmentation, and model training in NLP.
TextAttack has a number of built-in recipes for augmenting text data, including: replacing words with WordNet synonyms; words with neighbors in the counter-fitted embedding space; substituting, deleting, inserting, and swapping adjacent characters; contraction/extension and by substituting names, locations, numbers; and more.
While herein we are highlighting the use case of using TextAttack to augment a dataset, here are the full breadth of its capabilities:
- Understand NLP models better by running different adversarial attacks on them and examining the output
- Research and develop different NLP adversarial attacks using the TextAttack framework and library of components
- Augment your dataset to increase model generalization and robustness downstream
- Train NLP models using just a single command (all downloads included!)
To get started augmenting your NLP dataset — or utilize any of the other features of TextAttack — have a look at the full documentation, which you can find here.
Related:
- Agile Data Labeling: What it is and why you need it
- Trending Deep Learning Github Repositories
- GitHub Copilot Open Source Alternatives