Agile Data Labeling: What it is and why you need it
The notion of Agile in software development has made waves across industries with its revolution for productivity. Can the same benefits be applied to the often arduous task of annotating data sets for machine learning?
By Jennifer Prendki, Founder and CEO @ Alectio, Machine Learning Entrepreneur.
The concept of agility is certainly a popular one in technology, but not one that you would naturally associate with data labeling. And it’s fairly easy to understand why: “Agile” typically inspires efficiency. Labeling, however, is hardly discussed in ML circles without triggering a flurry of frustrated sighs.

Figure 1: The Agile Manifesto describes a set of ‘rules’ that software developers believe would make them more productive.
To understand how Agile became so widely adopted, you need to go back to its origins. In 2001, a group of 17 software engineers met at a resort in Utah to brainstorm how to make their industry better. They thought the way projects were managed was inappropriate, inefficient, and overly regulated. So, they came up with the Agile Manifesto, a set of guidelines they thought could improve the throughput (and the level of sanity!) of software engineering teams. The Agile Manifesto was an outcry against a lack of process that was impeding progress. And in many ways, this is exactly what is needed for data labeling.
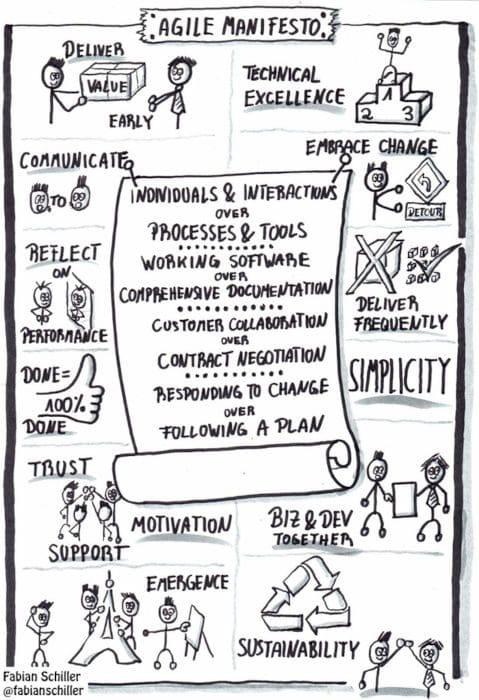
Figure 2: A deep dive into the Agile Manifesto and its core principles.
Back to Machine Learning. No question about it: the progress we have accomplished in the field over the past decades is simply mind-boggling. So much so in fact that most experts agree that the technology has evolved too fast for our laws and institutions to keep up with. (Not convinced? Just think of the dire consequences that DeepFakes could have on world peace). Still, despite the explosion of new AI products, the success of ML projects boils down to one thing: data. If you don’t have the means to collect, store, validate, clean, or process the data, then your ML model will remain a distant dream forever. Even OpenAI, one of the most prestigious ML companies in the world, decided to shut down one of their departments after coming to terms that they didn’t have the means to acquire the data necessary for their researchers.
And if you think all it takes is to find an open-source dataset to work with, think again: not only are the use cases for which relevant open-source data exists few and far between, most of these datasets are also surprisingly mistaken-ridden, and using them in production would be nothing short of irresponsible.
Naturally, with ever better and more affordable hardware, collecting your own dataset shouldn’t be much of a problem anymore. The core issue, though: those data aren’t usable as-is because they need to be annotated. And in spite of the way it looks, that is not an easy task.

Figure 3: Annotating all planes in this image for object detection or object segmentation use cases could take well over an hour, even for a seasoned expert. Imagine having to do that for 50,000 images and having to guarantee the quality of the annotations without help.
Labeling data is daunting. For many ML scientists, annotating data accounts for a ridiculously large portion of their workload. And while annotating data yourself is not an enjoyable task for most people, outsourcing the process to a third party might be even more tedious.
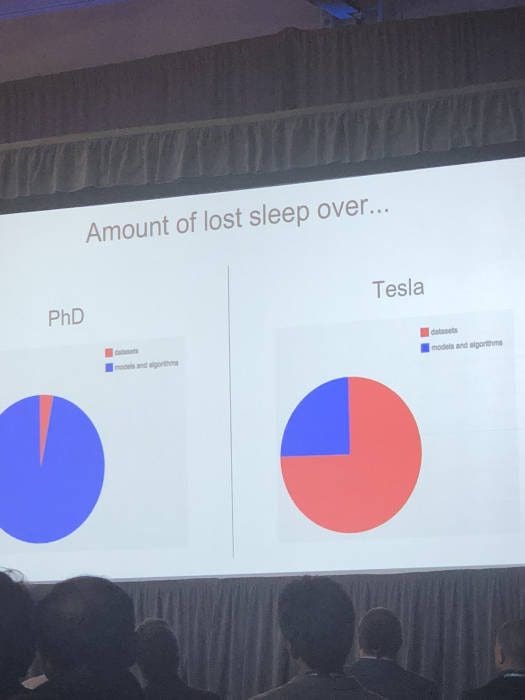
Figure 4: A picture of one of Andrey Karpathy’s slides at Train AI 2018, where he described the time he and his team spent on data preparation at Tesla.
Imagine that you had to explain to a complete stranger you never met and can’t directly communicate with what you consider a toxic tweet, a relevant result to a search query, or even a pedestrian on a picture. Imagine ensuring that hundreds of people will understand your instruction the exact same way even though they might each have different opinions and backgrounds and that they might know nothing of what you are trying to achieve. That’s exactly what outsourcing your labeling process is about.

Figure 5: Should the people on the ad be labeled as people?
What does this have to do with Agile? Well, if you haven’t guessed yet, the growing frustration among ML scientists regarding labeling might be our cue that it is time to rethink how we get things done. It’s time for the Agile Manifesto of Data Labeling.
The Agile Manifesto of Software Development fundamentally boils down to one foundational concept: reactivity. It states a rigid approach doesn’t work. Instead, software engineers should rely on feedback–from customers, from peers. They should be ready to adapt and learn from their mistakes to ensure they can meet their final goals. That’s interesting because the lack of feedback and reactivity is precisely the reason why teams are afraid to outsource. It's the main reason why labeling tasks often take a ridiculous amount of time and can cost companies millions of dollars.
A successful Agile Manifesto of Data Labeling should begin with the same principle of reactivity, which has been surprisingly absent from the narrative of data labeling companies. Successful preparation of training data involves cooperation, feedback, and discipline.
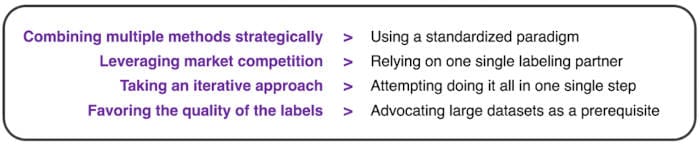
Figure 5: An Agile Manifesto of Data Labeling.
1. Combining multiple methods/tools
The concept of Autolabeling, which consists of using an ML model to generate “synthetic” labels, has become increasingly popular in the most recent years, offering hope to those tired of the status quo, but is only one attempt at streamlining data labeling. The truth, though is, no single approach will solve all issues: at the center of autolabeling, for instance, is a chicken-and-egg problem. That is why the concept of Human-in-the-Loop labeling is gaining traction.
That said, those attempts feel uncoordinated and bring little to no relief to companies who often struggle to see how those new paradigms apply to their own challenges. That’s why the industry is in need of more visibility and transparency regarding existing tools (a wonderful initial attempt at this is the TWIML Solutions Guide, though it’s not specifically targeted towards labeling solutions), easy integration between those tools, as well as an end-to-end labeling workflow that naturally integrates with the rest of the ML lifecycle.
2. Leveraging the strength of the market
Outsourcing the process might not be an option for specialty use cases for which no third party is capable of delivering satisfactory results. That’s because most labeling companies rely on either crowdsourcing or BPOs, meaning their annotators are not a highly skilled workforce— they won’t be able to annotate brain cancer on MRIs for you. Luckily, some startups are now focusing on providing specialized services for specific verticals.
But regardless of whether you need experts to help, it’s still hard to identify the right company for you. Most labeling companies do it all but ultimately have their own strengths and weaknesses, which customers often discover only after signing a year-long contract. Comparing all options is key to finding the very best annotators available at the moment when you need them and should be an essential part of the process.
3. Taking an iterative approach
The process of labeling data is actually surprisingly exempt from any feedback loop, even though feedback is at the very center of Machine Learning. No one would think of developing a model blindly, and yet, that’s what is traditionally done to generate labels. Taking a crawl-walk-run approach to tune and optimize your labeling process and your dataset for the model is unquestionably the way to go. That’s why a human-in-the-loop-based paradigm, where machines pre-annotate and humans validate, is the clear winner.
An even more promising approach consists of listening to the clues of the model to identify where and why the model is failing, potentially identifying bad labels and fixing them if necessary. One way of doing this is by using Active Learning.
4. Favoring quality over quantity
If you’ve been taught that the more data, the better, you’re definitely not the only one: that’s one of the most common misconceptions in Machine Learning. However, it’s not volume that matters, but variety. Scale is simply overrated. You obviously need some data to bootstrap, but large amounts of data inexorably lead to diminishing returns—that’s pure economics.
Instead, it is often more beneficial to invest time and money getting the right labels for a strategically chosen training dataset than into labeling loads of useless data. Ensuring that data curation (the concept of sampling the most impactful training records) makes its way into the ML lifecycle should be a key focus in MLOps over the next couple of years.
If, like most data scientists, you feel frustrated about data labeling, it might be time to give all of those ideas a try. Just like in the early days of Agile, none of the precepts is particularly difficult in place, but they all require self-discipline and awareness.
There is certainly a long way to go to have those best practices incorporated into the daily habits of data scientists worldwide, but like any meaningful change, it starts with one. Remember that back in 2001, a meeting at a ski resort was all it took to start the engine that led to a software development revolution. Our revolution might already be unfolding in front of our unsuspecting eyes—in fact, it probably is. So stay tuned and enjoy the ride.
Bio: Dr. Jennifer Prendki is the founder and CEO of Alectio, the first ML-driven Data Prep Ops platform. She and her team are on a mission to help ML teams build models with less data and to remove all pain points associated with "traditional" data preparation. Prior to Alectio, Jennifer was the VP of Machine Learning at Figure Eight; she also built an entire ML function from scratch at Atlassian, and led multiple Data Science projects on the Search team at Walmart Labs. She is recognized as one of the top industry experts on Active Learning and ML lifecycle management, and is an accomplished speaker who enjoys addressing both technical and non-technical audiences.
Related: