Build a Serverless News Data Pipeline using ML on AWS Cloud
This is the guide on how to build a serverless data pipeline on AWS with a Machine Learning model deployed as a Sagemaker endpoint.
By Maria Zentsova, Senior Data Analyst at Wood Mackenzie
As an analyst, I spend a lot of time tracking news and industry updates. Thinking about this problem on my maternity leave, I've decided to build a simple app to track news on green tech and renewable energy. Using AWS Lambda and other AWS services like EventBridge, SNS, DynamoDB, and Sagemaker it's very easy to get started and build a prototype in a couple of days.
The app is powered by a series of serverless Lambda functions and a text summarization Machine Learning model deployed as SageMaker endpoint. Every 24 hours AWS EventBridge rule triggers Lambda function to fetch feeds from the DynamoDB database.
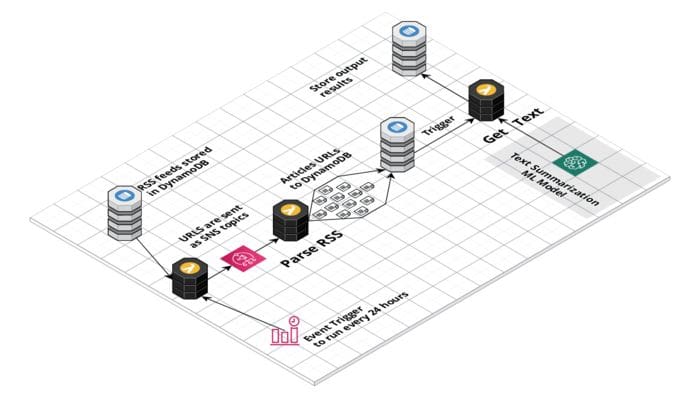
These feeds are then sent as SNS topics to trigger multiple lambdas to parse feeds and extract news URLs. Each website updates its RSS feeds daily with just a couple of articles at most, so this way we won't send a lot of traffic, which might result in consuming too many resources of any particular news publication.
The big problem, however, is to extract the full text of the article, because every website is different. Luckily for us, libraries such as goose3 solve this problem by applying ML methods to extract the body of the page. I can't store the full text of the article due to copyright, that's why I apply a HuggingFace text summarization transformer model to generate a short summary.
Here is a detailed guide on how to build your own news aggregation pipeline powered by ML.
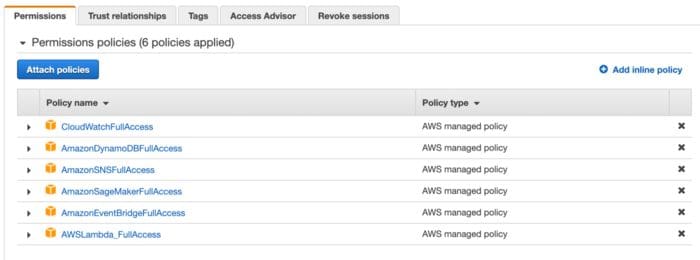
1. Set up IAM role with necessary permissions.
Although this data pipeline is very simple, it connects a number of AWS resources. To grant our functions access to all the resources it needs, we need to set up IAM role. This role assigns our function permissions to use other resources in the cloud, such as DynamoDB, Sagemaker, CloudWatch, and SNS. For security reasons, it is best not to give full AWS administrative access to our IAM role, and only allow it to use the resources it needs.
2. Fetch RSS feeds from DynamoDB in an RSS Dispatcher Lambda
With AWS Lambda one can do almost anything, it's a very powerful serverless compute service and is great for short tasks. The main advantage for me is that it's very easy to access other services in the AWS ecosystem.
I store all RSS feeds in a DynamoDB table and it's really easy to access it from the lambda using boto3 library. Once I fetch all the feeds from the database, I send them as SNS messages to trigger feed parsing lambdas.
import boto3
import json
def lambda_handler(event, context):
# Connect to DynamoDB
dynamodb = boto3.resource('dynamodb')
# Get table
table = dynamodb.Table('rss_feeds')
# Get all records from the table
data = table.scan()['Items']
rss = [y['rss'] for y in data]
# Connect to SNS
client = boto3.client('sns')
# Send messages to the queue
for item in rss:
client.publish(TopicArn="arn:aws:sns:eu-west-1:802099603194:rss_to-parse", Message = item)
3. Creating Layers with necessary libraries
To use some specific libraries in AWS Lambdas, you need to import them as a Layer. To prepare the library for import, it needs to be in a python.zip archive, which then we can upload on AWS and use in the function. To create a layer, just cd in a python folder, run the pip install command, zip it and it's ready to be uploaded.
pip install feedparser -t .
However, I had some difficulty deploying the goose3 library as a layer. After a short investigation, it turns out some libraries like LXML need to be compiled in a Lambda-like environment, which is Linux. So if the library was compiled, for instance, on Windows and then imported into the function, the error will occur. To solve this problem, before creating an archive we need to install the library on Linux.
There are two ways to do it. First, to install on simulated lambda environment with docker. For me, the easiest way was to use the AWS sam build command. Once the function is built, I just copy the required packages from the build folder and upload them as a layer.
sam build --use-container
4. Launch Lambda functions to parse a feed
Once we send news URLs to SNS as topics, we could trigger multiple lambdas to go and fetch news articles from the RSS feeds. Some RSS feeds are different, but the feed parser library allows us to work with different formats. Our URL is a part of the event object, so we need to extract it by key.
import boto3
import feedparser
from datetime import datetime
def lambda_handler(event, context):
#Connect to DynamoDB
dynamodb = boto3.resource('dynamodb')
# Get table
table = dynamodb.Table('news')
# Get a url from from event
url = event['Records'][0]['Sns']['Message']
# Parse the rss feed
feed = feedparser.parse(url)
for item in feed['entries']:
result = {
"news_url": item['link'],
"title": item['title'],
"created_at": datetime.now().strftime('%Y-%m-%d') # so that dynamodb will be ok with our date
}
# Save the result to dynamodb
table.put_item(Item=result, ConditionExpression='attribute_not_exists(news_url)') # store only unique urls
5. Creating and deploying text summarization model on Sagemaker
Sagemaker is a service that makes it easy to write, train and deploy ML models on AWS. HuggingFace has partnered with AWS to make it even easier to deploy its models to the cloud.
Here I write a simple text summarization model in Jupiter notebook and deploy it using deploy() command.
from sagemaker.huggingface import HuggingFaceModel
import sagemaker
role = sagemaker.get_execution_role()
hub = {
'HF_MODEL_ID':'facebook/bart-large-cnn',
'HF_TASK':'summarization'
}
# Hugging Face Model Class
huggingface_model = HuggingFaceModel(
transformers_version='4.6.1',
pytorch_version='1.7.1',
py_version='py36',
env=hub,
role=role,
)
# deploy model to SageMaker Inference
predictor = huggingface_model.deploy(
initial_instance_count=1, # number of instances
instance_type='ml.m5.xlarge' # ec2 instance type
)
Once it is deployed, we could get endpoint information from Sagemaker -> Inference -> Endpoint configuration and use it in our lamdas.
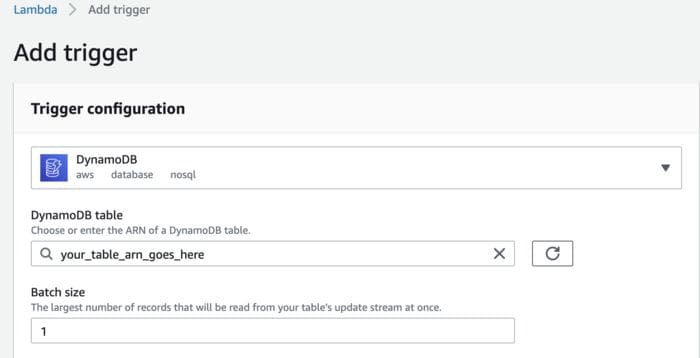
6. Get the full text of the article, summarize it and store results in DynamoDB
We shouldn't store full text due to copyright, that's why all the processing work happens in one lambda. I launch text processing lambda, once URL made its way to the DynamoDB table. To achieve this, I set up a DynamoDB item creation, as a trigger to launch a lambda. I set up batch size of one, so that lambda deals only with one article at a time.
import json
import boto3
from goose3 import Goose
from datetime import datetime
def lambda_handler(event, context):
# Get url from DynamoDB record creation event
url = event['Records'][0]['dynamodb']['Keys']['news_url']['S']
# fetch article full text
g = Goose()
article = g.extract(url=url)
body = article.cleaned_text # clean article text
published_date = article.publish_date # from meta desc
# Create a summary using our HuggingFace text summary model
ENDPOINT_NAME = "your_model_endpoint"
runtime= boto3.client('runtime.sagemaker')
response = runtime.invoke_endpoint(EndpointName=ENDPOINT_NAME, ContentType='application/json', Body=json.dumps(data))
#extract a summary
summary = json.loads(response['Body'].read().decode())
#Connect to DynamoDB
dynamodb = boto3.resource('dynamodb')
# Get table
table = dynamodb.Table('news')
# Update item stored in dynamoDB
update = table.update_item(
Key = { "news_url": url }
,
ConditionExpression= 'attribute_exists(news_url) ',
UpdateExpression='SET summary = :val1, published_date = :val2'
ExpressionAttributeValues={
':val1': summary,
':val2': published_date
}
)
Here is how using AWS tools, we've built and deployed a simple serverless data pipeline to read the latest news. If you have any ideas, how it could be improved or have any questions do not hesitate to contact me.
Bio: Maria Zentsova is a Senior Data Analyst at Wood Mackenzie. She works on data collection and analysis, ETL pipelines and data exploration tools.
Related:
- How I Redesigned over 100 ETL into ELT Data Pipelines
- The Best Ways for Data Professionals to Market AWS Skills in 2022
- Prefect: How to Write and Schedule Your First ETL Pipeline with Python