Is the Modern Data Stack Leaving You Behind?
The modern data stack narrative is largely dominated by analytics engineering. Where does that leave data engineers? Discover the difference between the MDS for data engineers & analytics engineers.
By Josh Benamram, Co-Founder & CEO at Databand

Photo by Andy Beales on Unsplash
The “modern data stack” has gotten a lot of press recently in the data blogosphere. And for good reason - it’s a useful model for identifying the tools you need to build an effective data org.
Let’s say you just invested huge amounts of time and treasure in brand new tools to run your data infra. But your tools don’t line up with the modern stack described. You’re using a bunch of other tools, and don’t recognize all those logos. Locked out of the “modern stack”, you might be led to believe that your data operations will creep to a halt as it crumbles under the weight of its unshakable decrepitude. Or that you’ll never find and hire new engineers willing to tolerate your antiquated data platform.
None of that is likely true. The truth is that the “modern stack” has been too narrowly defined for only a certain kind of data organization. For many data teams, you need to be thinking about your stack differently.
The Modern data stack: currently defined
The current definition for the modern data stack is a self-self serve data platform that consists of these layers:
- Managed data integration tool (Fivetran)
- Cloud-based data warehouse (Bigquery)
- Workflow orchestrator (DBT)
- Business intelligence platform (Looker)
Independently, these are all great tools. Together, they bring the combination required to help a large swath of organizations do what they need done. But if you don’t fit this mold, does it mean your team is not “modern”? Of course not! While these tools cover the needs of many, they don’t tell the whole story. It’s missing a critical layer of core data platform services that many teams simply cannot function without.
Modern data stack: redefined
The truth is there are different skews of the modern data stack. What kind of “modern data stack” you need depends on your company’s strategy and the nature of your data products. The type of stack you chose will inform the stressors (sources of failure) in your data platform and your definitions of data quality.
Right now, the modern stack is being conflated with the rise of analytics engineering. DBT Labs offers a great description of the role here. If you look at the data industry more holistically, you can see two diverging movements around the “modern data stack.”
One is, you guessed it, the modern data stack for analytics engineering. This version of the MDS is optimized for accessibility, ease of use, and centralization of work (“T”) in the warehouse. It’s often thought of with a “no-code” approach to build.
The other version we see teams pursue is a modern data stack optimized for engineering. This version of the MDS is designed for flexibility, control, and scalability.
The modern analytics engineering stack
This is the type of modern data stack that dominates discussion around the topic. Data platforms in this category are usually low-code and SQL-oriented. As such, data teams will consist mostly of data analysts and analytics engineers with fewer data engineers (possibly no data engineers depending on the size of the organization).
Teams working in this paradigm are less dependent on data engineers to ingest and ready their data. They have a smaller number of commonly used data sources that can be wholly ingested by platforms like Fivetran and Stitch. If data engineers exist, they will be responsible for maintaining the data platform as a whole and occasionally a custom integration. Everything to the left of the warehouse is more simple and doesn’t require deep engineering attention.
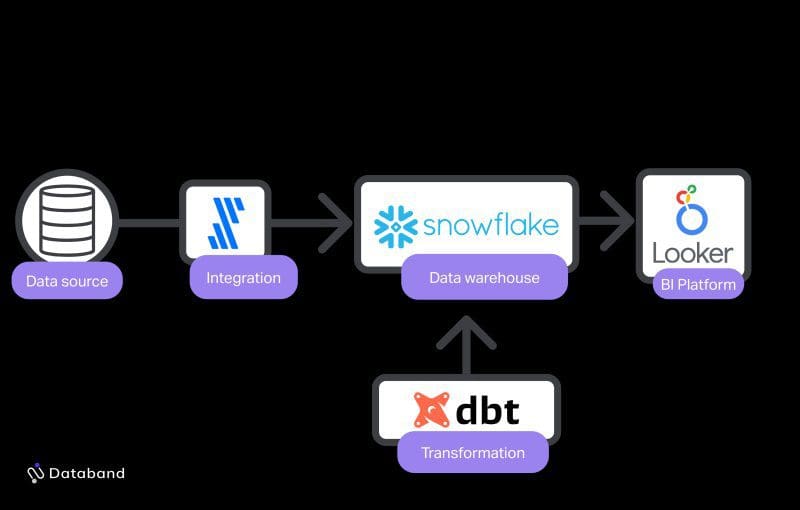
When there is complexity, it will arise from the internal content of data flows, but more so from how users query and analyze the data. As such, many of the data issues and failures will be due to SQL and dashboard errors. Analysts will mainly interface with the analytics engineers who are responsible for aggregating data in the warehouse and providing documentation to improve end-user accessibility.
This platform is nimble and will make it easy to get started quickly. The skills needed to manage it are easier to learn (SQL, GUI-based tools) so it’s a quick, lean way to get an analytics program off of the ground. As an example, this model is perfect for when business stakeholders want constant and ad hoc analysis done on Salesforce data so they can make decisions quickly.
The modern data engineering stack
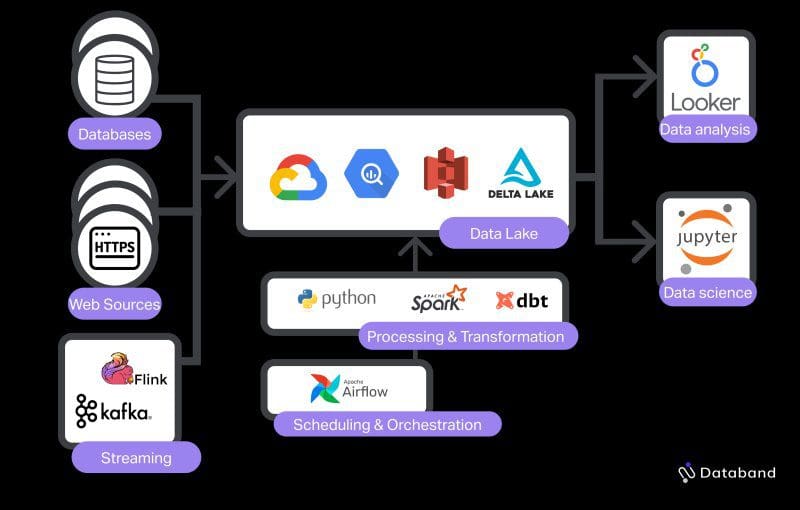
The modern data stack for data engineering is focused on giving data engineers the tools they need to build more complex data products in a way that’s maintainable, reliable, and scalable.
The modern data stack for data engineering consists of:
- cloud-based data lake (S3, Delta Lake, BigQuery or GCS)
- cloud transformation tool (Spark, Google Dataflow)
- workflow orchestration tool (Airflow, Argo, Dagster)
- Streaming system (Kafka, Beam, Flink)
Organizations that use this architecture need high volumes of data from a wide range of sources to build their data products. These teams build a lot of IP in how they process and generate insights or models from unique data sets. They deal with more unique and varied data sources (csv, parquest, json), and do heavier processing of data to make it all fit together.
These teams require more specialized skills on top of analytics engineering to get all the data needed into the analytics-ready form. Data engineers are necessary to bring control, flexibility, and firepower for ingestion, preparation, and delivery of data to analysts and scientists. To provide those layers of flexibility and control, these teams use code-oriented architectures; Python and custom pipeline build outs. As a result of this complexity and the variety of data sources, we will see a fan-out architecture to the left of the warehouse, in the ingestion and pre-processing layers, which introduces more points of failure and the need for specialized tools to enforce data reliability across a huge number of data sources and possible causes of failure.
The modern data stack 2.0
The modern data stack movement has allowed analytics engineering oriented teams to achieve more accessibility and speed, and it has allowed data engineering oriented teams to deliver high quality data at scale.
Now, we are already beginning to see the next iteration of this movement take shape: data observability.
As data platforms become more scalable and agile, teams need to make these systems more reliable and trusted. Data observability tools have proliferated in response. Both solutions that cater more to analytics engineers like Re-data as well as solutions more data engineering focused like us at Databand.
No matter what type of data stack you choose, one thing is clear: data observability platforms will shape the future of the modern data stack. With greater control over their data’s quality, teams will be able to automate and accelerate their data platform development, and ship faster, higher quality data products to market.
Bio: Josh Benamram comes from a varied background with a common thread of data obsession. He started in the finance world, working first as an analyst at a quant investment firm, then at Bessemer Venture Partners where he focused on investing in data and ML companies. Before founding Databand.ai, he worked as a product manager at Sisense, a high-growth analytics company, where he built product capabilities geared toward data engineering teams. He started Databand.ai with his two co-founders to help data engineers deliver more reliable data products. He holds a B.Sc from Cornell University.
Related:
- Data Engineering Technologies 2021
- Data Scientists Without Data Engineering Skills Will Face the Harsh Truth
- The Most Important Tool for Data Engineers