Stable Diffusion: Basic Intuition Behind Generative AI
This article provides a general overview of Stable Diffusion and focuses on building a basic understanding of how generative artificial intelligence works.

Image generated using Stable Diffusion
Introduction
The world of AI has shifted dramatically towards generative modeling over the past years, both in Computer Vision and Natural Language Processing. Dalle-2 and Midjourney have caught people's attention, leading them to recognize the exceptional work being accomplished in the field of Generative AI.
Most of the AI-generated images currently produced rely on Diffusion Models as their foundation. The objective of this article is to clarify some of the concepts surrounding Stable Diffusion and offer a fundamental understanding of the methodology employed.
Simplified Architecture
This flowchart shows the simplified version of a Stable Diffusion architecture. We will go through it piece by piece to build a better understanding of the internal workings. We will elaborate on the training process for better understanding, with the inference having only a few subtle changes.
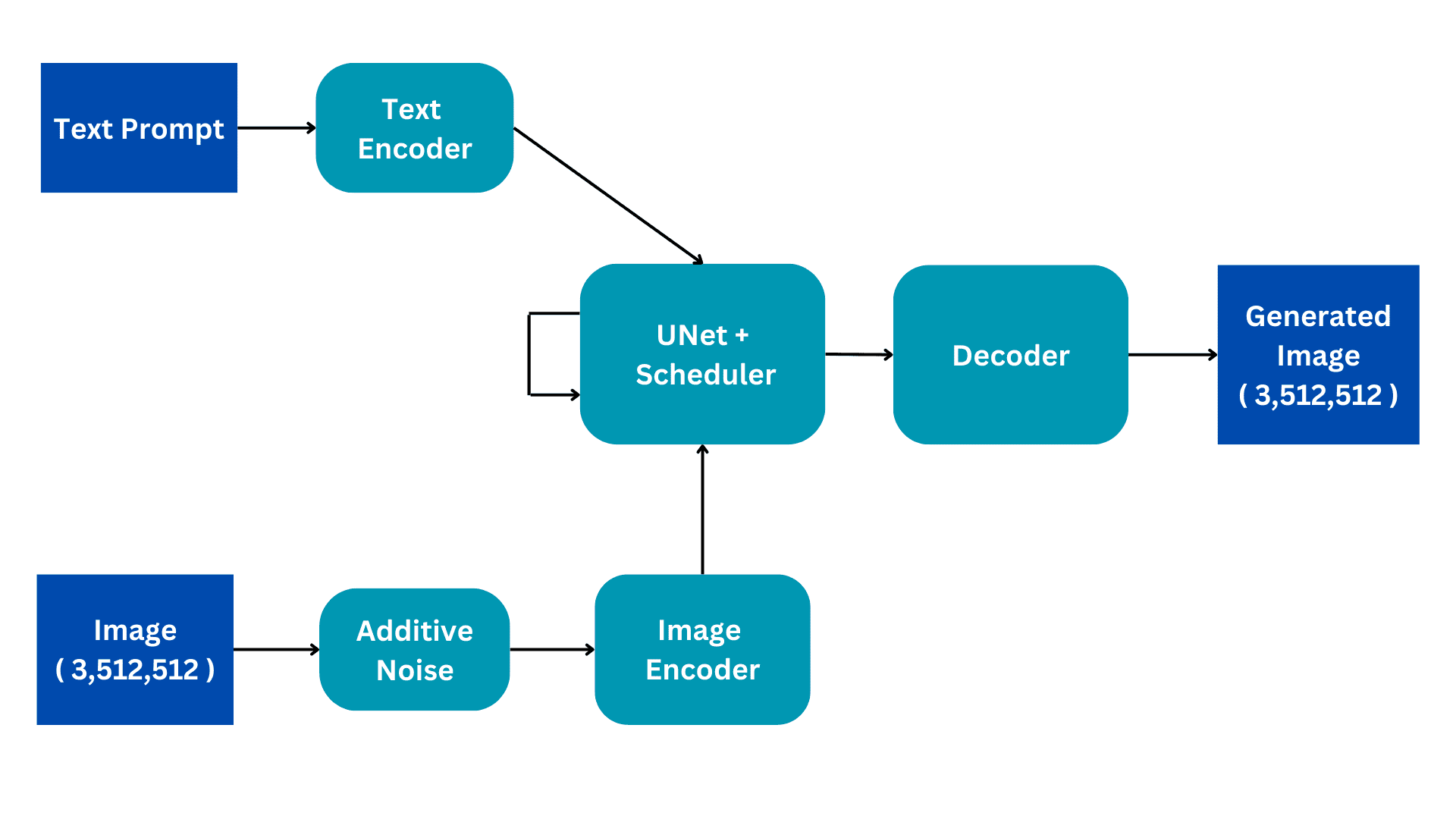
Image by Author
Inputs
The Stable Diffusion models are trained on Image Captioning datasets where each image has an associated caption or prompt that describes the image. There are therefore two inputs to the model; a textual prompt in natural language and an image of size (3,512,512) having 3 color channels and dimensions of size 512.
Additive Noise
The image is converted to complete noise by adding Gaussian noise to the original image. This is done in consequent steps, for example, a small amount is noise is added to the image for 50 consecutive steps until the image is completely noisy. The diffusion process will aim to remove this noise and reproduce the original image. How this is done will be explained further.
Image Encoder
The Image encoder functions as a component of a Variational AutoEncoder, converting the image into a 'latent space' and resizing it to smaller dimensions, such as (4, 64, 64), while also including an additional batch dimension. This process reduces computational requirements and enhances performance. Unlike the original diffusion models, Stable Diffusion incorporates the encoding step into the latent dimension, resulting in reduced computation, as well as decreased training and inference time.
Text Encoder
The natural language prompt is transformed into a vectorized embedding by the text encoder. This process employs a Transformer Language model, such as BERT or GPT-based CLIP Text models. Enhanced text encoder models significantly enhance the quality of the generated images. The resulting output of the text encoder consists of an array of 768-dimensional embedding vectors for each word. In order to control the prompt length, a maximum limit of 77 is set. As a result, the text encoder produces a tensor with dimensions of (77, 768).
UNet
This is the most computationally expensive part of the architecture and main diffusion processing occurs here. It receives text encoding and noisy latent image as input. This module aims to reproduce the original image from the noisy image it receives. It does this through several inference steps which can be set as a hyperparameter. Normally 50 inference steps are sufficient.
Consider a simple scenario where an input image undergoes a transformation into noise by gradually introducing small amounts of noise in 50 consecutive steps. This cumulative addition of noise eventually transforms the original image into complete noise. The objective of the UNet is to reverse this process by predicting the noise added at the previous timestep. During the denoising process, the UNet begins by predicting the noise added at the 50th timestep for the initial timestep. It then subtracts this predicted noise from the input image and repeats the process. In each subsequent timestep, the UNet predicts the noise added at the previous timestep, gradually restoring the original input image from complete noise. Throughout this process, the UNet internally relies on the textual embedding vector as a conditioning factor.
The UNet outputs a tensor of size (4, 64, 64) that is passed to the decoder part of the Variational AutoEncoder.
Decoder
The decoder reverses the latent representation conversion done by the encoder. It takes a latent representation and converts it back to image space. Therefore, it outputs a (3,512,512) image, the same size as the original input space. During training, we aim to minimize the loss between the original image and generated image. Given that, given a textual prompt, we can generate an image related to the prompt from a completely noisy image.
Bringing It All Together
During inference, we have no input image. We work only in text-to-image mode. We remove the Additive Noise part and instead use a randomly generated tensor of the required size. The rest of the architecture remains the same.
The UNet has undergone training to generate an image from complete noise, leveraging text prompt embedding. This specific input is used during the inference stage, enabling us to successfully generate synthetic images from the noise. This general concept serves as the fundamental intuition behind all generative computer vision models.
Muhammad Arham is a Deep Learning Engineer working in Computer Vision and Natural Language Processing. He has worked on the deployment and optimizations of several generative AI applications that reached the global top charts at Vyro.AI. He is interested in building and optimizing machine learning models for intelligent systems and believes in continual improvement.