Explain NLP Models with LIME
It is important to know how LIME reaches to its final outputs for explaining a prediction done for text data. In this article, I have shared that concept by enlightening the components of LIME.
It is very important to know how LIME reaches to its final outputs for explaining a prediction done for text data. In this article, I have shared that concept by enlightening the components of LIME.

Photo by Ethan Medrano on Unsplash
Few weeks back I wrote a blog on how different interpretability tools can be used to interpret certain predictions done by the black-box models. In that article I shared the mathematics behind LIME, SHAP and other interpretability tools, but I did not go much into details of implementing those concepts on original data. In this article, I thought of sharing how LIME works on text data in a step-by-step manner.
The data that is used for the whole analysis is taken from here . This data is for predicting whether a given tweet is about a real disaster(1) or not(0). It has the following columns:

Source
As the main focus of this blog is to interpret LIME and its different components so we will quickly build a binary text classification model using Random Forest and will focus mainly on LIME interpretation.
First, we start with importing the necessary packages. Then we read the data and start preprocessing like stop words removal, Lowercase, lemmatization, punctuation removal, whitespace removal etc. All the cleaned preprocessed text are stored in a new ‘cleaned_text’ column which will be further used for analysis and the data is split into train and validation set in a ratio of 80:20.
Then we quickly move to converting the text data into vectors using TF-IDF vectoriser and fitting a Random Forest classification model on that.

Image by author
Now let’s begin the main interest of this blog which is how to interpret different components of LIME.
First let’s see what is the final output of the LIME interpretation for a particular data instance. Then we will go deep dive into the different components of LIME in a step by step manner which will finally result the desired output.

Image by author
Here labels=(1,) is passed as an argument that means we want the explanation for the class 1. The features (words in this case) highlighted with orange are the top features that cause a prediction of class 0 (not disaster) with probability 0.75 and class 1(disaster) with probability 0.25.
NOTE: char_level is one of the arguments for LimeTextExplainer which is a boolean identifying that we treat each character as an independent occurrence in the string. Default is False so we don’t consider each character independently and IndexedString function is used for tokenization and indexing the words in the text instance, otherwise IndexedCharacters function is used.
So, you must be interested to know how these are calculated. Right?
Let’s see that.
LIME starts with creating some perturbed samples around the neighbourhood of data point of interest. For text data, perturbed samples are created by randomly removing some of the words from the instance and cosine distance is used to calculate the distance between the original and perturbed samples as default metric.
This returns the array of 5000 perturbed samples(each perturbed sample is of length of the original instance and 1 means the word in that position of the original instance is present in the perturbed sample), their corresponding prediction probabilities and the cosine distances between the original and perturbed samples.A snippet of that is as follows:

Image by author
Now after creating the perturbed samples in the neighbourhood it’s time to give weights to those samples. Samples that are near from the original instance are given higher weightage than the samples far from the original instance. Exponential kernel with kernel width 25 is used as default to give those weightage.
After that important features(as per num_features: max number of features to be explained) are selected by learning a locally linear sparse model from perturbed data. There are several methods for choosing the important features using the local linear sparse model like ‘auto’(default), ‘forward_selection’, ‘lasso_path’, ‘highest_weights’. If we choose ‘auto’ then ‘forward_selection’ is used if num_features≤6, else ‘highest_weights’ is used.

Image by author
Here we can see that the features selected are [1,5,0,2,3] which are the indices of the important words(or features) in the original instance. As here num_features=5 and method=‘auto’, ‘forward_selection’ method is used for selecting the important features.
Now let’s see what will happen if we choose method as ‘lasso_path’.

Image by author
Same. Right?
But you might be interested to go deep dive into this process of selection. Don’t worry, I will make that easy.
It uses the concept of Least angle regression for selecting the top features.
Let’s see what will happen if we select method as ‘highest_weights’.

Image by author
Hang on. We are going deeper in the selection process.
So now the important features we have selected by using any one of the methods. But finally we will have to fit a local linear model to explain the prediction done by the black-box model. For that Ridge Regression is used as default.
Let’s check how the outputs will look like finally.
If we select method as auto, highest_weights and lasso_path respectively the output will look like this:
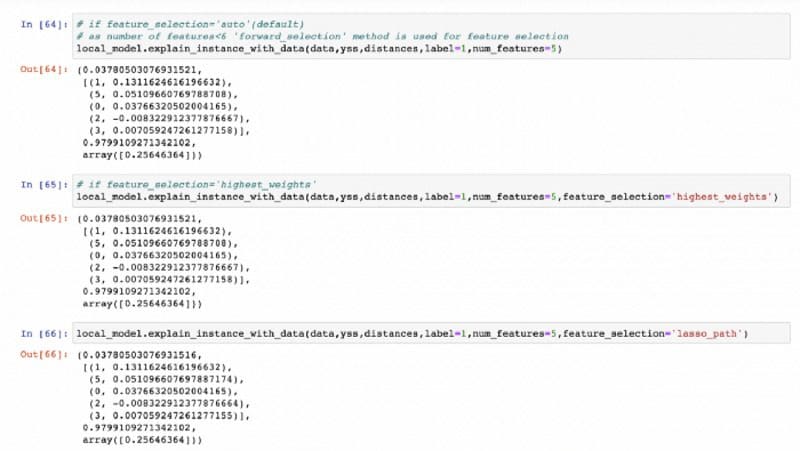
Image by author
These return a tuple (intercept of the local linear model, important features indices and its coefficients, R² value of the local linear model, local prediction by the explanation model on the original instance).
If we compare the above image with

Image by author
then we can say that the prediction probabilities given in the left most panel is the local prediction done by the explanation model. The features and the values given in the middle panel are the important features and their coefficients.
NOTE: As for this particular data instance the number of words(or features) is only 6 and we are selecting the top 5 important features , all the methods are giving the same set of top 5 important features. But it may not happen for longer sentences.
If you like this article please hit recommend. That would be amazing.
To get the full code please visit my GitHub repository. For my future blogs please follow me on LinkedIn and Medium.
Conclusion
In this article, I tried to explain the final outcome of LIME for text data and how the whole explanation process happens for text in a step by step manner. Similar explanations can be done for tabular and image data. For that I will highly recommend to go through this.
References
- GitHub repository for LIME : https://github.com/marcotcr/lime
- Documentation on LARS: http://www.cse.iitm.ac.in/~vplab/courses/SLT/PDF/LAR_hastie_2018.pdf
- https://towardsdatascience.com/python-libraries-for-interpretable-machine-learning-c476a08ed2c7
Ayan Kundu is a data scientist with 2+ years of experience in the field of banking and finance and also a passionate learner to help the community as much as possible. Follow Ayan on LinkedIn and Medium.