8 Innovative BERT Knowledge Distillation Papers That Have Changed The Landscape of NLP
All of the papers present a particular point of view of findings in the BERT utilization.
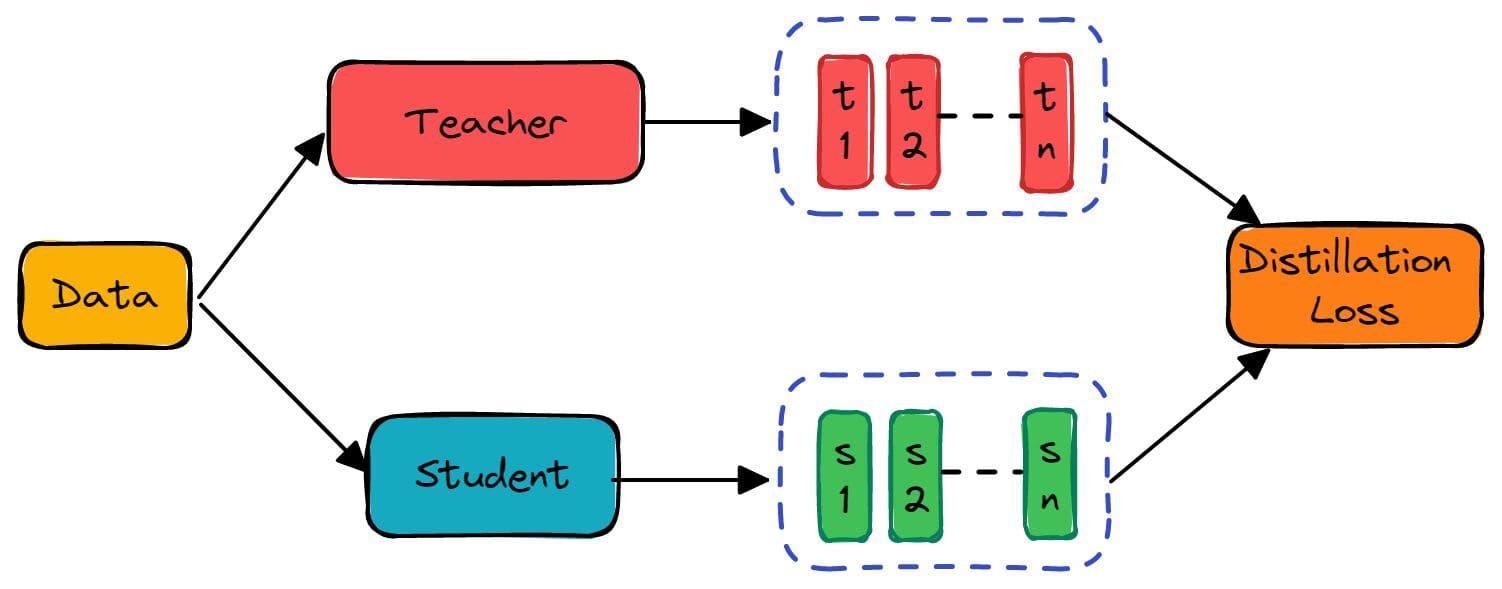
Image by Editor
The article summarizes eight papers carefully selected from many papers related to BERT knowledge distillation. NLP model compression and acceleration is an active area of research and widely adapted in the industry to deliver low latency features and services to end users.
To put it bluntly, the BERT model is used for converting words into numbers and enables you to train machine learning models on text data. Why? Because the machine learning models take input as numbers and not words.
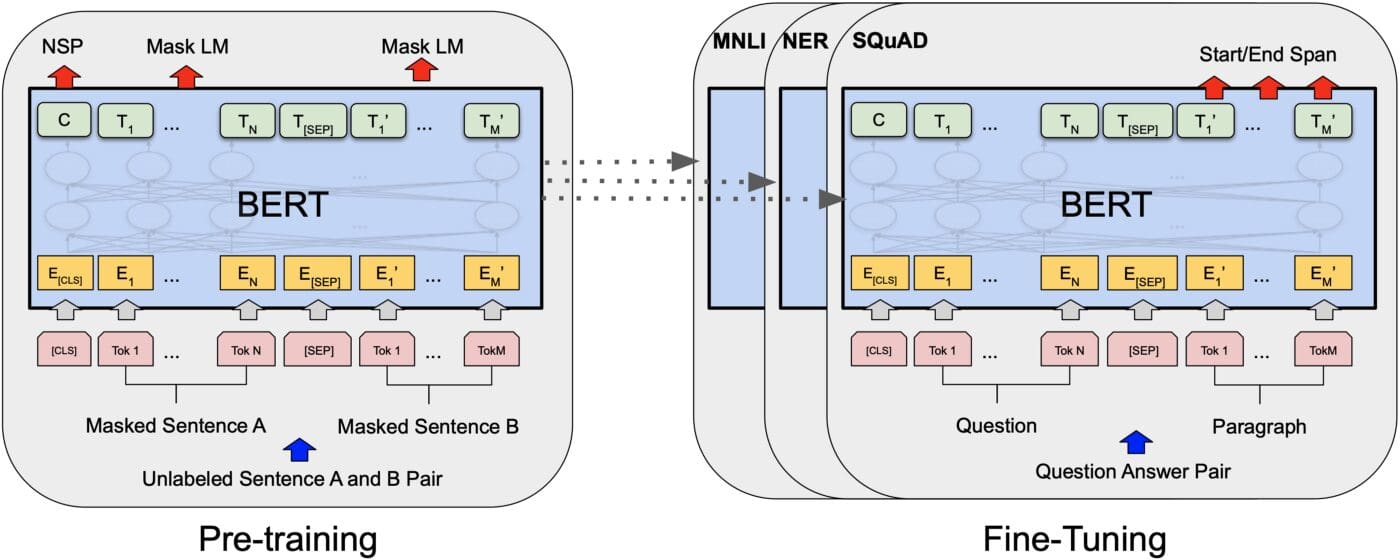
Image from Devlin et al., 2019
Why is BERT so Popular?
First and foremost, BERT is a language model that amplifies the high performance of several tasks. BERT (Bidirectional Encoder Representations from Transformers), published in 2018, triggered a fuss in the community of machine learning by providing a neoteric achieved outcomes in a broad spectrum of NLP tasks, namely language understanding, and question-answering.
The main attraction of BERT is employing the bidirectional training of Transformer, a prominent attention model for language modeling. But, as for my narration, here are a few things that make BERT so much better:
- It is open-source
- The best technique in NLP to grasp the context-heavy texts
- Bidirectional nature
All of the papers present a particular point of view of findings in the BERT utilization.
Paper 1
DistilBERT, a distilled version of BERT: smaller, faster, cheaper, and lighter
Authors propose a technique to pre-train a smaller general-purpose language representation model, termed DistilBERT, which can then be fine-tuned with good performances on a wide range of tasks like its larger counterparts. While most prior works investigated the use of distillation for building task-specific models, we leverage knowledge distillation during the pre-training phase. We show that it is possible to reduce the size of a BERT model by 40% while retaining 97% of its language understanding capabilities and being 60% faster. Loss is threefold, combining language modeling loss, distillation loss, and cosine-distance loss. The data used the same corpus as the original BERT model. Further, DistilBERT was trained on eight 16GB V100 GPUs for around 90 hours.
Let’s assume
For an input x, the teacher outputs:
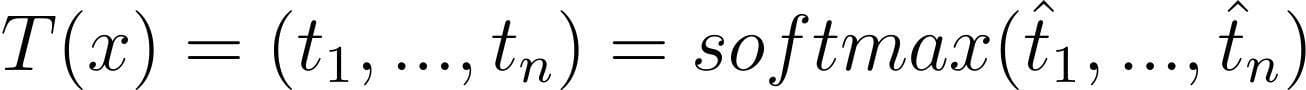
Source
And the student outputs:
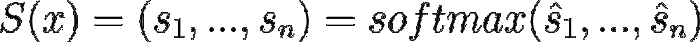
Source
Consider that softmax and the notations that come with it; we’ll get back to it later. Nevertheless, if we want T and S to be close, we can apply a cross-entropy loss to S with T as a target. That is what we call teacher-student cross-entropy loss:
- Distillation loss: this loss is the same as the typical Knowledge distillation loss:
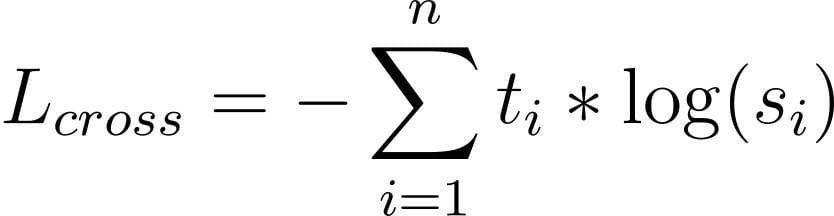
Source
- Masked language modeling loss(MLM)
- Cosine embedding loss(Lcos) was found to be beneficial, which aligned the direction of student and teacher hidden state vectors.
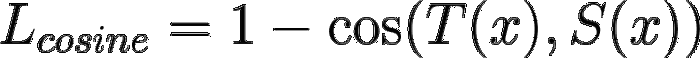
T(x) is the teacher vector output, and S(x) is the student vector output Source.
Key takeaway: This is an online distillation technique where the teacher and student models are trained.
Paper 2
Distilling Knowledge Learned in BERT for Text Generation
This paper presents a generic technique for using pre-trained language models to further refine text generation, excluding the specific parameter sharing, feature extraction, or augmenting with auxiliary tasks. Their presented Conditional MLM mechanism leverages unsupervised language models pre-trained on a large corpus followed by readjusting to supervised sequence-to-sequence tasks. The distillation approach they offered indirectly impacts the text generation model by delivering soft-label distributions only; hence is model-agnostic. Keys points are mentioned below.
- MLM objective that BERT is trained with is not auto-regressive; it’s trained in a way that looks at both past and future context.
- A novel C-MLM(conditional Masked language modeling) task requires additional, conditional input.
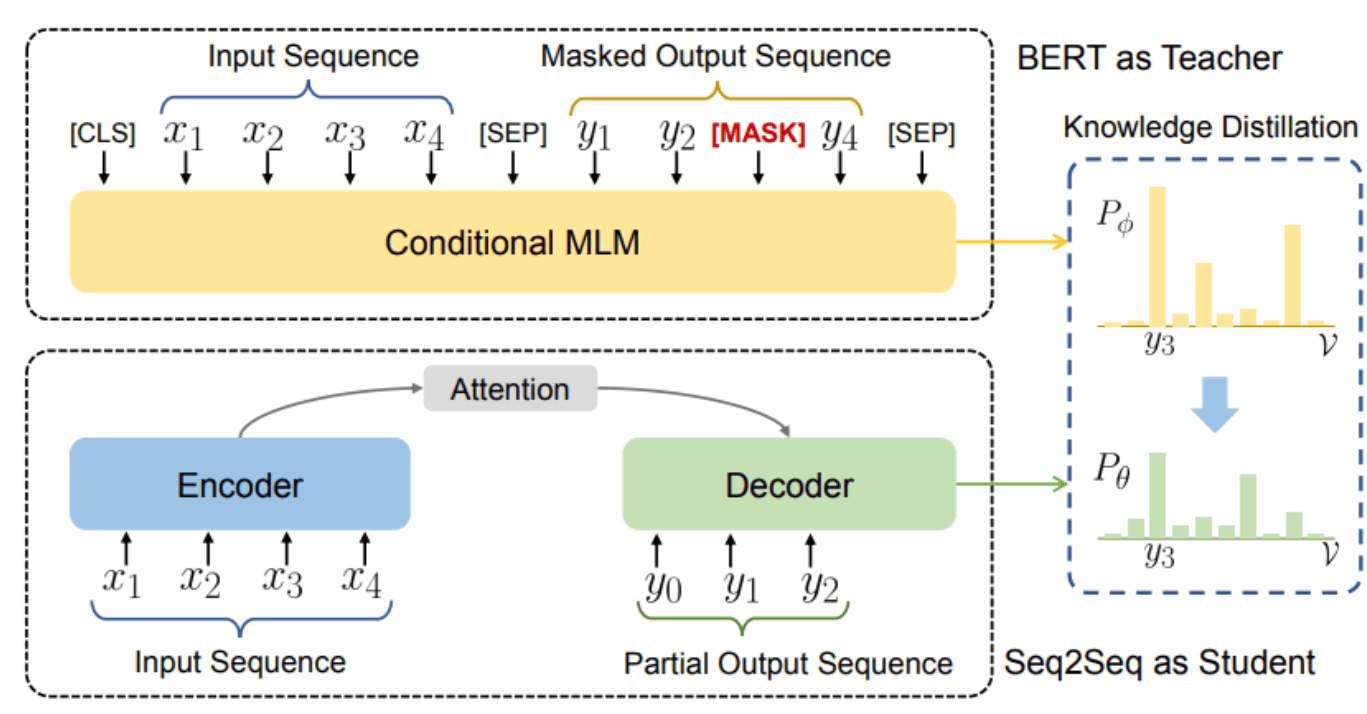
Illustration of distilling knowledge from BERT for text generation. Source
Furthermore, the knowledge distillation technique used here is the same as the one in the original Distillation research paper, where we train the student network on the soft labels generated by the teacher network.
So, what makes this research paper stand out from the rest? Here is the explanation.
The key idea here is to distill the knowledge in BERT into a student model that can generate text, while previous works focused only on model compression to do the same task as the teacher model. Then, a fine-tuning of the BERT model is done, so that fine-tuned model can be used for text generation.
Let’s take the use case of language translation, X is the source language sentence, and Y is the target language sentence.
First Phase: Fine-tuning of the BERT model
- Input data: Concatenated X and Y with 15% of the tokens in Y randomly masked
- Labels: masked tokens from Y
Second Phase: Knowledge distillation of fine-tuned BERT model to Seq2Seq model
- Teacher: fine-tuned BERT model from the first phase
- Student: Seq2Seq model, for example, attention-based RNN, Transformer, or any other sequence-generation models
- Input data & Label: soft targets from fine-tuned BERT model
Paper 3
TinyBERT: Distilling BERT for Natural Language Understanding
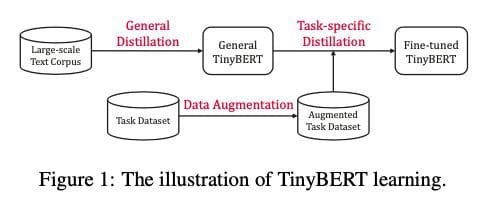
The article proposes a novel Transformer distillation technique exclusively intended for knowledge distillation (KD) of the Transformer-based models. By leveraging this novel KD approach, the heap of knowledge encoded in a large teacher BERT can be efficaciously shifted to a small student Tiny-BERT. Then, we introduce a new two-stage learning framework for TinyBERT, which performs Transformer distillation at both the pretraining and task-specific learning stages. This framework ensures that TinyBERT can capture BERT's general domain and task-specific knowledge.
TinyBERT with four layers is empirically effective and achieves more than 96.8% of the performance of its teacher BERT-Base on the GLUE benchmark while being 7.5x smaller and 9.4x faster on inference. TinyBERT with four layers is also significantly better than 4-layer state-of-the-art baselines on BERT distillation, with only about 28% parameters and about 31% inference time. Moreover, TinyBERT, with six layers, performs on par with its teacher BERT-Base.
Source
Moreover, this article proposed three main components for distilling transformer networks.
- Transformer-layer distillation: this includes attention-based distillation and hidden states-based distillation:
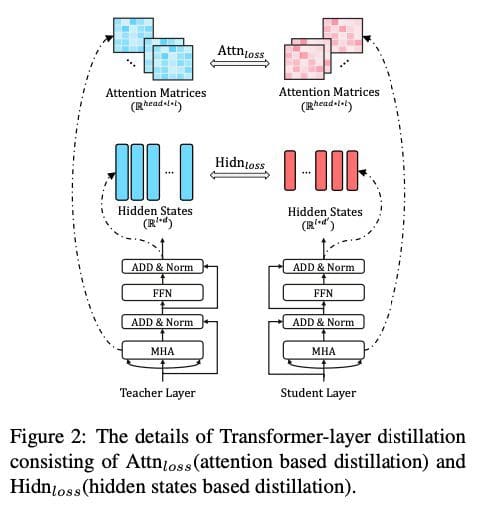
Source
- Embedding layer distillation: knowledge distillation is done for the embedding layer just like it was done for the hidden states-based distillation
- Prediction layer distillation: knowledge distillation is done w.r.t the predictions obtained from the teacher model, just like in the original work of Hinton. Moreover, the overall loss for the TinyBERT model combines the losses of all the three above:

Source
The main steps in TinyBERT training are as follows:
- General distillation: Take original BERT without fine-tuning as a teacher and a large-scale text corpus as training data. Now perform the Transformer distillation on text from the general domain to get general TinyBERT that can be further fine-tuned for downstream tasks. This generic TinyBERT performs worse than BERT because of the fewer layers, neurons, etc.
- Task-specific distillation: Fine-tuned BERT is used as the teacher, and training data is the task-specific training set.
Key takeaway: This is an offline distillation technique where the teacher model BERT is already pre-trained. Then they did two separate distillations: one for generic learning and another for task-specific learning. The first step of generic distillation involves distillation for all kinds of layers: attention layers, embedding layers, and prediction layers.
Paper 4
FastBERT: a Self-distilling BERT with Adaptive Inference Time
They propose a fresh new speed-tunable FastBERT with adaptive inference time. The speed at inference can be flexibly adjusted under varying demands, while redundant calculation of samples is avoided. Moreover, this model adopts a unique self-distillation mechanism for fine-tuning, further enabling a greater computational efficacy with minimal loss in performance. Our model achieves promising results in twelve English and Chinese datasets. It can speed up by a wide range from 1 to 12 times than BERT if given different speedup thresholds to make a speed-performance tradeoff.
Comparison with similar work:
- TinyBERT: performs 2-stage learning using both general-domain and task-specific fine-tuning.
- DistilBERT: introduces triple loss
What makes FastBERT better?
This work applies self-distillation(training phase)and adaptive mechanism (during inference phase) techniques to NLP language models for efficiency improvements for the first time.
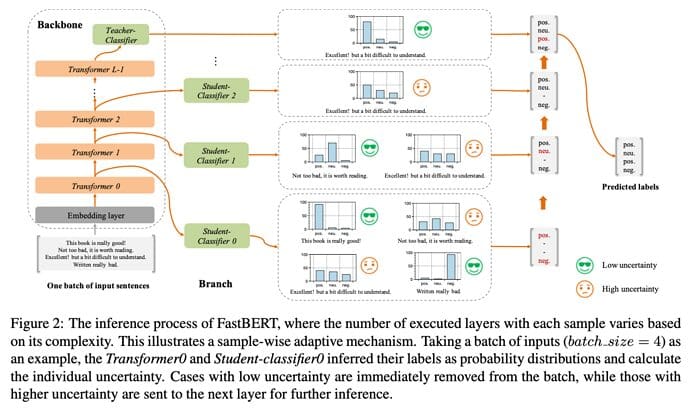
Source
The Model Architecture
FastBERT model consists of backbone and branches:
- Backbone: It has three parts: embedding layer, encoder containing stacks of Transformer blocks, and the teacher classifier. The embedding and encoder layers are the same as those of BERT. Finally, we have a teacher classifier that extracts task-specific features for downstream tasks and uses a softmax function.
- Branches: These contain the student classifiers that
- have the same architecture as the teacher
- are added to the output of each transformer block to enable early outputs
Training Stages
It uses separate training steps for backbone and student classifiers. Parameters in one module are always frozen while another module is being trained. Three steps:
- Backbone pre-training: Typical pre-training of the BERT model is used. No changes here. Highly-quality trained models can be freely loaded in this step.
- Backbone fine-tuning: For each downstream task, task-specific data is used to fine-tune both the backbone and teacher classifier. No student classifier is enabled at this stage.
- Self-distillation of student classifiers: Now that our teacher model is well-trained, we take its output. This soft-label output is high-quality, containing both original embedding and generalized knowledge. These soft labels are used to train the student classifiers. We are free to use an unlimited amount of unlabeled data here. This work differs from previous work in that this work uses the same model for teacher and student models.
Adaptive inference
Let’s talk about inference time. With FastBERT, the inference is performed adaptively, i.e., the number of executed encoding layers within the model can be adjusted according to input sample complexity.
At each transformer layer, the uncertainty of a student classifier’s output is computed, and it is determined if the inference can be terminated depending upon a threshold. Here is how the adaptive inference mechanism works:
- At each layer of FastBERT, the corresponding student classifier predicts the label of each sample with measured uncertainty.
- Samples with an uncertainty below a certain threshold will be sifted to early outputs, while ones with uncertainty above the threshold will move onto the next layer.
- With a higher threshold, fewer samples are sent to higher layers keeping the inference speed faster and vice versa.
Paper 5
Distilling Task-Specific Knowledge from BERT into Simple Neural Networks
In this paper, the authors exhibit that rudimentary, lightweight neural networks can even be made competitive apart from architecture modifications, external training data, or additional input features. They propose distilling knowledge from BERT into a single-layer, bidirectional long short-term memory network (BiLSTM) and its siamese equivalent for sentence-pair tasks. Throughout numerous datasets in paraphrasing, natural language inference, and sentiment classification, they achieve comparable outcomes with ELMo, while using roughly 100 times fewer parameters and 15 times less inference time. Further, their approach includes a fine-tuned BERT for teacher and BiLSTM student models. The primary motivation of this work comprises as follows:
- Can a simple architecture model capture the representation power for text modeling at a level of the BERT model?
- Study effective approaches to transfer knowledge from BERT to a BiLSTM model.
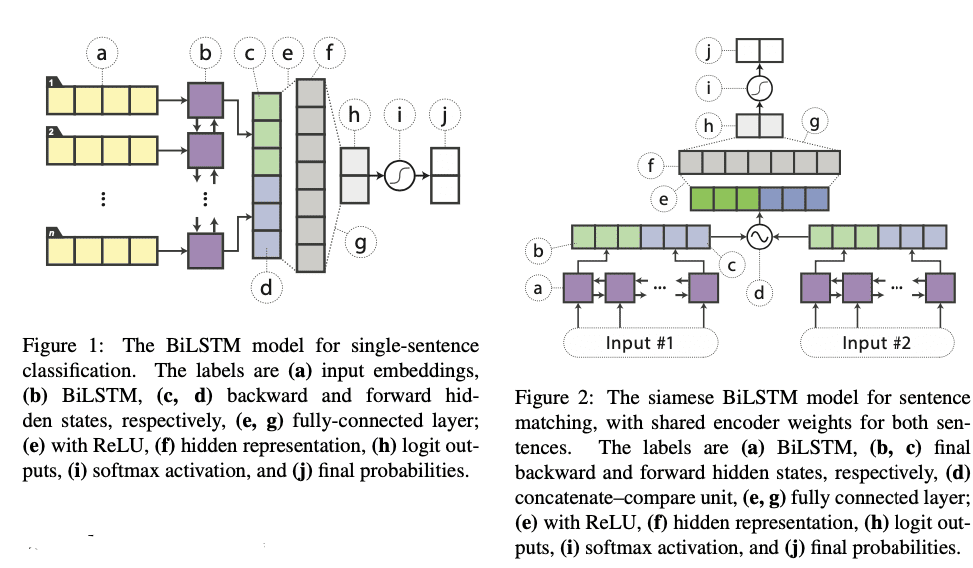
Source | Reference video by paper authors
Data Augmentation for Distillation
A small dataset may not be sufficient for teachers to express their knowledge fully, so the training set is augmented using a large unlabeled dataset with pseudo-labels generated from the teacher model. In this work, a few heuristics are proposed for task-agnostic data augmentation:
- Masking: randomly replace a word in a sentence with a [MASK] token similar to BERT training.
- POS-guided word replacement: replace a word with another word of the same POS(parts of speech) tag, e.g., “What do pigs eat?” is perturbed to “How do pigs eat?
- N-gram sampling: a more aggressive form of masking where n-gram samples are chosen from the input example, where n is randomly selected from {1,2,3,4,5}
Paper 6
Patient Knowledge Distillation for BERT Model Compression
The authors propose a Patient Knowledge Distillation approach to compress an original large model (teacher) into an equally-effective lightweight shallow network (student). Their method is quite distinct from previous knowledge distillation approaches because the earlier methods only use the output from the last layer of the teacher network for distillation; our student model patiently learns from multiple intermediate layers of the teacher model for incremental knowledge extraction, following two strategies:
- PKD-Last: student model learns from the last k layers of the teacher (assuming that the last layers contain the max information for the student).
- PKD-Skip: student model learns from every k layer of the teacher.
They experimented on several datasets across different NLP tasks demonstrating that the proposed PKD approach achieves better performance and generalization than standard distillation methods (Hinton et al., 2015).
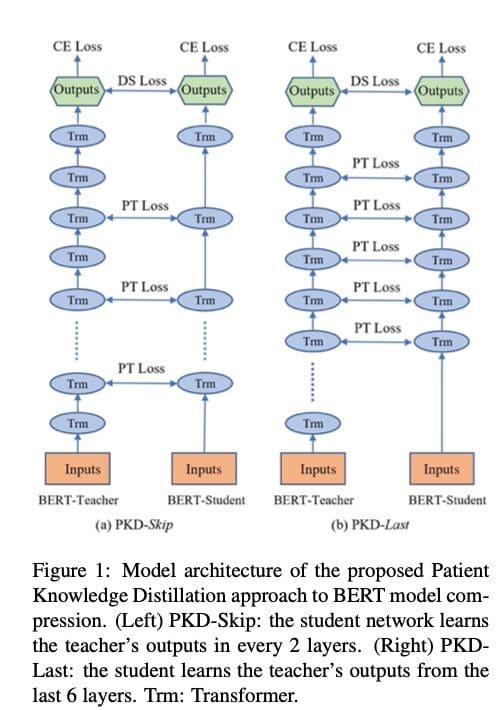
Source
Why not learn from all the hidden states of the teacher model?
The reason is that it can be computationally very expensive and can introduce noise into the student model.
Paper 7
MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices
They propose MobileBERT for compressing and accelerating the popular BERT model. Like the original BERT, MobileBERT is task-agnostic; that is, it can be generically applied to various downstream NLP tasks via simple fine-tuning. MobileBERT is a thin version of BERTʟᴀʀɢᴇ, while equipped with bottleneck structures and a carefully designed balance between self-attentions and feed-forward networks.
Training Steps
Step one: first train a specially designed teacher model, an inverted bottleneck incorporated BERTʟᴀʀɢᴇ model.
Step two: conduct knowledge transfer from this teacher to MobileBERT.
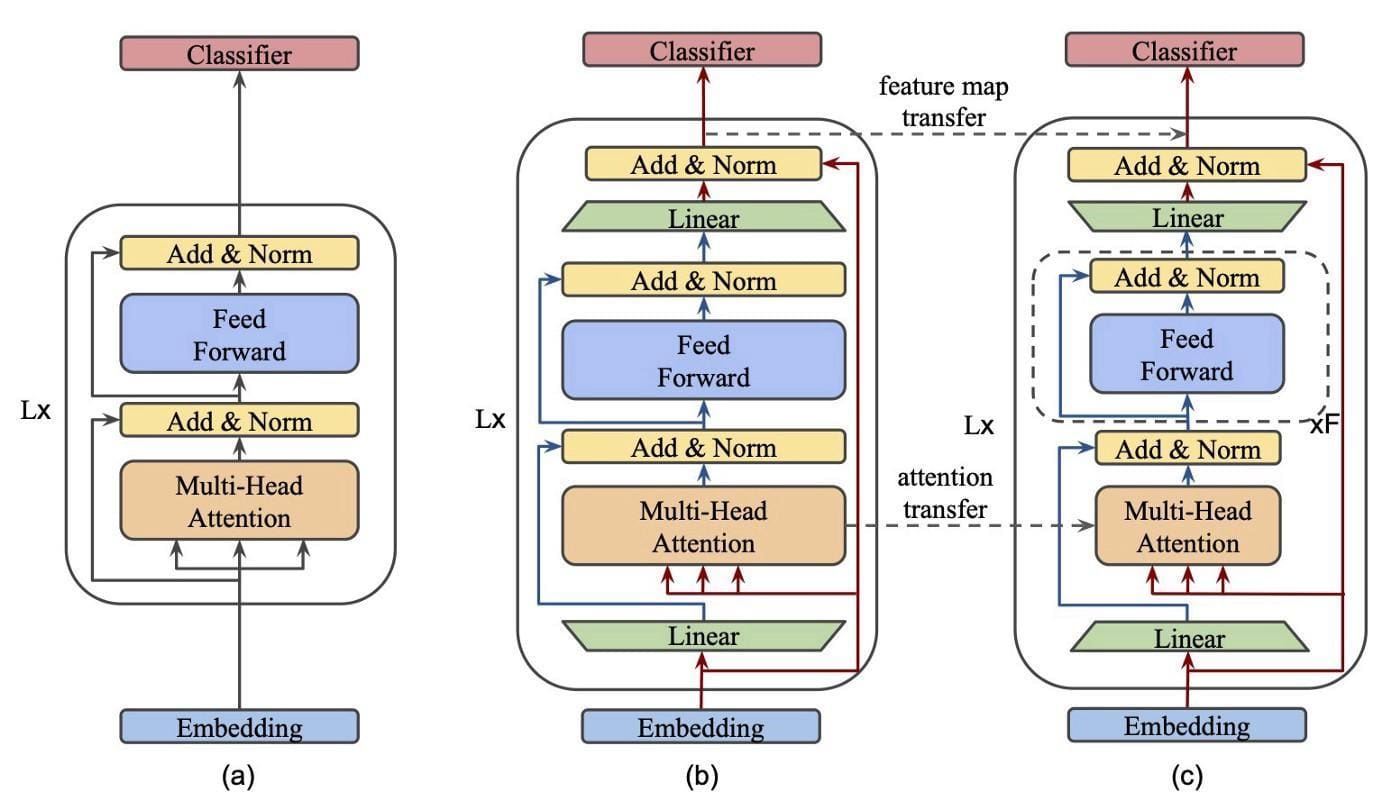
Architecture visualization of transformer blocks within (a) BERT, (b) MobileBERT teacher, and © MobileBERT student. The green trapezoids marked with “Linear” are referred to as bottlenecks. Source
(a) BERT; (b) Inverted-Bottleneck BERT (IB-BERT); and © MobileBERT. In (b) and ©, red lines denote inter-block flows while blue lines intra-block flow. MobileBERT is trained by layer-to-layer imitating IB-BERT.
If you have made it this far, you deserve a high-five. MobileBERT presents bottlenecks in transformer blocks, which distills the knowledge out of larger teachers into smaller students more smoothly. This approach decreases the width instead of the depth of the student, which is famous for generating a more proficient model which yields true in the given experiments. MobileBERT underlines the conviction that it’s achievable to make a student model that can be fine-tuned after the initial distillation process.
Moreover, the outcomes also indicate that this holds true in practice, as MobileBERT can attain 99.2% of BERT-base’s performance on GLUE with 4x fewer parameters and 5.5x faster inference on a Pixel 4 phone!
Paper 8
The key focus of the paper is as follows:
- Train a multi-task neural net model which combines loss across multiple natural language understanding tasks.
- Generate an ensemble of multiple models from the first step, which are essentially obtained by training multiple multi-task models from scratch
- The final step is to knowledge distill the ensemble of models from the previous step.
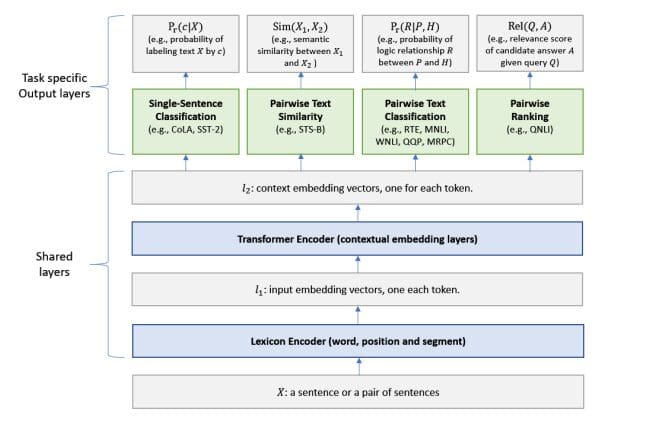
The architecture of the MT-DNN model for representation learning (Liu et al., 2019). The lower layers are shared across all tasks, while the top layers are task-specific. The input X (either a sentence or a set of sentences) is first represented as a sequence of embedding vectors, one for each word, in l1. Then the Transformer encoder captures the contextual information for each word and generates the shared contextual embedding vectors in l2. Finally, additional task-specific layers generate task-specific representations for each task, followed by operations necessary for classification, similarity scoring, or relevance ranking. Source

Process of knowledge distillation for multi-task learning. A set of tasks where there is task-specific labeled training data are picked. Then, an ensemble of different neural nets (teacher) is trained for each task. The teacher is used to generate a set of soft targets for each task-specific training sample. Given the soft targets of the training datasets across multiple tasks, a single MT-DNN (student) is trained using multi-task learning and backpropagation as described in Algorithm 1, except that if task t has a teacher, the task-specific loss in Line 3 is the average of two objective functions, one for the correct targets and the other for the soft targets assigned by the teacher. Source
Achievements: On the GLUE datasets, the distilled MT-DNN creates a new state-of-the-art result on 7 out of 9 NLU tasks, including the tasks with no teacher, pushing the GLUE benchmark (single model) to 83.7%.
We show that the distilled MT-DNN retains nearly all of the improvements achieved by ensemble models while keeping the model size the same as the vanilla MT-DNN model.
The EndNote
Contemporary state-of-the-art NLP models are difficult to be utilized in production. Knowledge distillation offers tools for tackling such issues along with several others, but it has its quirks.
References
- Distilling the Knowledge in a Neural Network
A very simple way to improve the performance of almost any machine learning algorithm is to train many different models…arxiv.org
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations…arxiv.org
- Distilling Knowledge Learned in BERT for Text Generation
Large-scale pre-trained language model such as BERT has achieved great success in language understanding tasks…arxiv.org
- DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
As Transfer Learning from large-scale pre-trained models becomes more prevalent in Natural Language Processing (NLP)…arxiv.org
- TinyBERT: Distilling BERT for Natural Language Understanding
Language model pre-training, such as BERT, has significantly improved the performances of many natural language…arxiv.org
- Distilling the Knowledge in a Neural Network
A very simple way to improve the performance of almost any machine learning algorithm is to train many different models…arxiv.org
- FastBERT: a Self-distilling BERT with Adaptive Inference Time
Pre-trained language models like BERT have proven to be highly performant. However, they are often computationally…arxiv.org
- Distilling Task-Specific Knowledge from BERT into Simple Neural Networks
In the natural language processing literature, neural networks are becoming increasingly deeper and complex. The recent…arxiv.org
- Patient Knowledge Distillation for BERT Model Compression
Pre-trained language models such as BERT have proven to be highly effective for natural language processing (NLP)…arxiv.org
- Distilling the Knowledge in a Neural Network
A very simple way to improve the performance of almost any machine learning algorithm is to train many different models…arxiv.org
- MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices
Natural Language Processing (NLP) has recently achieved great success by using huge pre-trained models with hundreds of…arxiv.org
- Improving Multi-Task Deep Neural Networks via Knowledge Distillation for Natural Language…
This paper explores the use of knowledge distillation to improve a Multi-Task Deep Neural Network (MT-DNN) (Liu et al…arxiv.org
"Opinions expressed here are of Mr. Abhishek, not his employer"
Kumar Abhishek is Machine Learning Engineer at Expedia, working in the domain of fraud detection and prevention. He uses Machine Learning and Natural Language Processing models for risk analysis and fraud detection. He has more than a decade of machine learning and software engineering experience.