Overcoming Barriers in Multi-lingual Voice Technology: Top 5 Challenges and Innovative Solutions
Voice assistants like Siri, Alexa and Google Assistant are household names, but they still don't do well in multilingual settings. This article first provides an overview of how voice assistants work, and then dives into the top 5 challenges for voice assistants when it comes to providing a superior multilingual user experience. It also provides strategies for mitigation of these challenges.
Introduction
How often have you had to pause after asking your voice assistant about something in Spanish, your preferred language, and then restate your ask in the language that the voice assistant understands, likely English, because the voice assistant did not understand your request in Spanish? Or how often have you had to deliberately mis-pronounce your favorite artist A. R. Rahman’s name when asking your voice assistant to play their music because you know that if you say their name the right way, the voice assistant will simply not understand, but if you say A. R. Ramen the voice assistant will get it? Further, how often have you cringed when the voice assistant, in their soothing, all-knowing voice, butcher the name of your favorite musical Les Misérables and distinctly pronounce it as "Les Miz-er-ables"?
Despite voice assistants having become mainstream about a decade ago, they continue to remain simplistic, specifically in their understanding of user requests in multilingual contexts. In a world where multi-lingual households are on the rise and the existing and potential user base is becoming increasingly global and diverse, it is critical for voice assistants to become seamless when it comes to understanding user requests, irrespective of their language, dialect, accent, tone, modulation, and other speech characteristics. However, voice assistants continue to lag woefully when it comes to being able to smoothly converse with users in a way that humans do with each other. In this article, we will dive into what the top challenges in making voice assistants operate multi-lingually are, and what some strategies to mitigate these challenges might be. We will use a hypothetical voice assistant, Nova, throughout this article, for illustration purposes.
How Voice Assistants Work
Before diving into the challenges and opportunities with respect to making voice assistant user experiences multilingual, let’s get an overview of how voice assistants work. Using Nova as the hypothetical voice assistant, we look at how the end-to-end flow for asking for a music track looks like (reference).
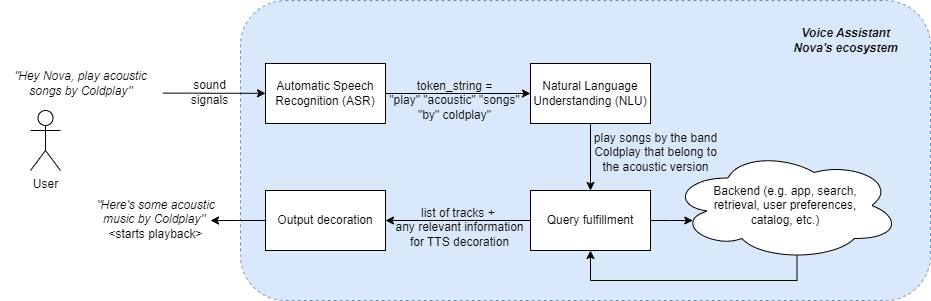
Fig. 1. End-to-end overview of hypothetical voice assistant Nova
As seen in Fig. 1., when a user asks Nova to play acoustic music by the popular band Coldplay, this sound signal of the user is first converted to a string of text tokens, as a first step in the human – voice assistant interaction. This stage is called Automatic Speech Recognition (ASR) or Speech to Text (STT). Once the string of tokens is available, it is passed on to the Natural Language Understanding step where the voice assistant tries to understand the semantic and syntactic meaning of the user’s intent. In this case, the voice assistant’s NLU interprets that the user is looking for songs by the band Coldplay (i.e. interprets that Coldplay is a band) that are acoustic in nature (i.e. look for meta data of songs in the discography of this band and only select the songs with version = acoustic). This user intent understanding is then used to query the back-end to find the content that the user is looking for. Finally, the actual content that the user is looking for and any other additional information needed to present this output to the user is carried forward to the next step. In this step, the response and any other information available is used to decorate the experience for the user and satisfactorily respond to the user query. In this case, it would be a Text To Speech (TTS) output (“here’s some acoustic music by Coldplay”) followed by a playback of the actual songs that were selected for this user query.
Challenges in Building Multi-lingual Voice Assistants
Multi-lingual voice assistants (VAs) imply VAs that are able to understand and respond to multiple languages, whether they are spoken by the same person or persons or if they are spoken by the same person in the same sentence mixed with another language (e.g. “Nova, arrêt! Play something else”). Below are the top challenges in voice assistants when it comes to being able to operate seamlessly in a multi-modal setting.
Inadequate Quantity and Quantity of Language Resources
In order for a voice assistant to be able to parse and understand a query well, it needs to be trained on a significant amount of training data in that language. This data includes speech data from humans, annotations for ground truth, vast amounts of text corpora, resources for improved pronunciation of TTS (e.g. pronunciation dictionaries) and language models. While these resources are easily available for popular languages like English, Spanish and German, their availability is limited or even non-existent for languages like Swahili, Pashto or Czech. Even though these languages are spoken by enough people, there aren’t structured resources available for these. Creating these resources for multiple languages can be expensive, complex and manually intensive, creating headwinds to progress.
Variations in Language
Languages have different dialects, accents, variations and regional adaptations. Dealing with these variations is challenging for voice assistants. Unless a voice assistant adapts to these linguistic nuances, it would be hard to understand user requests correctly or be able to respond in the same linguistic tone in order to deliver natural sounding and more human-like experience. For example, the UK alone has more than 40 English accents. Another example is how the Spanish spoken in Mexico is different from the one spoken in Spain.
Language Identification and Adaptation
It is common for multi-lingual users to switch between languages during their interactions with other humans, and they might expect the same natural interactions with voice assistants. For example, “Hinglish” is a commonly used term to describe the language of a person who uses words from both Hindi and English while talking. Being able to identify the language(s) the user is interacting with the voice assistant in and adapting responses accordingly is a difficult challenge that no mainstream voice assistant can do today.
Language Translation
One way to scale the voice assistant to multiple languages could be translating the ASR output from a not-so-mainstream language like Luxembourgish into a language that can be interpreted by the NLU layer more accurately, like English. Commonly used translation technologies include using one or more techniques like Neural Machine Translation (NMT), Statistical Machine Translation (SMT), Rule-based Machine Translation (RBMT), and others. However, these algorithms might not scale well for diverse language sets and might also require extensive training data. Further, language-specific nuances are often lost, and the translated versions often seem awkward and unnatural. The quality of translations continues to be a persistent challenge in terms of being able to scale multi-lingual voice assistants. Another challenge in the translation step is the latency it introduces, degrading the experience of the human – voice assistant interaction.
True Language Understanding
Languages often have unique grammatical structures. For example, while English has the concept of singular and plural, Sanskrit has 3 (singular, dual, plural). There might also be different idioms that don’t translate well to other languages. Finally, there might also be cultural nuances and cultural references that might be poorly translated, unless the translating technique has a high quality of semantic understanding. Developing language specific NLU models is expensive.
Overcoming Challenges in Building Multi-lingual Voice Assistants
The challenges mentioned above are hard problems to solve. However, there are ways in which these challenges can be mitigated partially, if not fully, right away. Below are some techniques that can solve one or more of the challenges mentioned above.
Leverage Deep Learning to Detect Language
The first step in interpreting the meaning of a sentence is to know what language the sentence belongs to. This is where deep learning comes into the picture. Deep learning uses artificial neural networks and high volumes of data to create output that seems human-like. Transformer-based architecture (e.g. BERT) have demonstrated success in language detection, even in the cases of low resource languages. An alternative to transformer-based language detection model is a recurrent neural network (RNN). An example of the application of these models is that if a user who usually speaks in English suddenly talks to the voice assistant in Spanish one day, the voice assistant can detect and ID Spanish correctly.
Use Contextual Machine Translation to ‘Understand’ the Request
Once the language has been detected, the next step towards interpreting the sentence is to take the output of the ASR stage, i.e., the string of tokens, and translate this string, not just literally but also semantically, into a language that can be processed in order to generate a response. Instead of using translation APIs that might not always be aware of the context and peculiarities of the voice interface and also introduce suboptimal delays in responses because of high latency, degrading the user experience. However, if context-aware machine translation models are integrated into voice assistants, the translations can be of higher quality and accuracy because of being specific to a domain or the context of the session. For example, if a voice assistant is being used mainly for entertainment, it can leverage contextual machine translation to correctly understand and respond to questions about genres and sub-genres of music, musical instruments and notes, cultural relevance of certain tracks, and more.
Capitalize on Multi-lingual Pre-trained Models
Since every language has a unique structure and grammar, cultural references, phrases, idioms and expressions and other nuances, it is challenging to process diverse languages. Given language specific models are expensive, pre-trained multi-lingual models can help capture language specific nuances. Models like BERT and XLM-R are good examples of pre-trained models that can capture language specific nuances. Lastly, these models can be fine-tuned to a domain to further increase their accuracy. For example, for a model trained on the music domain might be able to not just understand the query but also return a rich response via a voice assistant. If this voice assistant is asked what the meaning behind the lyrics of a song are, the voice assistant will be able to answer the question in a much richer way than a simple interpretation of the words.
Use Code Switching Models
Implementing code switching models for being able to handle language input that is a mix of different languages can help in the cases where a user uses more than one language in their interactions with the voice assistant. For example, if a voice assistant is designed specifically for a region in Canada where users often mix up French and English, a code-switching model can be used to understand sentences directed to the voice assistant that are a mix of the two languages and the voice assistant will be able to handle it.
Leverage Transfer Learning and Zero Shot Learning for Low Resource Languages
Transfer learning is a technique in ML where a model is trained on one task but is used as a starting point for a model on a second task. It uses the learning from the first task to improve the performance of the second task, thus overcoming the cold-start problem to an extent. Zero shot learning is when a pre-trained model is used to process data it has never seen before. Both Transfer Learning and Zero Shot learning can be leveraged to transfer knowledge from high-resource languages into low-resource languages. For example, if a voice assistant is already trained on the top 10 languages spoken most commonly in the world, it could be leveraged to understand queries in low resource languages like Swahili.
Conclusion
In summary, building and implementing multilingual experiences on voice assistants is challenging, but there are also ways to mitigate some of these challenges. By addressing the challenges called out above, voice assistants will be able to provide a seamless experience to their users, irrespective of their language.
Note: All content and opinions presented in this article belong to the individual writing the article alone and are not representative in any shape or form of their employer
Ashlesha Kadam leads a global product team at Amazon Music that builds music experiences on Alexa and Amazon Music apps (web, iOS, Android) for millions of customers across 45+ countries. She is also a passionate advocate for women in tech, serving as co-chair for the Human Computer Interaction (HCI) track for Grace Hopper Celebration (biggest tech conference for women in tech with 30K+ participants across 115 countries). In her free time, Ashlesha loves reading fiction, listening to biz-tech podcasts (current favorite - Acquired), hiking in the beautiful Pacific Northwest and spending time with her husband, son and 5yo Golden Retriever.