Overcoming Imbalanced Data Challenges in Real-World Scenarios
Techniques to address imbalanced data in the context of classification, while keeping the data distribution in mind.
Benchmarking the performance of popular NLP architectures is an important step in building an understanding of available options when approaching the text classification task. Here we’ll go deeper into the meat of it and explore one of the most common challenges associated with the classification — data imbalance. And if you ever applied ML to a real-world classification dataset, you’re most likely familiar with it.
Understanding Imbalance in Data Classification
In data classification, we're often concerned with the distribution of data points across classes. A balanced dataset has roughly the same number of points in all classes, making it easier to work with. However, real-world datasets are often imbalanced.
Imbalanced data can cause problems because a model might learn to label everything with the most frequent class, ignoring the actual input. This can happen if the dominant class is so prevalent that the model isn't penalized much for misclassifying the minority class. Additionally, underrepresented classes may not have enough data for the model to learn meaningful patterns.
Is imbalance something that needs to be corrected? Imbalance is a feature of data, and a good question to start with is whether we want to do anything about it at all. There are tricks to make the training process easier for a model. Optionally, we might manipulate the training process or the data itself to let the model know which classes are especially important for us but it should be justified by a business need or domain knowledge. Further, we’ll discuss these tricks and manipulations in more detail.
To illustrate the effect of different techniques addressing data imbalance we’ll use the sms-spam dataset, which contains 747 spam and 4827 ham (legitimate) texts. Though there are only two classes, the task will be treated as a multiclass classification problem for better generalization. We’ll use a roberta-base model.
Keep in mind that these techniques may produce different results with other data. It's essential to test them on your specific dataset.
When training a classification model without any adjustments, we get the following classification report:
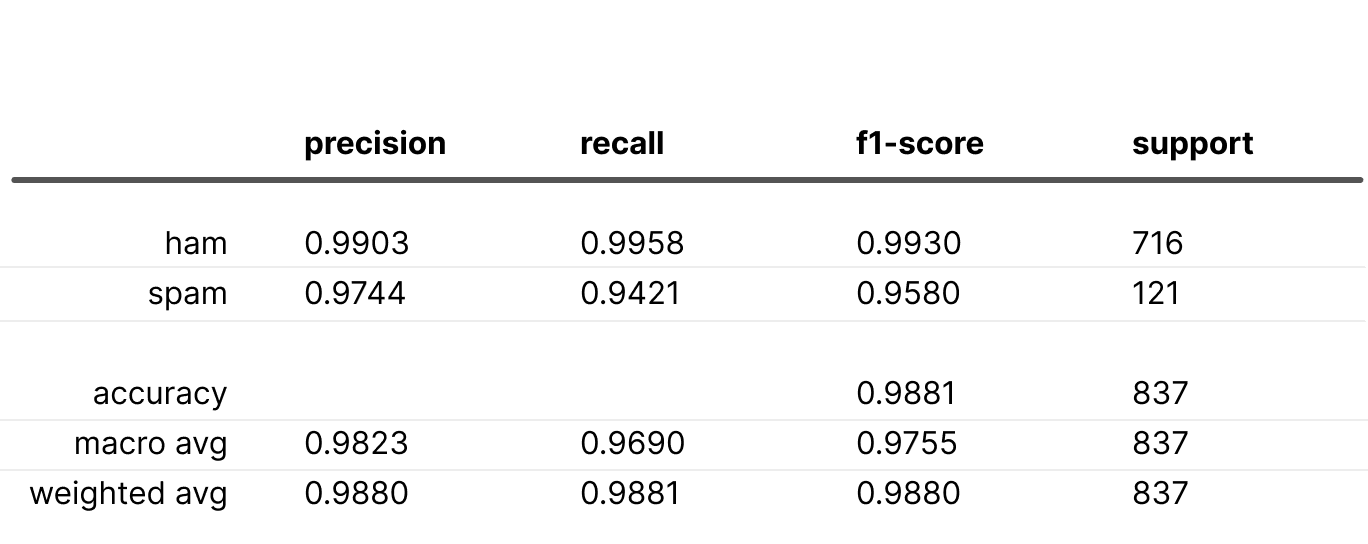
“Safe” tricks
Bias Initialization
Our first technique is to let the model know about data distribution from the beginning. We could propagate this knowledge by initializing the bias of the final classification layer accordingly. This trick, shared by Andrej Karpathy in his Recipe for Training Neural Networks, helps the model start with an informed perspective. In our case of multiclass classification, we use softmax as the final activation, and we want the model's output at initialization to reflect the data distribution. To achieve this, we solve the following:
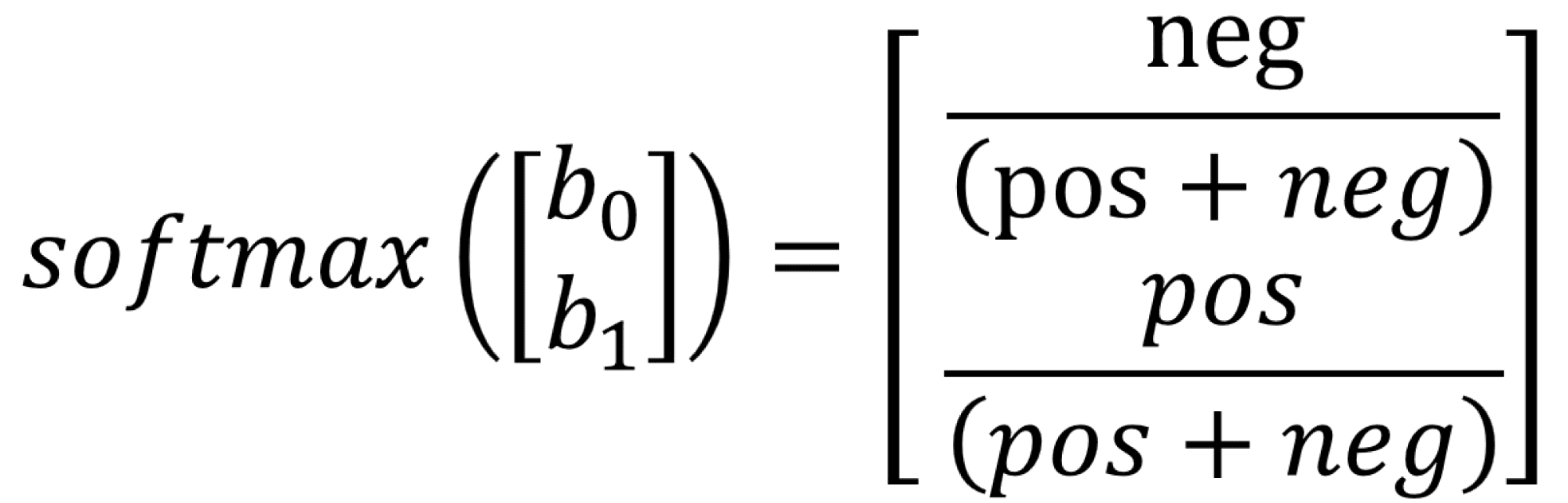
As a reminder,
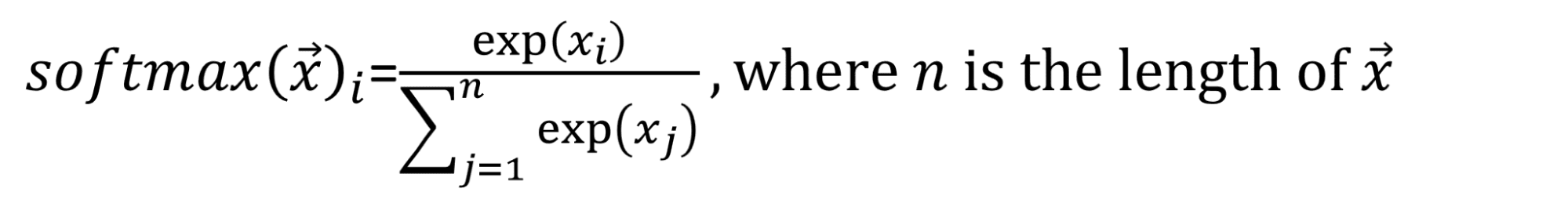
Then,
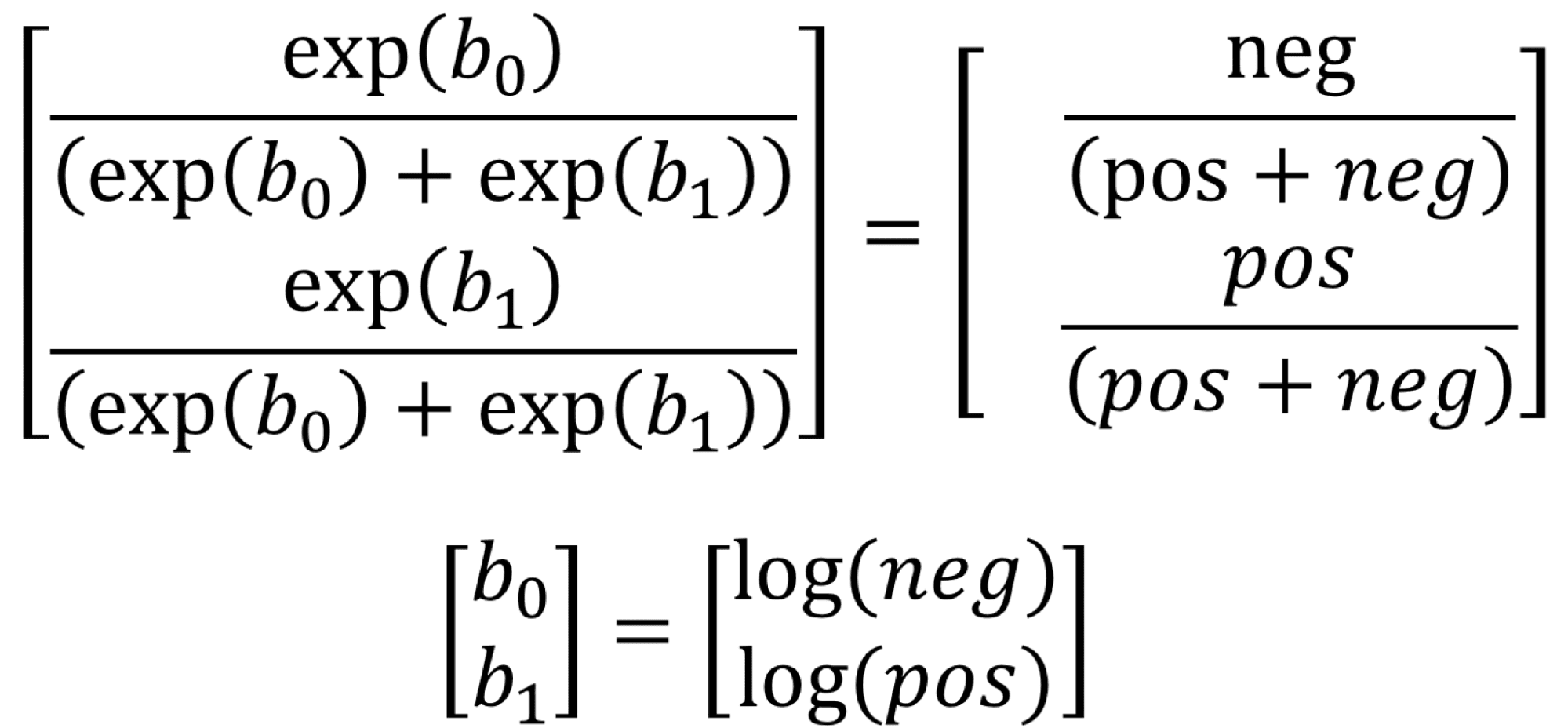
Here b0 and b1 are biases of negative and positive classes correspondingly, neg and pos are the number of elements in negative and positive classes.
With this initialization, all metrics simply improve!
In Bayesian terms, this means manually setting a prior and allowing the model to learn the posterior during training.
Downsampling and Upweighting/Upsampling and Downweighting
These techniques also address class imbalance effectively. Both share a similar concept but differ in execution. Downsampling and upweighting involves reducing the size of the dominant class to balance the distribution, while assigning larger weights to examples from this class during training. The upweighting ensures that output probabilities still represent the observed data distribution. Conversely, upsampling and downweighting entails increasing the size of underrepresented classes and proportionally reducing their weights.
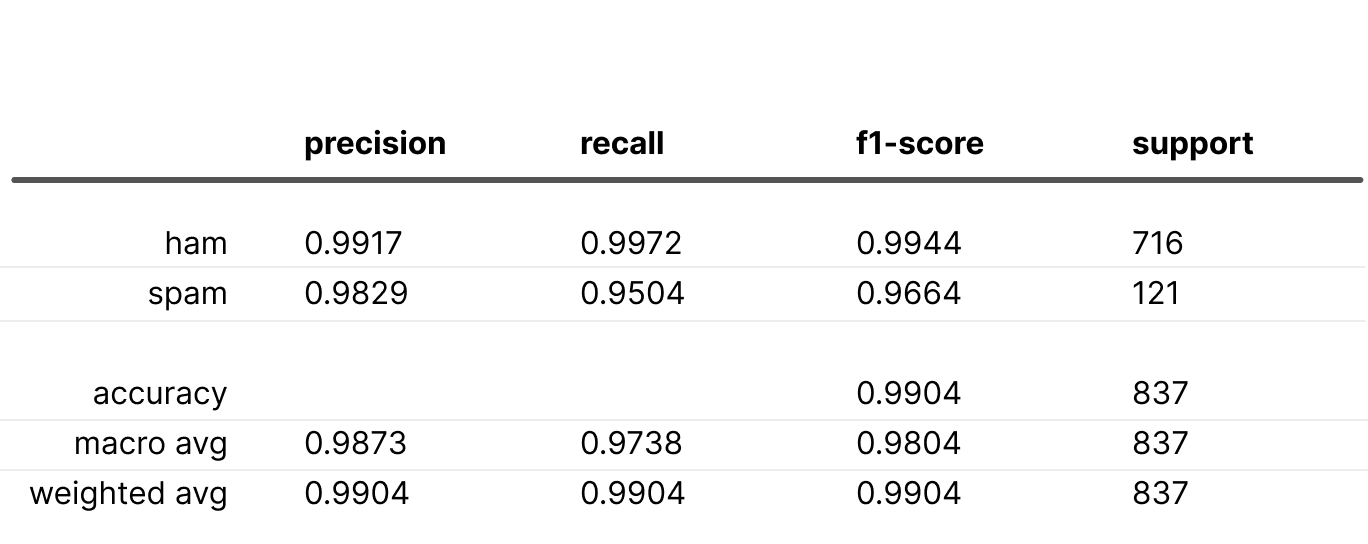
Downsampling and upweighting outcome:
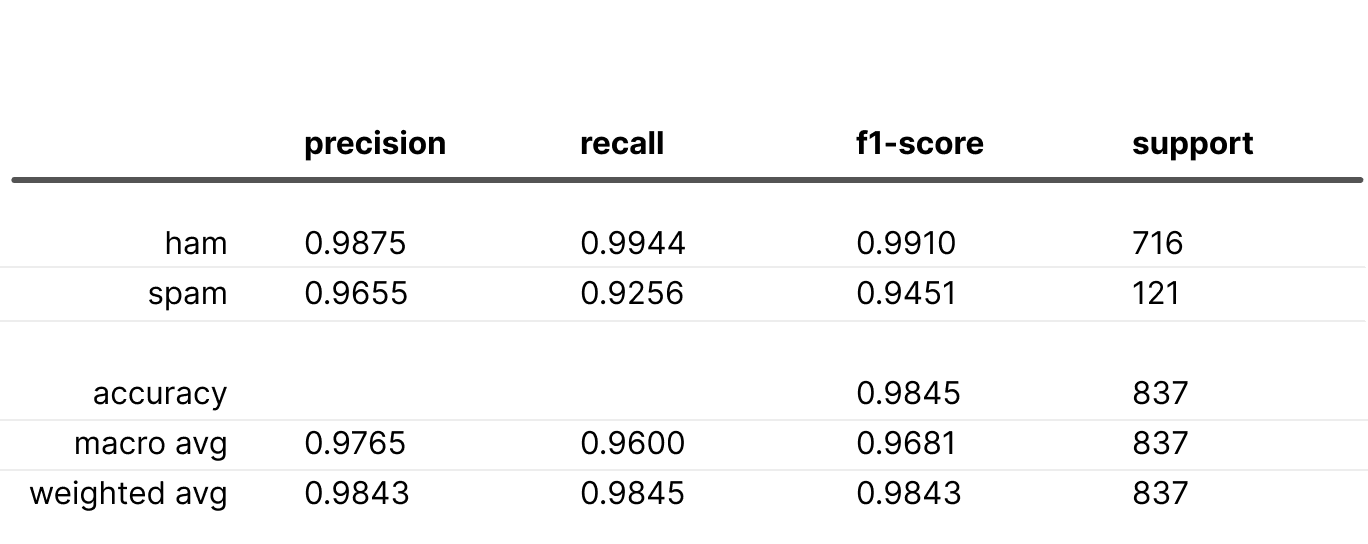
Upsampling and downweighting outcome:
In both scenarios, the “spam” recall decreased, likely because the "ham" weight was twice that of the “spam” weight.
Focal Loss
Focal loss, referred to by the authors as a “dynamically scaled cross entropy loss”, was introduced to address training on imbalanced data . It's applicable to binary cases only, and luckily, our problem involves just two classes. Check out the equation below:
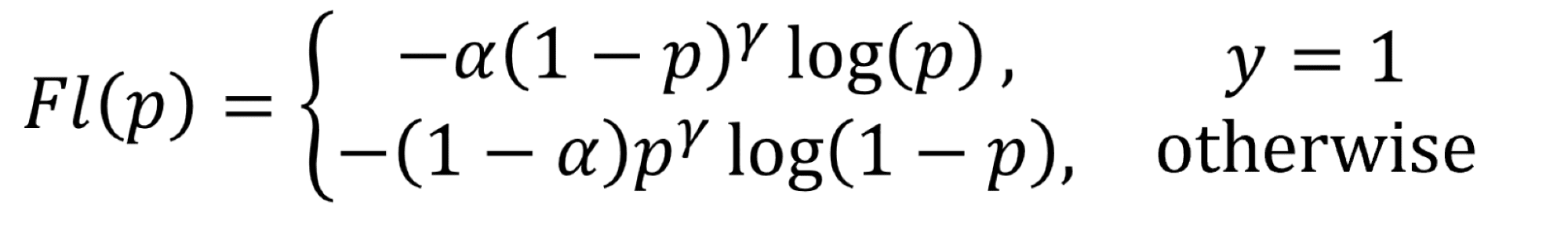
In the equation, p is the probability of a true class, ɑ is a weighting factor, and ???? controls how much we penalize loss depending on confidence (probability).
The design ensures that examples with lower probability receive exponentially greater weight, pushing the model to learn about more challenging examples. The alpha parameter allows for different weighting between class examples.
By tuning the alpha and gamma combination, you can find the optimal configuration. To remove explicit class preference, set alpha to 0.5; however, authors have noted minor improvements with this balancing factor.
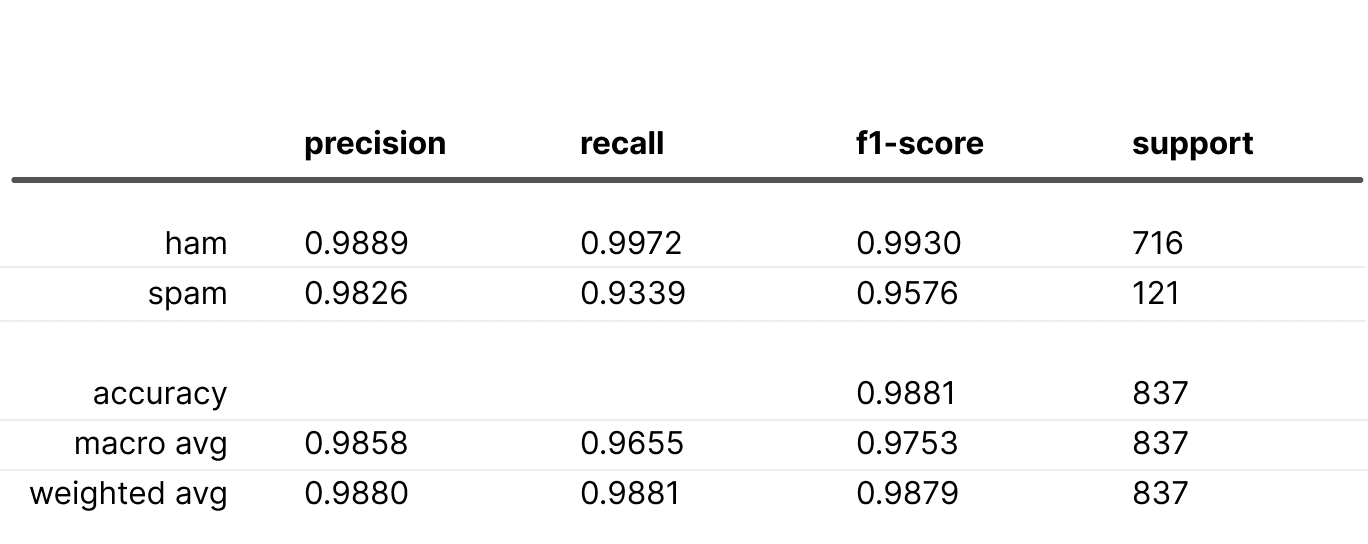
Here is the best result we obtained with focal loss:
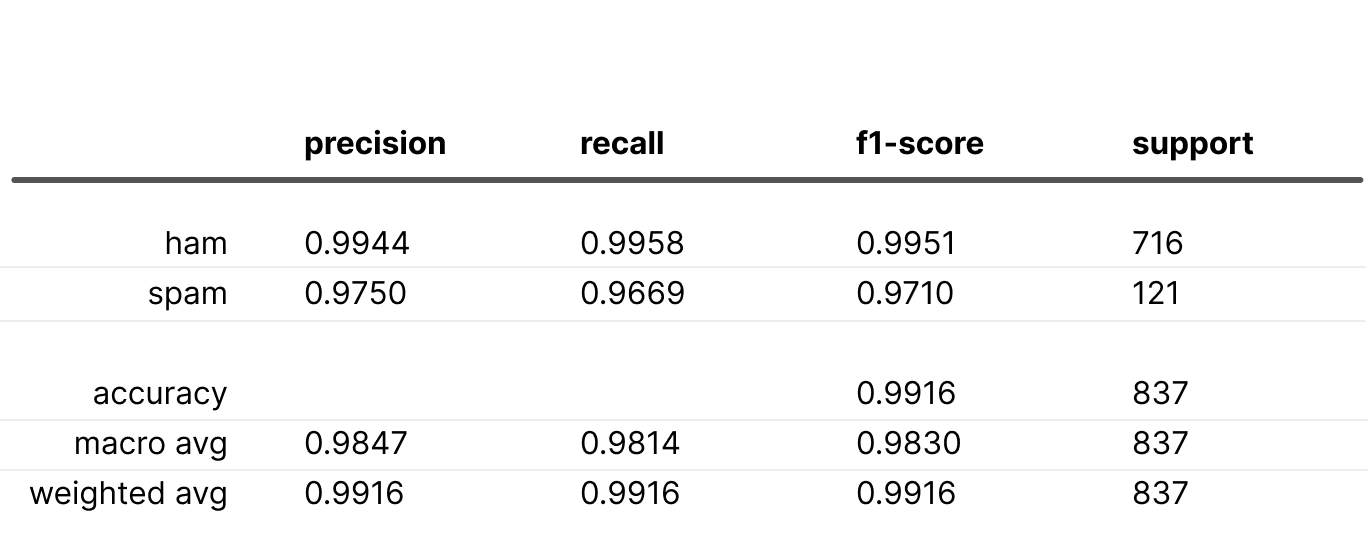
All metrics outperform the baseline, but it required some parameter adjustments. Keep in mind, it might not always work out this smoothly.
“Not-so-safe” Tricks
There exist well-known methods that intentionally alter the output probability distribution to give underrepresented classes an advantage. By using these techniques, we explicitly signal to the model that certain classes are crucial and shouldn’t be overlooked. This is often driven by a business need, like detecting financial fraud or offensive comments, which is more important than accidentally mislabeling good examples. Apply these techniques when the goal is to boost recall for specific classes, even if it means sacrificing other metrics.
Weighting
Weighting involves assigning unique weights to loss values for samples from different classes. This is an effective and adaptable method because it lets you indicate the significance of each class to the model. Here’s the formula for a multiclass weighted cross-entropy loss for a single training example:

,
where pytrue represents the probability of the true class and wytrue is the weight of that class.
A good default method for determining weights is the inverse class frequency:

where N is the dataset's total items, c is the class count, and ni is the ith class's element count
The weights were calculated as follows: {'ham': 0.576, 'spam': 3.784}
Below are the metrics obtained using these weights:
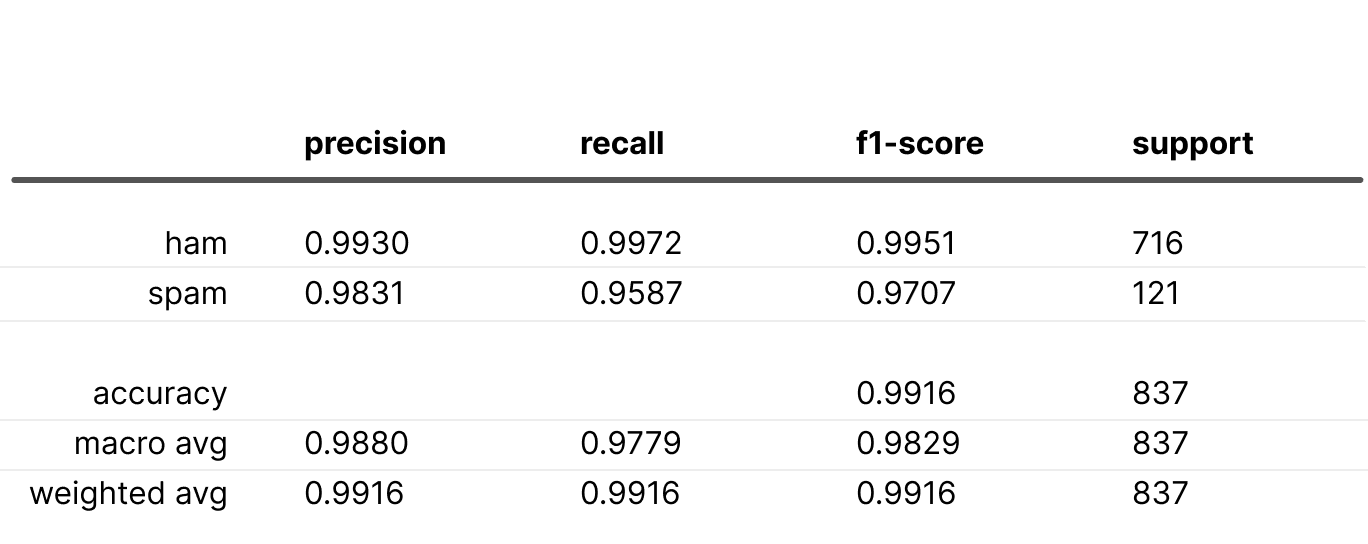
The metrics surpass the baseline scenario. While this may occur, it's not always the case.
However, if avoiding missed positives from a specific class is vital, consider increasing the class weight, which could likely boost the class recall. Let’s try the weights {"ham": 0.576, "spam": 10.0} to see the outcome.
Results are as follows:
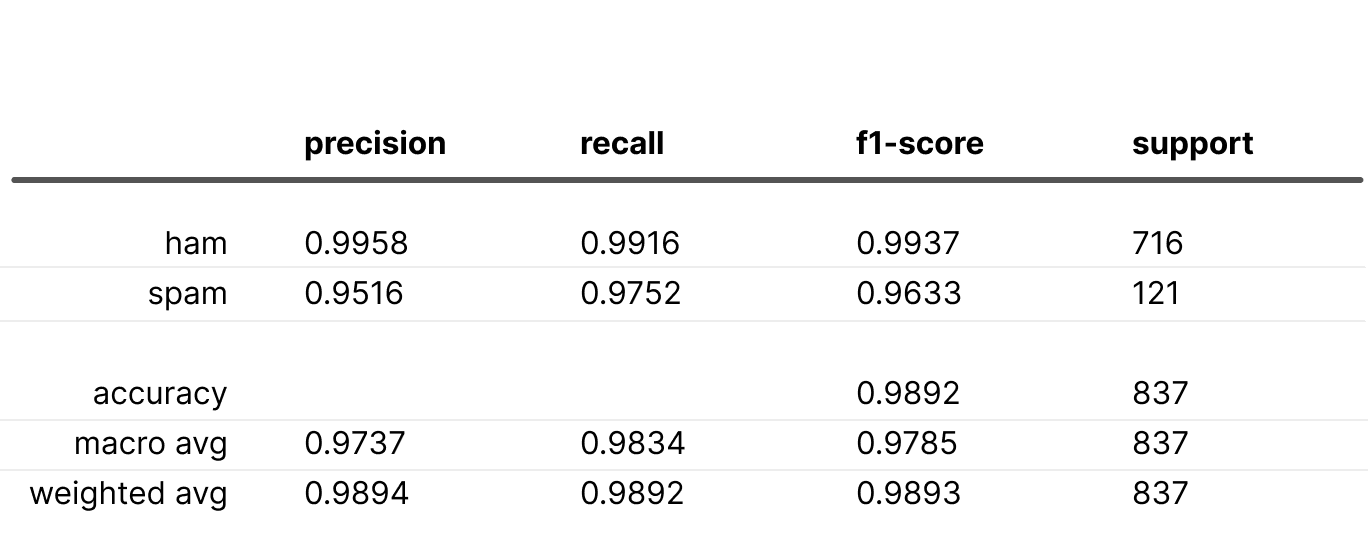
As anticipated, the “spam” recall increased, though precision declined. The F1 score worsened compared to using inverse class frequency weights. This demonstrates the potential of basic loss weighting. Weighting may be beneficial even for balanced data to recall crucial classes.
Upsampling and downsampling.
While similar to the methods discussed earlier, they don't include the weighting step. Downsampling may result in data loss, while upsampling can lead to overfitting the upsampled class. Though they can help, weighting is often a more efficient and transparent option.
Comparing the Probabilities
We’ll assess the confidence of various model versions using an obvious spam-looking example: "Call to claim your prize!" See the table below for results.
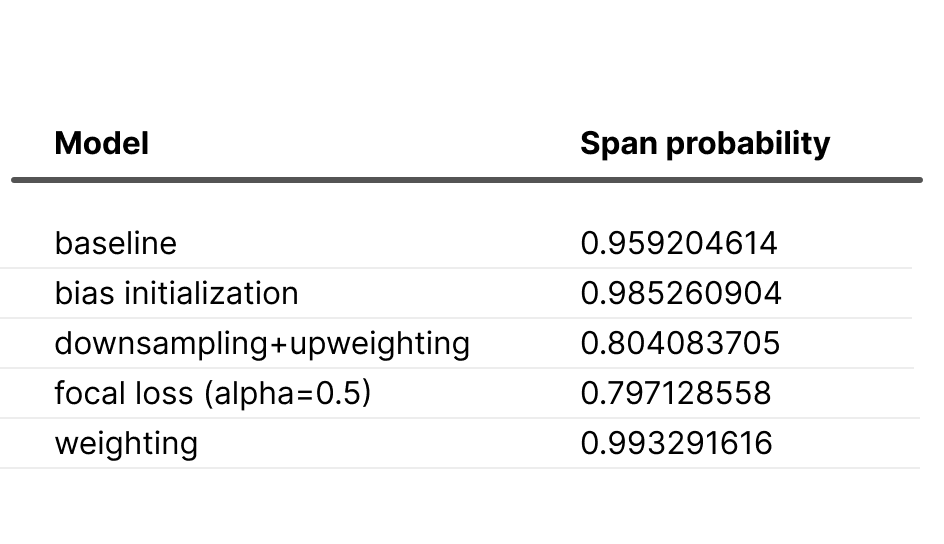
As anticipated, the weighted model shows overconfidence, while the “downsampling + upweighting” model is underconfident (due to upweighted “ham”) compared to the baseline. Notably, bias initialization increases and focal loss decreases the model’s confidence in the “spam” category.
Summary
In conclusion, addressing data imbalance is possible when necessary. Keep in mind that some techniques intentionally alter the distribution and should only be applied when required. Imbalance is a feature, not a bug!
While we discussed probabilities, the ultimate performance metric is the one most important to the business. If offline tests show a model adds value, go ahead and test it in production.
In my experiments, I used the Toloka ML platform. It offers a range of ready-to-use models that can give a head start to an ML project.
Overall, considering data distributions for training ML models is crucial. The training data must represent the real-world distribution for the model to work effectively. If the data is inherently imbalanced, the model should account for it to perform well in real-life scenarios.
Sergei Petrov is a Data Scientist working with a range of Deep Learning applications. His interests are around building efficient and scalable Machine Learning solutions beneficial for businesses and society.