Building Microservice for Multi-Chat Backends Using Llama and ChatGPT
As LLMs continue to evolve, integrating multiple models or switching between them has become increasingly challenging. This article suggests a Microservice approach to separate model integration from business applications and simplify the process.
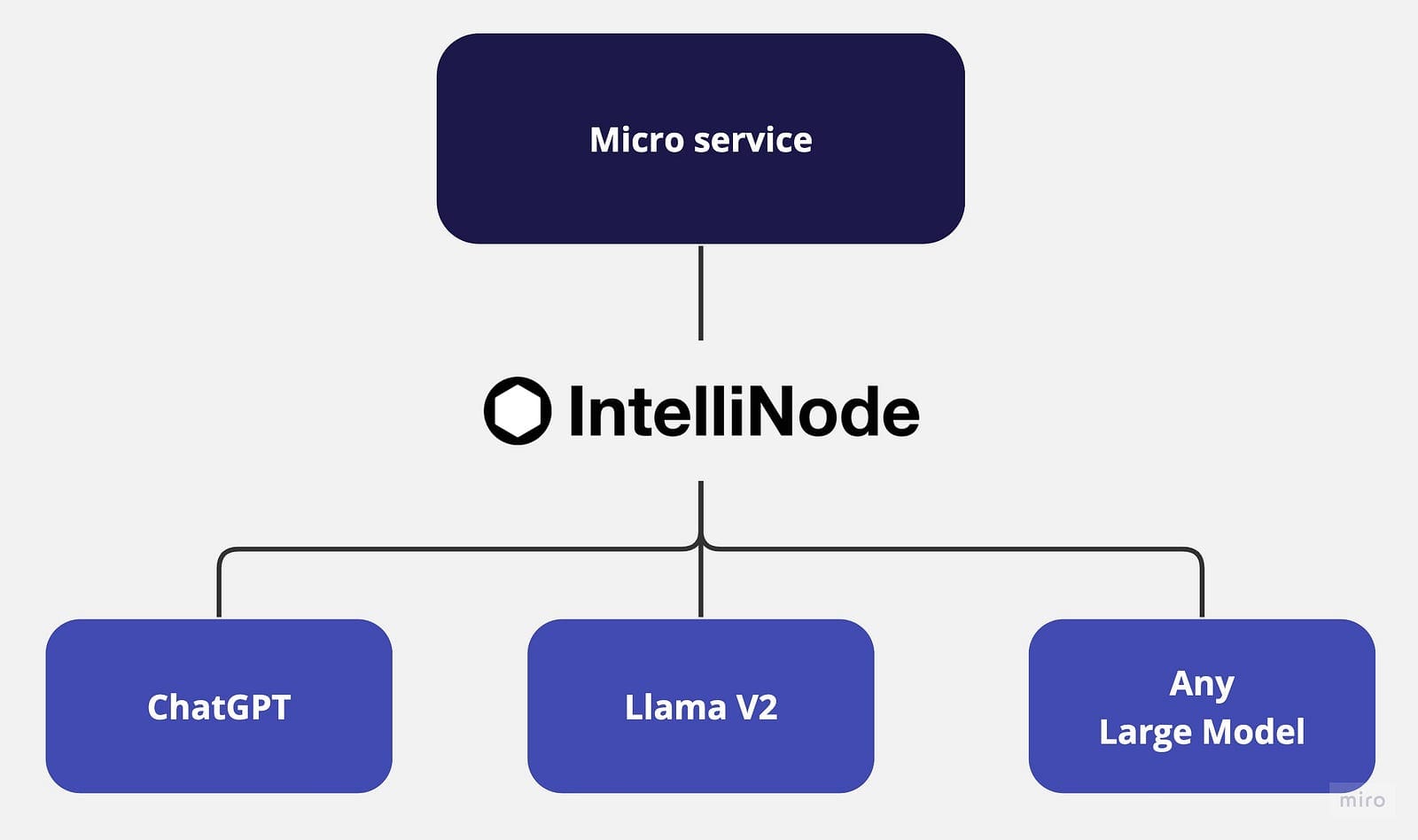
Microservices architecture promotes the creation of flexible, independent services with well-defined boundaries. This scalable approach enables developers to maintain and evolve services individually without affecting the entire application. However, realizing the full potential of microservices architecture, particularly for AI-powered chat applications, requires robust integration with the latest Large Language Models (LLMs) like Meta Llama V2 and OpenAI’s ChatGPT and other fine-tuned released based on each application use case to provide a multi-model approach for a diversified solution.
LLMs are large-scale models that generate human-like text based on their training on diverse data. By learning from billions of words on the internet, LLMs understand the context and generate tuned content in various domains. However, the integration of various LLMs into a single application often poses challenges due to the requirement of unique interfaces, access endpoints, and specific payloads for each model. So, having a single integration service that can handle a variety of models improves the architecture design and empowers the scale of independent services.
This tutorial will introduce you to IntelliNode integrations for ChatGPT and LLaMA V2 in a microservice architecture using Node.js and Express.
Chatbot Integration Options
Here are a few chat integration options provided by IntelliNode:
- LLaMA V2: You can integrate the LLaMA V2 model either via Replicate’s API for a straightforward process or via your AWS SageMaker host for an additional control.
LLaMA V2 is a powerful open source Large Language Model (LLM) that has been pre-trained and fine-tuned with up to 70B parameters. It excels in complex reasoning tasks across various domains, including specialized fields like programming and creative writing. Its training methodology involves self-supervised data and alignment with human preferences through Reinforcement Learning with Human Feedback (RLHF). LLaMA V2 surpasses existing open-source models and is comparable to closed-source models like ChatGPT and BARD in usability and safety.
- ChatGPT: By simply providing your OpenAI API key, IntelliNode module allows integration with the model in a simple chat interface. You can access ChatGPT through GPT 3.5 or GPT 4 models. These models have been trained on vast amounts of data and fine-tuned to provide highly contextual and accurate responses.
Step-by-Step Integration
Let’s start by initializing a new Node.js project. Open up your terminal, navigate to your project’s directory, and run the following command:
npm init -y
This command will create a new `package.json` file for your application.
Next, install Express.js, which will be used to handle HTTP requests and responses and intellinode for LLM models connection:
npm install express
npm install intellinode
Once the installation concludes, create a new file named `app.js` in your project’s root directory. then, add the express initializing code in `app.js`.
Code by Author
Llama V2 Integration Using Replicate’s API
Replicate provides a fast integration path with Llama V2 through API key, and IntelliNode provides the chatbot interface to decouple your business logic from the Replicate backend allowing you to switch between different chat models.
Let’s start by integrating with Llama hosted in Replica’s backend:
Code by Author
Get your trial key from replicate.com to activate the integration.
Llama V2 Integration Using AWS SageMaker
Now, let’s cover Llama V2 integration via AWS SageMaker, providing privacy and extra layer of control.
The integration requires to generate an API endpoint from your AWS account, first we will setup the integration code in our micro service app:
Code by Author
The following steps are to create a Llama endpoint in your account, once you set up the API gateway copy the URL to use for running the ‘/llama/aws’ service.
To setup a Llama V2 endpoint in your AWS account:
1- SageMaker Service: select the SageMaker service from your AWS account and click on domains.

aws account-select sagemaker
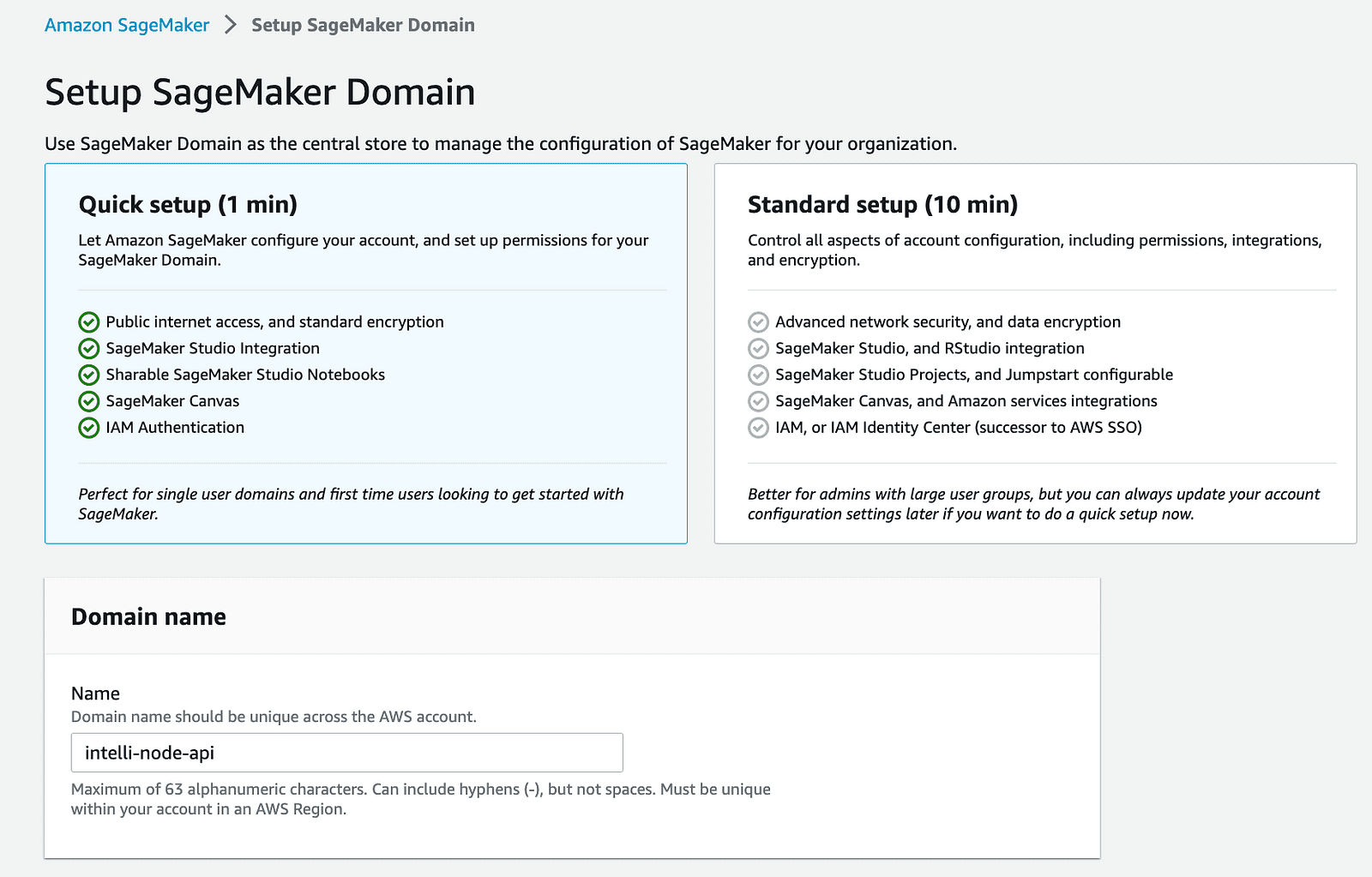
2- Create a SageMaker Domain: Begin by creating a new domain on your AWS SageMaker. This step establishes a controlled space for your SageMaker operations.
aws account-sagemaker domain
3- Deploy the Llama Model: Utilize SageMaker JumpStart to deploy the Llama model you plan to integrate. It is recommended to start with the 2B model due to the higher monthly cost for running the 70B model.
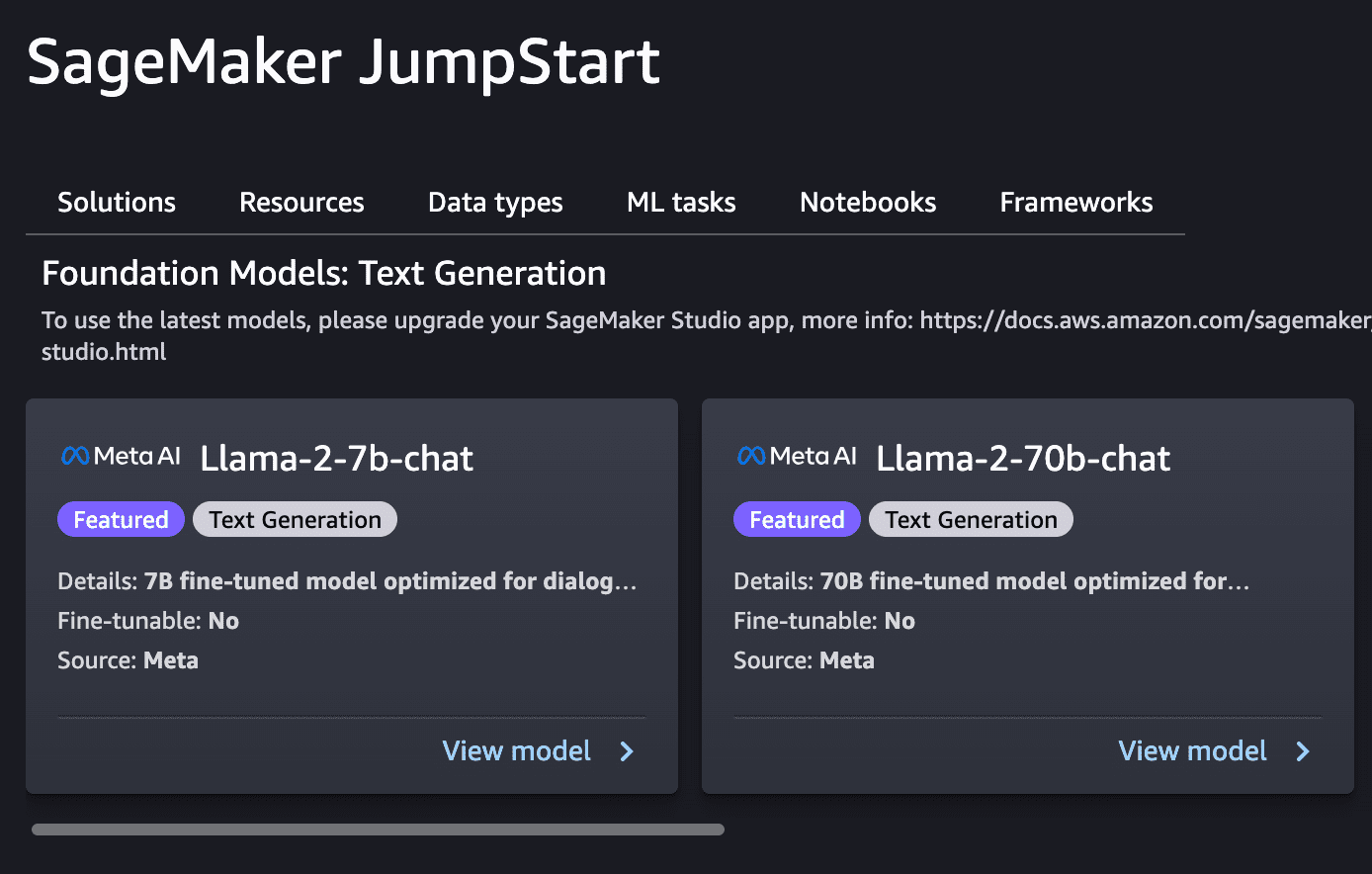
aws account-sagemaker jump start
4- Copy the Endpoint Name: Once you have a model deployed, make sure to note the endpoint name, which is crucial for future steps.
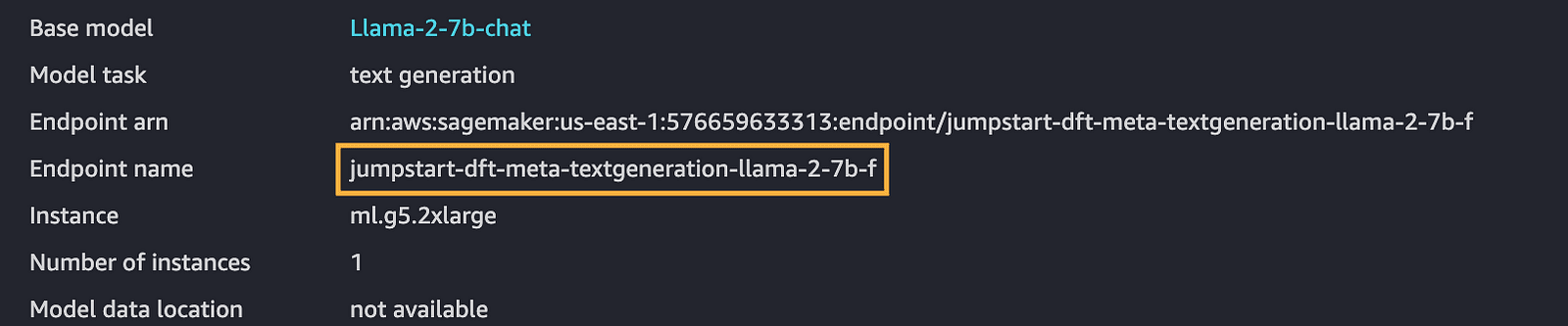
aws account-sagemaker endpoint
5- Create Lambda Function: AWS Lambda allows running the back-end code without managing servers. Create a Node.js lambda function to use for integrating the deployed model.
6- Set Up Environment Variable: Create an environment variable inside your lambda named llama_endpoint with the value of the SageMaker endpoint.
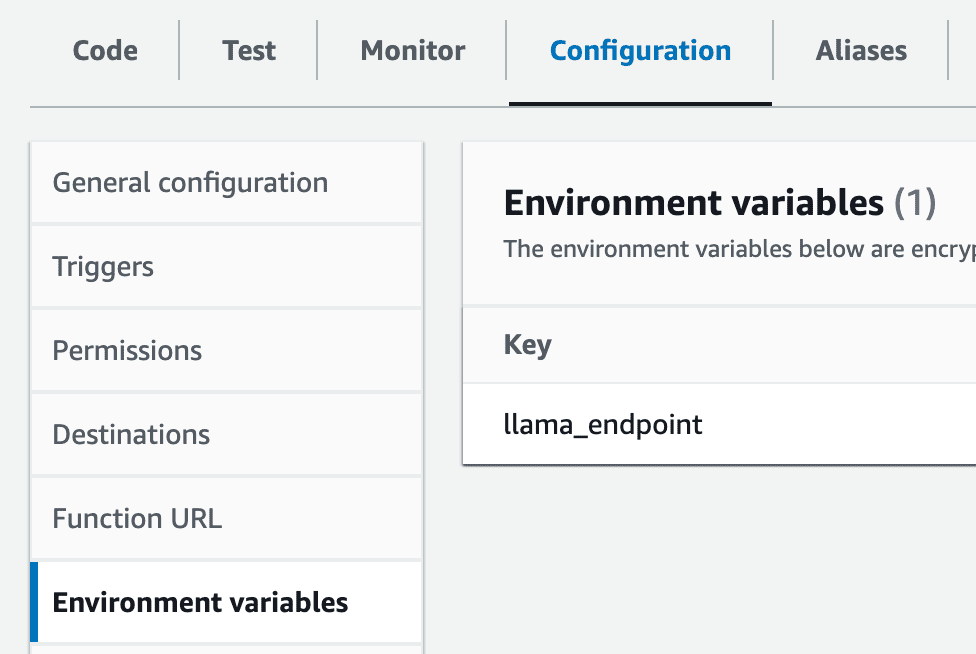
aws account-lmabda settings
7- Intellinode Lambda Import: You need to import the prepared Lambda zip file that establishes a connection to your SageMaker Llama deployment. This export is a zip file, and it can be found in the lambda_llama_sagemaker directory.
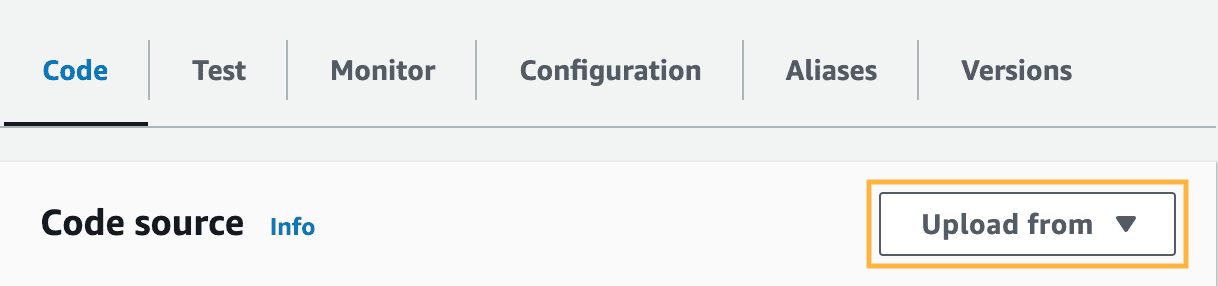
aws account-lambda upload from zip file
8- API Gateway Configuration: Click on the “Add trigger” option on the Lambda function page, and select “API Gateway” from the list of available triggers.
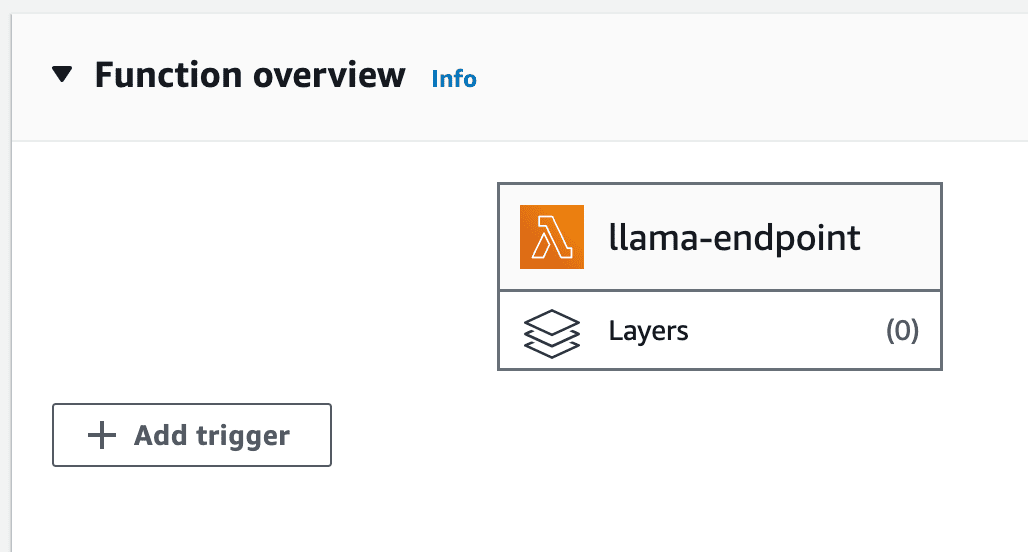
aws account-lambda trigger
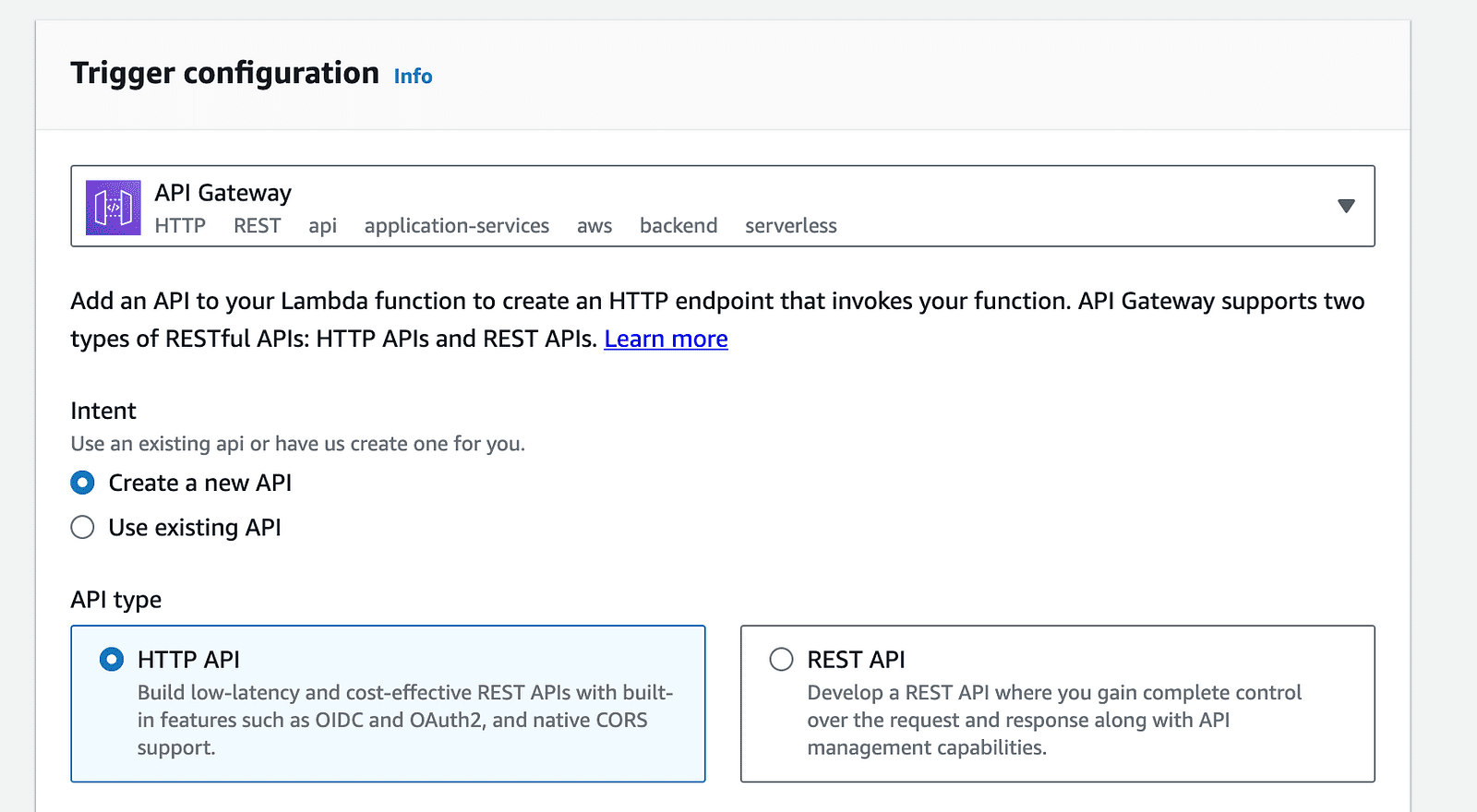
aws account-api gateway trigger
9- Lambda Function Settings: Update the lambda role to grant necessary permissions to access SageMaker endpoints. Additionally, the function’s timeout period should be extended to accommodate the processing time. Make these adjustments in the “Configuration” tab of your Lambda function.
Click on the role name to update the permissions and povides the permission to access sagemaker:
aws account-lambda role
ChatGPT Integration
Finally, we’ll illustrate the steps to integrate Openai ChatGPT as another option in the micro service architecture:
Code by Author
Get your trial key from platform.openai.com.
Execution Experiment
First export the API key in your terminal as follow:
Code by Author
Then run the node app:
node app.js
Type the following url in the browser to test chatGPT service:
http://localhost:3000/chatgpt?message=hello
We built a microservice empowered by the capabilities of Large Language Models such as Llama V2 and OpenAI’s ChatGPT. This integration opens the door for leveraging endless business scenarios powered by advanced AI.
By translating your machine learning requirements into decoupled microservices, your application can gain the benefits of flexibility, and scalability. Instead of configuring your operations to suit the constraints of a monolithic model, the language models function can now be individually managed and developed; this promises better efficiency and easier troubleshooting and upgrade management.
References
- ChatGPT API: link.
- Replica API: link.
- SageMaker Llama Jump Start: link
- IntelliNode Get Started: link
- Full code GitHub repo: link
Ahmad Albarqawi is a Engineer and data science master at Illinois Urbana-Champaign.