oBERT: Compound Sparsification Delivers Faster Accurate Models for NLP
Discover "compound sparsification" and how to apply it to BERT models for 10x compression and GPU-level latency on commodity CPUs.
Comparison of reported inference performance speedups for The Optimal BERT Surgeon (oBERT) with other methods on the SQuAD dataset. oBERT performance was measured using the DeepSparse Engine on a c5.12xlarge AWS instance.
The modern world is made up of constant communication happening through text. Think messaging apps, social networks, documentation and collaboration tools, or books. This communication generates enormous amounts of actionable data for companies that wish to use it to improve their users’ experiences. For example, the video at the bottom of this blog shows how a user can track the general sentiment of cryptocurrency across Twitter using an NLP neural network – BERT. Through many novel contributions, BERT significantly improved the state-of-the-art for NLP tasks such as text classification, token classification, and question answering. It did this in a very “over-parameterized” way, though. Its 500MB model size and slow inference prohibit many efficient deployment scenarios, especially at the edge. And cloud deployments become fairly expensive, fairly quickly.
BERT’s inefficient nature has not gone unnoticed. Many researchers have pursued ways to reduce its cost and size. Some of the most active research is in model compression techniques such as smaller architectures (structured pruning), distillation, quantization, and unstructured pruning. A few of the more impactful papers include:
- DistilBERT used knowledge distillation to transfer knowledge from a BERT base model to a 6-layer version.
- TinyBERT implemented a more complicated distillation setup to better transfer the knowledge from the baseline model into a 4-layer version.
- The Lottery Ticket Hypothesis applied magnitude pruning during pre-training of a BERT model to create a sparse architecture that generalized well across fine-tuning tasks.
- Movement Pruning applied a combination of the magnitude and gradient information to remove redundant parameters while fine-tuning with distillation.
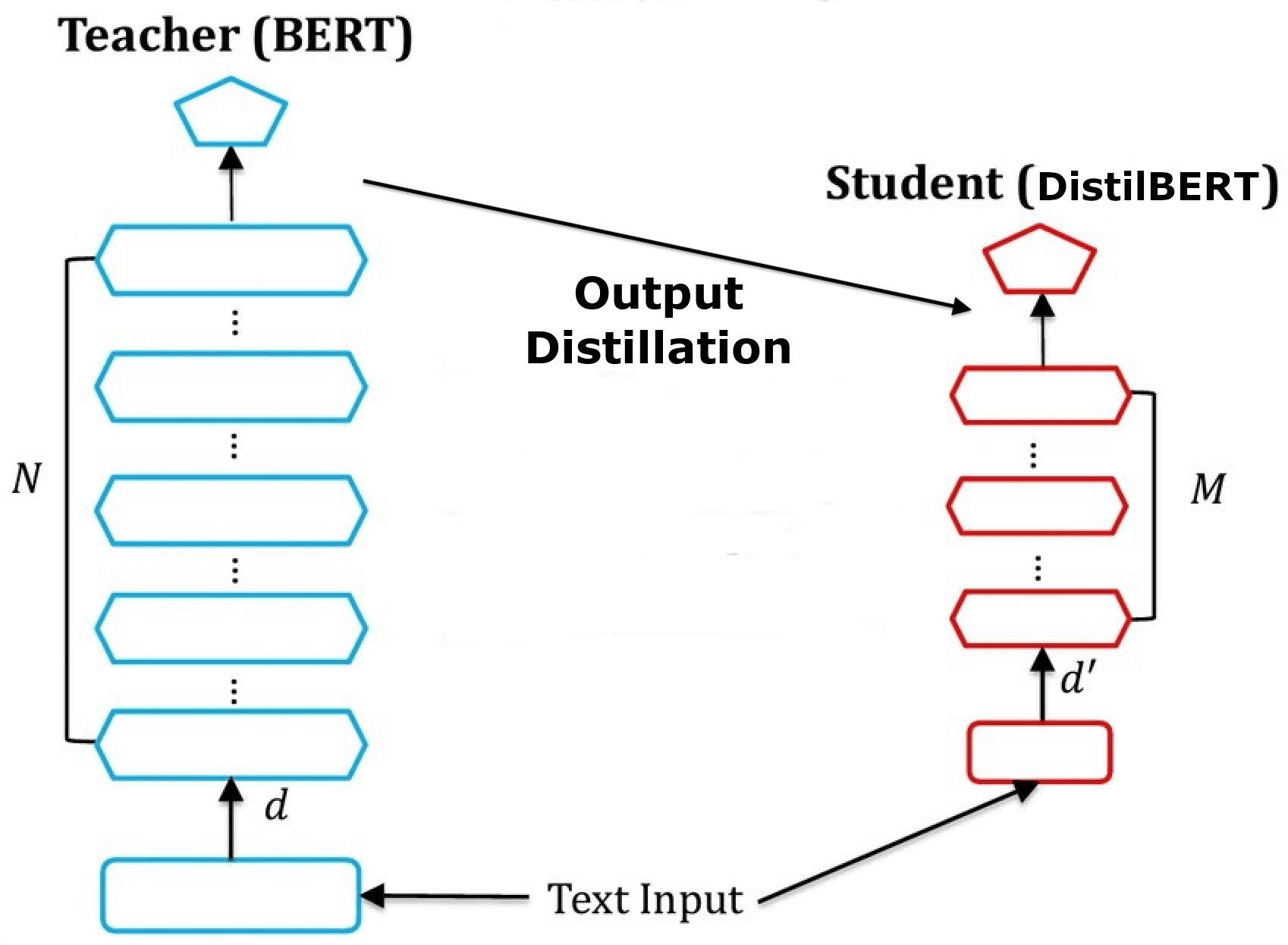
DistilBERT training illustration

TinyBERT training illustration
BERT is Highly Over-Parameterized
We show that BERT is highly over-parameterized in our recent paper, The Optimal BERT Surgeon. Ninety percent of the network can be removed with minimal effect on the model and its accuracy!
Really, 90%? Yes! Our research team at Neural Magic in collaboration with IST Austria improved the prior best 70% sparsity to 90% by implementing a second-order pruning algorithm, Optimal BERT Surgeon. The algorithm uses a Taylor expansion to approximate the effect of each weight on the loss function – all of this means we know exactly which weights are redundant in the network and are safe to remove. When combining this technique with distillation while training, we are able to get to 90% sparsity while recovering to 99% of the baseline accuracy!
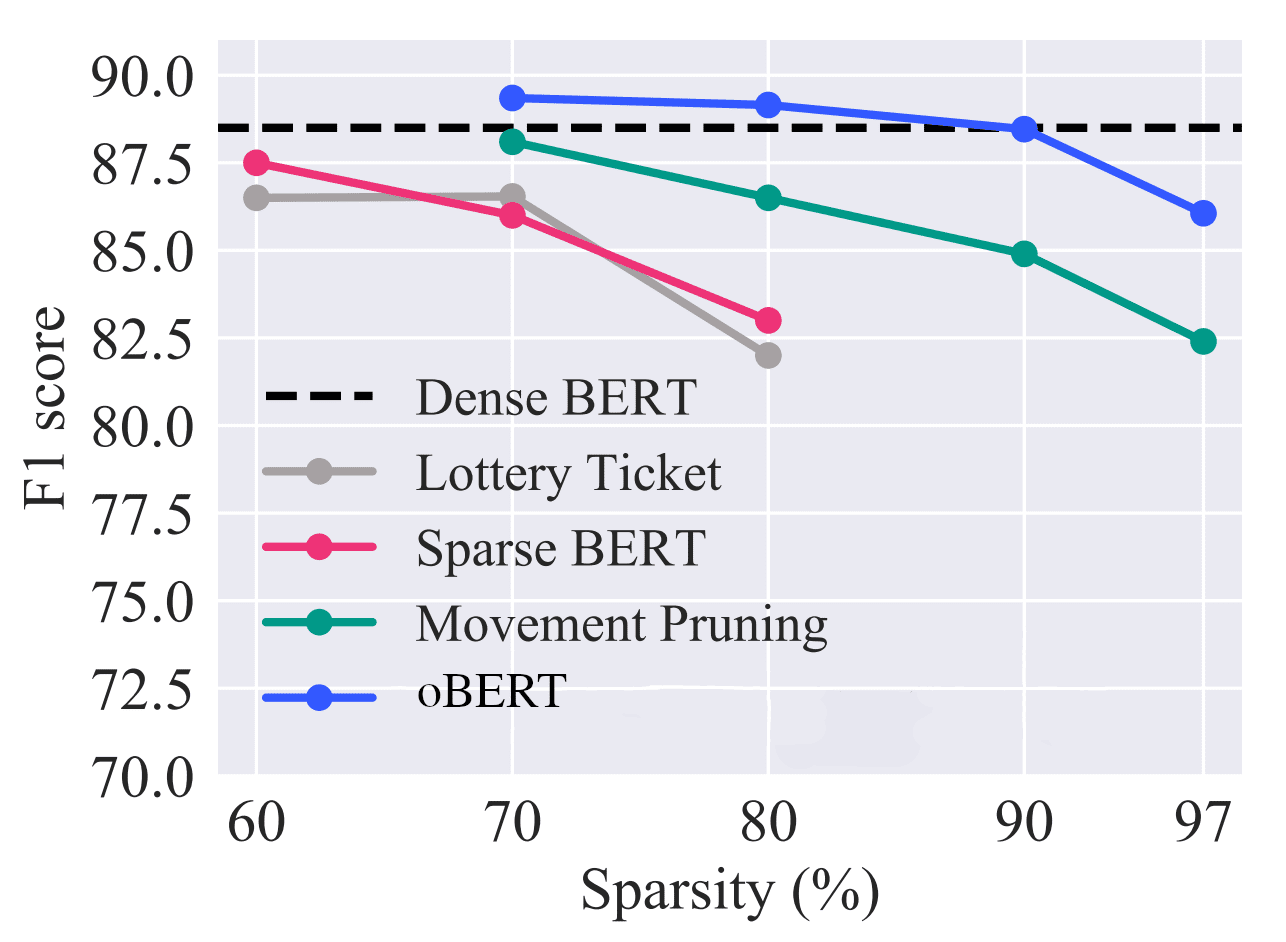
Performance overview relative to current state-of-the-art unstructured pruning methods on the 12-layer BERT-base-uncased model and the question-answering SQuAD v1.1 dataset.
But, are structured pruned versions of BERT over-parameterized as well? In trying to answer this question, we removed up to 3/4 of the layers to create our 6-layer and 3-layer sparse versions. We first retrained these compressed models with distillation and then applied Optimal BERT Surgeon pruning. In doing this, we found that 80% of the weights from these already-compressed models could be further removed without affecting the accuracy. For example, our 3-layer model removes 81 million of the 110 million parameters in BERT while recovering 95% of the accuracy, creating our Optimal BERT Surgeon models (oBERT).
Given the high level of sparsity, we introduced with oBERT models, we measured the inference performance using the DeepSparse Engine – a freely-available, sparsity-aware inference engine that’s engineered to increase the performance of sparse neural networks on commodity CPUs, like the ones in your laptop. The chart below shows the resulting speedups for a pruned 12-layer that outperforms DistilBERT and a pruned 3-layer that outperforms TinyBERT. With the combination of DeepSparse Engine and oBERT, highly accurate NLP CPU deployments are now measured in a few milliseconds (few = single digits).
Better Algorithms Enable Performant and Efficient Deep Learning, Anywhere
After applying the structured pruning and Optimal BERT Surgeon pruning techniques, we include quantization-aware training to take advantage of the DeepSparse Engine’s sparse quantization support for X86 CPUs. Combining quantization and our sparse models with 4-block pruning for DeepSparse VNNI support results in a quantized, 80% sparse 12-layer model that achieves the 99% recovery target. The combination of all these techniques is what we termed “compound sparsification.”
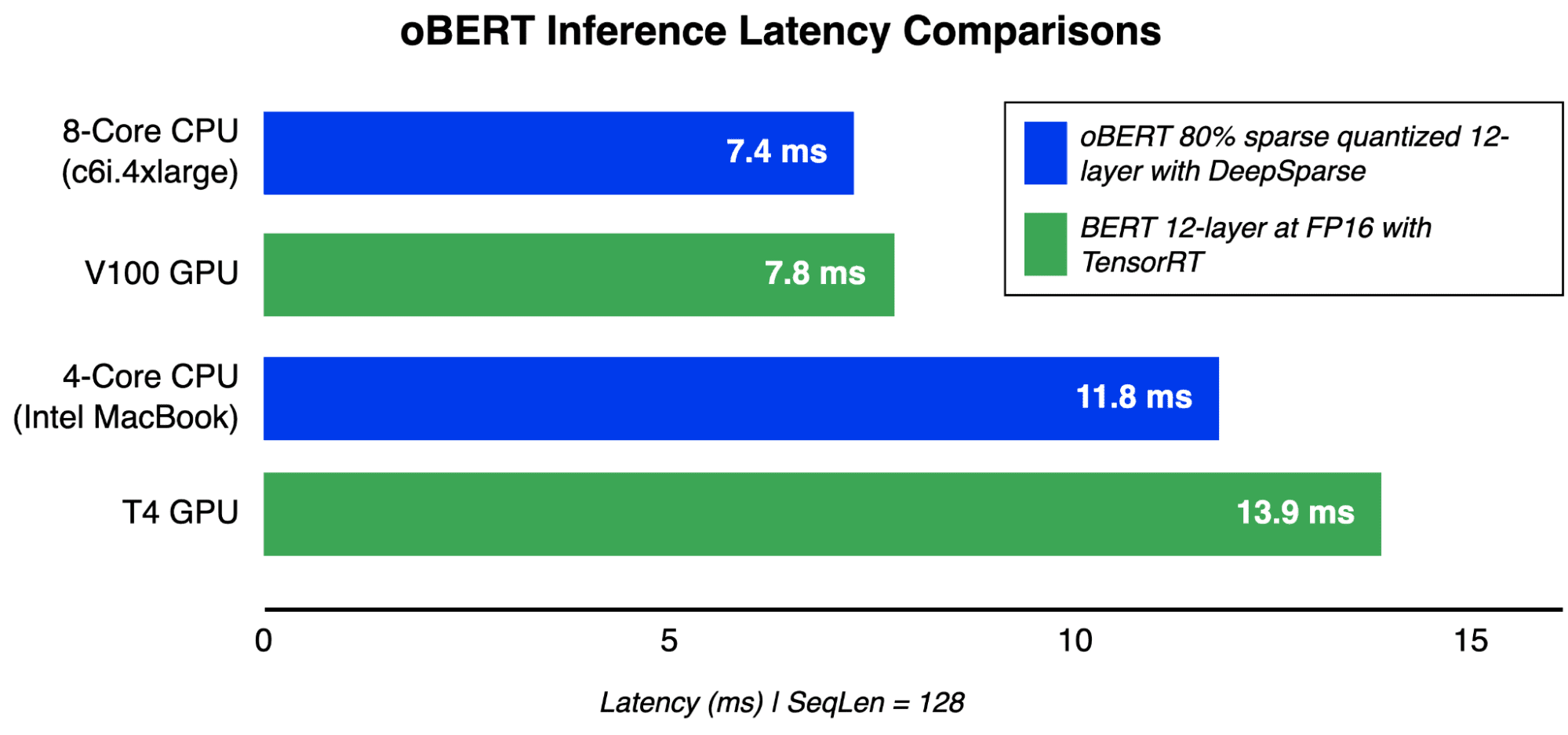
Latency inference comparisons at batch size 1, sequence length 128 for oBERT on CPUs and GPUs.
The result is GPU-level performance for BERT models on readily available CPUs. With the sparse quantized oBERT 12-layer model, a 4-core Intel MacBook is now more performant than a T4 GPU and an 8-core server outperforms a V100 for latency-sensitive applications. Even further speedups are realized when using the 3 and 6-layer models for slightly less accuracy.
“A 4-core Intel MacBook is now more performant than a T4 GPU and an 8-core server outperforms a V100 for latency-sensitive applications.”
Making Compound Sparsification Work for You
Twitter natural language processing video comparing the performance improvements from oBERT to an unoptimized, baseline model.
In spirit with the research community and enabling continued contributions, the source code for creating oBERT models is open sourced through SparseML and the models are freely available on the SparseZoo. Additionally, the DeepSparse Twitter crypto example is open sourced in the DeepSparse repo. Try it out to performantly track crypto trends, or any other trends, on your hardware! Finally, we’ve pushed up simple use-case walkthroughs to highlight the base flows needed to apply this research to your data.
Mark Kurtz (@markurtz_) is Director of Machine Learning at Neural Magic, and an experienced software and machine learning leader. Mark is proficient across the full stack for engineering and machine learning, and is passionate about model optimizations and efficient inference.