
Why Do Machine Learning Models Die In Silence?
A critical problem for companies when integrating machine learning in their business processes is not knowing why they don't perform well after a while. The reason is called concept drift. Here's an informational guide to understanding the concept well.
The meaning of life differs from man to man, from day to day, and from hour to hour.
— Viktor E. Frankle, Man’s search for meaning
Frankle was not only right about the meaning of life. His saying was correct about machine learning models in production too.
ML models perform well when you deploy them in production. Yet, their performance degrades along the way. It's quality of predictions decay and soon becomes less valuable.
This is the primary difference between a software deployment and a machine learning one. A software program performs tasks in the same way, every time. Even after decades of their creation, they stay useful unless new technologies override them or the purpose it was first created is obsoleted.
Most companies try and fail to use machine learning in their business operations without knowing this difference. They quit soon before benefiting from the values this technology could offer.
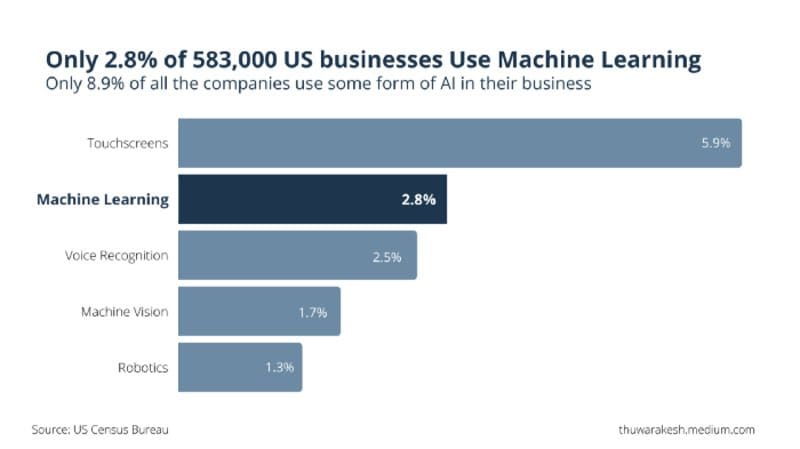
Fewer companies use machine learning and artificial intelligence to power their business operations. — Image by Author.
According to the US Census Bureau’s survey of 583,000 US companies in 2018, only 2.8% uses machine learning to leverage advantages to their operations. About 8.9% of surveyed use some form of AI such as voice recognition.
Why does an ML model performance degrade in production?
You spent weeks if not months training a machine learning model, and finally, it’s moved to production. Now, you should be seeing the benefits of your hard work.
But instead, you notice that model performance is slowly degrading over time. What could cause this?
If not monitored constantly and adequately evaluated for predictive quality degradation, concept drift can kill a machine learning model before its expected retirement date.
What is concept drift?
Concept drift occurs when there are changes in the distribution of the training set examples.
At the most basic level, concept drift causes data points that were once considered an example of one concept to be seen as another concept entirely over time.
For instance, fraud detection models are at risk for concept drift when the concept of fraud is constantly changing.
This can cause model performance to degrade, especially over extended periods where concept drift continues to occur without being detected by your monitoring systems.
What causes concept drift?
The primary reason concept drift occurs is that the underlying data distribution in an application is constantly changing.
When the distributions change, the old machine learning models can no longer make accurate predictions and must be redefined or retrained entirely to adapt to these changes.
Although this sounds like something you would never want happening in an application, it is the goal of many machine learning models to be updated as frequently as possible.
This is because new data collected from a production environment contains valuable information that can help improve the accuracy of predictions made by your model.
The distribution of input data could change either because of external reasons or due to the predictions themselves. Customer purchasing behavior, for example, is influenced by macroeconomic trends. Yet, their behavior on your platform is also can be a direct consequence of your recommendation system.
How to address concept drift for models in production?
Although concept drift looks pretty intimidating, there are ways to address it. It is a prevalent problem that all machine learning developers face sooner or later.
The concept drifts over time, and the data changes from what was used for training your model. If you don’t have a way of monitoring this drift, your accuracy will slowly degrade until eventually, no one trusts your predictions anymore.
Monitor the inputs and outputs of the model over time.
By monitoring the input and output data distribution, we could identify if the performance leakage is a data issue or a model issue.
If it’s a data issue, then you can look into what changes are causing this shift. It may be the data collection method or a genuine shift in the trend.
If it’s a model issue, you should look at what feature of your model may be causing this change in distribution. This can be caused by things like bias creeping into the model or even environmental changes that cause the training set to not match up with actual data.
Track model prediction quality over time
Monitoring different performance metrics over time is crucial because we can find out about any drift by looking at them closely. Some of the critical model performance matrics include precision, recall, F-measure, and ROC.
Precision is how accurate the prediction is when true positives are divided by all predictions made. If you look at precision over time, this indicates how much our model has drifted from actual data distribution to what it predicts now.
Recall tells us whether we are catching enough of the positive examples.
If the recall drops over time, this indicates that our model has drifted away from true positives to false negatives, which are not suitable for business decisions.
F-measure combines precision and recall into a single number using the harmonic mean of their values. If F-measure is changing along with accuracy, then this also indicates a model drift.
ROC gives us the ability to look at one true positive against all other predictions made, which helps identify any classifier bias problems or changes in features causing false positives. It can be seen as an extension of precision and recall, but it has more information.
Regularly retrain your models using new data to maintain accuracy
While tracking performance matrics allows identifying concept drifts as early as possible, regular retraining proactively tries to eliminate such a situation.
It may take a lot of time and resources to retrain your models constantly, but it is an investment that pays off in the long run.
The frequency of retraining largely depends on the domain. In e-commerce, retraining models every week probably makes sense. But for fraud detection systems where the behavior of fraudulent users is constantly changing, you may need to retrain your model daily.
Use an ensemble of models
These are all excellent strategies for preventing or addressing machine learning drift in production. However, another way to address this problem is by using ensemble models.
Ensemble models use multiple algorithms simultaneously and combine their predictions into one final prediction that can be more accurate than any individual algorithm.
This can be a great way to increase accuracy and prevent any drift from occurring over time.
Final thoughts
Concept drifts cause machine learning models in production to perform differently than they do during training. This is a big problem that can lead to bad user experiences or even cause models to fail if the drift is not anticipated correctly.
The most common way concept drifts occur in production is when your data changes over time (e.g., new features are added, some existing ones removed). It’s essential to monitor your data and detect drift as soon as possible.
You should also use techniques like regular retraining or ensembling to prevent drift in the first place.
You must address machine learning drift before users start reporting bad experiences with your product. If this happens, it will quickly lead to a loss of trust and very high costs for fixing things later. Be proactive!
Thuwarakesh Murallie (@Thuwarakesh) is a Data Scientist at Stax, Inc., and a top writer on Medium for Analytics. Murallie shares what he explores in data science every day.