24 SQL Questions You Might See on Your Next Interview
Preparing for the SQL job interview can be overwhelming enough. You don’t need someone telling you that you need to know everything on top of that! Be smart and focus on preparing the SQL questions that appear most often at the job interview.

When talking about the SQL interview questions that come up most often at job interviews, I’m not talking about giving you the specific question. That would be an impossible task because there are thousands and thousands of them.
Luckily, there are not so many SQL concepts tested by these questions. It doesn’t mean you should solve only the interview questions I’m about to show or know only the selected topics.
But if you focus on the most common topics, the chance is you’ll be covering most of the concepts tested in the interviews. Of course, the questions can be of different difficulty, which will require more or less knowledge about a specific topic. Still, the concepts are often the same.
While these topics can be seen as magnificent (especially if you’re an SQL nerd!), I prefer to call them “The Unavoidable Seven”:
- Aggregating, Grouping, and Sorting
- Filtering
- JOINs & Set Operators
- Subqueries & CTEs
- CASE Statement
- Window Functions
- Text & Date Manipulation
These topics are usually tested in the coding SQL questions, but they can also appear in the non-coding types of questions.
Coding SQL Interview Questions
The coding questions are precisely what their name suggests: they test your ability to write a code using the SQL concepts.
1. Aggregating, Grouping, and Sorting

Theory
The SQL aggregate functions are the functions that perform calculations on multiple rows and return one value. The most commonly used aggregate functions are:
| Aggregate Function | Description |
| COUNT() | Counts the number of rows. |
| SUM() | Returns the sum of the rows. |
| AVG() | Calculates the average of the rows’ values. |
| MIN() | Returns the lowest value. |
| MAX() | Returns the highest value. |
When used alone, these functions will return only one value. Admittedly, this isn’t very sophisticated.
The aggregate functions become more valuable for data scientists when used with the GROUP BY and ORDER BY clauses.
GROUP BY is used for grouping data from one or more columns into groups based on the rows’ values. Every different value (or a combination of values for grouping by multiple columns) will form a separate data group. That way, it becomes possible to show additional info on data that is being aggregated.
The ORDER BY serves for sorting the query’s output. Data can be sorted in ascending or descending order. Also, you can sort by one or more columns.
Aggregate functions used with these two clauses become a stepping stone for creating reports, calculating metrics, and tidying data. They allow you to perform mathematical operations on data and show your finding in a clear and presentable way.
SQL Questions
SQL Interview Question #1: Finding Updated Records
“We have a table with employees and their salaries, however, some of the records are old and contain outdated salary information. Find the current salary of each employee, assuming that salaries increase each year. Output their id, first name, last name, department ID, and current salary. Order your list by employee ID in ascending order.”
Link to the question: https://platform.stratascratch.com/coding/10299-finding-updated-records?code_type=1
Data
This question gives you one table: ms_employee_salary
| id | int |
| first_name | varchar |
| last_name | varchar |
| salary | varchar |
| department_id | int |
The sample of the data from the table is given below.
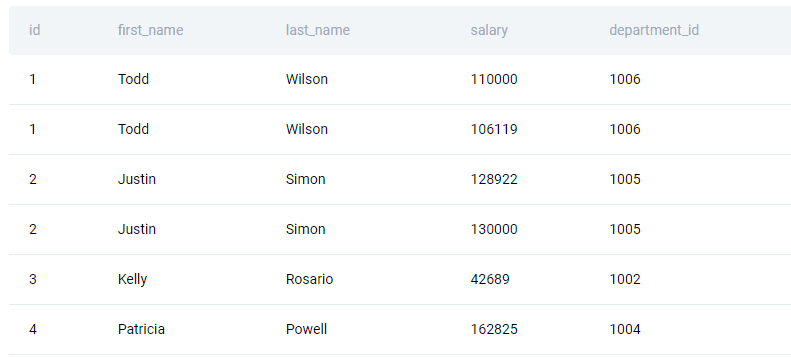
Solution Approach
If the salary is increasing every year, then the latest salary is also the highest salary. To fetch it, use the MAX() aggregate function. Group the data by the employee and department. You should also show the output sorted by the employee ID in ascending order; use the ORDER BY clause for that.
SELECT id, first_name, last_name, department_id, max(salary) FROM ms_employee_salary GROUP BY id, first_name, last_name, department_id ORDER BY id ASC;
Output
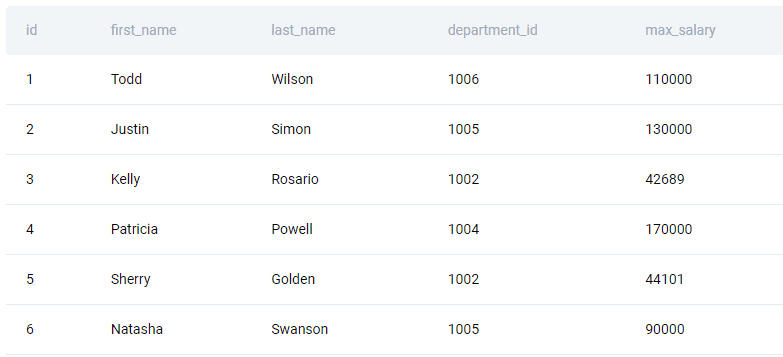
SQL Interview Question #2: Order All Countries by the Year They First Participated in the Olympics
“Find the average distance traveled in each hour.
Output the hour along with the corresponding average traveled distance.
Sort records by the hour in ascending order.”
Link to the question: https://platform.stratascratch.com/coding/10006-find-the-average-distance-traveled-in-each-hour?code_type=1
To find the average distance, use the AVG() function, then group and order the output by the column hour.
If you write the correct solution, this is what you’ll get.
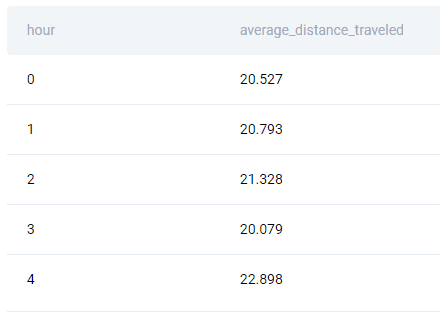
SQL Interview Question #3: Order All Countries by the Year They First Participated in the Olympics
“Order all countries by the year they first participated in the Olympics.
Output the National Olympics Committee (NOC) name along with the desired year.
Sort records by the year and the NOC in ascending order.”
Link to the question: https://platform.stratascratch.com/coding/10184-order-all-countries-by-the-year-they-first-participated-in-the-olympics?code_type=1
The code needs to group data by the column noc and uses the MIN() aggregate function for finding the first year of participation. To sort the output adequately, use the ORDER BY.
If you get this result, then you did everything right.

2. Filtering

Theory
If data filtering is defined as selecting a subset of data, then there are many ways of data filtering. Even the ones people usually don’t see as such, for example, the SELECT statement and JOINs. But they are; they select only part of the data.
When thinking about filtering data, usually two keywords come to mind (or three when you’re using PostgreSQL:
- WHERE
- HAVING
- (LIMIT)
The WHERE clause’s purpose is to filter data before it is aggregated. The syntax reflects that in a way that it must be written before the GROUP BY clause.
When filtering data using the WHERE clause, there are many operators to be used.
| Operator | Description |
| = | Is equal |
| < | Is less than |
| > | Is greater than |
| <= | Is less than or equal |
| >= | Is greater than or equal |
| <> | Does not equal |
| BETWEEN | Between the specified range |
| LIKE | Looking for a pattern |
| IN | Equals the values listed in the parentheses |
The HAVING clause does the same thing as the WHERE clause, except it filters data after the aggregation. Naturally, it can be used only after the GROUP BY clause in the SQL queries.
All the operators in the WHERE clause are also allowed in the HAVING clause.
Both clauses allow filtering on one or multiple conditions by using the AND/OR logical operators.
Using these two clauses adds another dimension to your calculations. Basic use makes it possible to show only the data you’re interested in and not the bulk of the data. This means not only do you get the choose the columns you want but also the rows you want, based on their values. Use it with the aggregate function, and you get to perform calculations on even more detailed subsets of data by filtering the input for the aggregate functions and, if you wish, their output, too. This increases the complexity of the calculations at your disposal.
Here are the examples of how WHERE and HAVING work.
The LIMIT clause simply specifies the number of rows you wish to see as output. The integer value in the clause equals the number of rows shown as a result. This is especially useful when you want to rank data, e.g., show the top N sales, employees, salaries, etc.
SQL Questions
SQL Interview Question #4: Find the Year That Uber Acquired More Than 2000 Customers Through Celebrities
“Find the year that Uber acquired more than 2000 customers through advertising using celebrities.”
Link to the question: https://platform.stratascratch.com/coding/10000-find-the-year-that-uber-acquired-more-than-2000-customers-through-celebrities?code_type=1
Data
The table uber_advertising has four columns.
| year | int |
| advertising_channel | varchar |
| money_spent | int |
| customers_acquired | int |
Here’s the table preview.
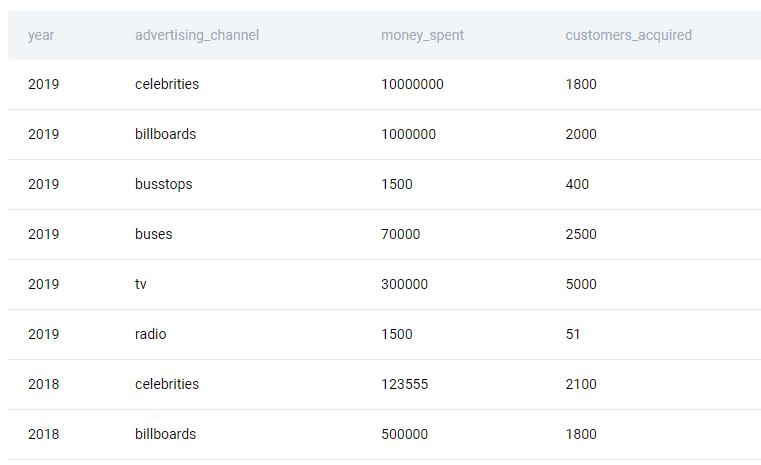
Solution Approach
The solution is a simple SELECT statement with one column. However, you don’t need all the years. The question asks you to output only those where the advertising channel was through celebrities, and there were more than 2,000 customers acquired. To do that, put these two conditions into the WHERE clause.
SELECT year FROM uber_advertising WHERE advertising_channel = 'celebrities' AND customers_acquired > 2000;
Output

Run the code, and it will output only one year that satisfies the criteria: 2018.
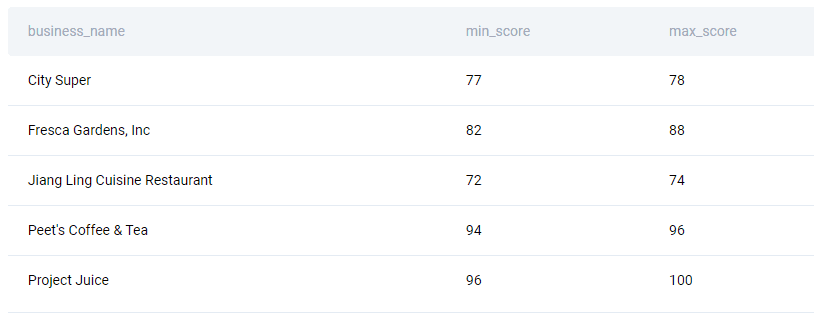
SQL Interview Question #5: Find All Businesses Whose Lowest and Highest Inspection Scores Are Different
“Find all businesses whose lowest and highest inspection scores are different.
Output the corresponding business name and the lowest and highest scores of each business.
Order the result based on the business name in ascending order.”
Link to the question: https://platform.stratascratch.com/coding/9731-find-all-businesses-whose-lowest-and-highest-inspection-scores-are-different?code_type=1
To answer the question, use the MIN() and MAX() functions to find the highest and lowest inspection scores and group the data by business. Then use the HAVING clause to show only businesses whose highest and lowest scores are not equal. Finally, sort the output by the business name alphabetically.
Your output should be this one.
SQL Interview Question #6: Find the Top 3 Jobs With the Highest Overtime Pay Rate
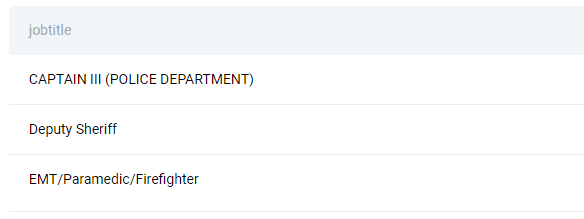
“Find the top 3 jobs with the highest overtime pay rate.
Output the job title of selected records.
Sort records based on the overtime pay in descending order.”
Link to the question: https://platform.stratascratch.com/coding/9988-find-the-top-3-jobs-with-the-highest-overtime-pay-rate?code_type=1
This question asks you to use both WHERE and LIMIT clause. Use WHERE to find the job titles whose overtime pay isn’t NULL and isn’t 0. Order the data from the highest to the lowest overtime pay. Then, simply limit the output to the first three rows, and there you have it: the top 3 jobs with the highest overtime pay rate.
As the output shows, there are only three such jobs.
3. JOINs & Set Operators
Theory
So far, you’ve been condemned to use only one table. Unfortunately, not one respectable database is comprised of only one table. To fully use the available data, you need to know how to combine data from two or more tables.
JOINs are the SQL feature you’re looking for: it makes it possible to join tables on the common column.
There are five distinct JOIN types in SQL.
| JOIN Type | Description |
| (INNER) JOIN | Returns only the matching rows from both tables. |
| LEFT (OUTER) JOIN | Returns all the data from the left table and only the matching rows from the right. |
| RIGHT (OUTER) JOIN | Returns all the data from the right table and only the matching rows from the left. |
| FULL OUTER JOIN | Returns all the rows from both tables. |
| CROSS JOIN | Combines all the rows from one table with every from the second table. |
When I mention the matching rows, I mean the rows or values that are the same in both tables.
The first four joins are used most often, but CROSS JOIN can also be used sometimes.
One additional way of joining tables is a self-join. It isn’t a distinct type of join: any JOIN type can be used for self-joining, which simply means that you join the table with itself.
The set operators are used to combine the output of two or more queries.
| Set Operator | Description |
| UNION | Combines the unique rows resulting from the queries. |
| UNION ALL | Combines all the rows resulting from the queries, including the duplicates. |
| INTERSECT | Returns only the rows that appear in both queries’ output. |
| EXCEPT | Returns unique rows from one query and only those that appear in the second query’s output. |
SQL Questions
SQL Interview Question #7: Expensive Projects
“Given a list of projects and employees mapped to each project, calculate by the amount of project budget allocated to each employee. The output should include the project title and the project budget per employee rounded to the closest integer. Order your list by projects with the highest budget per employee first.”
Link to the question: https://platform.stratascratch.com/coding/10301-expensive-projects?code_type=1
Data
The question gives you two tables.
Table: ms_projects
| id | int |
| title | varchar |
| budget | int |
Here’s the table preview.

Table: ms_emp_projects
| emp_id | int |
| project_id | int |
The data example is given below.

Solution Approach
The first thing to do is to calculate the project budget by the employee. This looks more complicated than it is: simply divide the column budget with the number of employees, which you get using the COUNT() function. Then, cast the result to a float data type to get the decimal places. This calculation is done inside the ROUND() functions used to round the numbers. In this case, the result of division is cast to the numeric data type and rounded with no decimal places.
The SELECT statement uses the columns from both tables. This is possible because the tables are joined using the INNER JOIN in the FROM clause. They are joined where the column id equals the column project_id.
In the end, the result is grouped by the project and its budget, while the output is sorted by the ratio in descending order.
SELECT title AS project, ROUND((budget/COUNT(emp_id)::float)::numeric, 0) budget_emp_ratio FROM ms_projects a INNER JOIN ms_emp_projects b ON a.id = b.project_id GROUP BY title, budget ORDER BY budget_emp_ratio DESC;
Output
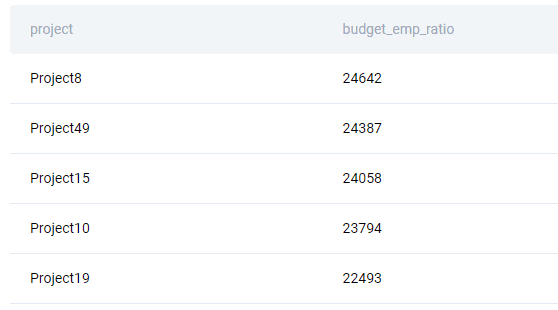
The code output should look like this, shown partially below.
SQL Interview Question #8: Find How Many Logins Spanish Speakers Made by Country
“Find how many logins Spanish speakers made by the country.
Output the country along with the corresponding number of logins.
Order records by the number of logins in descending order.”
Link to the question: https://platform.stratascratch.com/coding/9889-find-how-many-logins-spanish-speakers-made-by-country?code_type=1
In the solution, use the COUNT() function to calculate the number of logins. Since the required data is found in two tables, joining them would be necessary. Use the INNER JOIN for that purpose. Join the tables on the column user_id and where the event is ‘login’, while the user’s language is ‘spanish’. Group data by the location and sort it from the highest to the lowest count of logins.
The correct code will return three countries with the following number of logins.

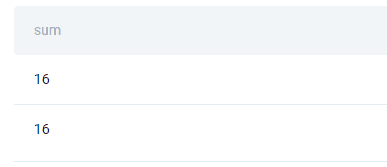
SQL Interview Question #9: Sum Of Numbers
“Find the sum of numbers whose index is less than 5 and the sum of numbers whose index is greater than 5. Output each result on a separate row.”
Link to the question: https://platform.stratascratch.com/coding/10008-sum-of-numbers?code_type=1
The code you’ll have to write consists of two SELECT statements. One will find the sum of numbers where the index is less than 5, the other will do the same for the indexes higher than 5.
All you have to do is put UNION ALL between these two statements to get the output.
4. Subqueries & CTEs

Theory
The subqueries and CTEs add flexibility to your code. They are both used for more complex calculations with several steps, and their result is used in the main calculation.
There are specific keywords where you can use the subqueries.
- SELECT
- FROM
- WHERE
- HAVING
- INSERT
- UPDATE
- DELETE
They are most often used for filtering data in the WHERE or HAVING clause but also as tables in the FROM clause when the query result acts as a table. Generally, they allow performing complex calculations within one query.
As for the CTEs or Common Table Expressions, they have the same purpose. The difference is that they are closer to the human logic of calculation steps, so they make a tidier code. Usually, a CTE requires writing less code, and it’s more readable than the same calculation written in subqueries.
There are two main parts of a CTE: a CTE and a query referencing the CTE.
The general CTE syntax is:
WITH cte_name AS ( SELECT…cte_definition.. ) SELECT … FROM cte_name;
The CTE is called using the WITH keyword. After giving your CTE, a name comes AS and then a CTE definition in the parentheses. This definition is a SELECT statement that gives instructions to CTE.
The main query is again a SELECT statement, but this one references the CTE.
There’s a reason they have a word table in the name: a CTE is a temporary result that can be accessed only when a CTE is run, so it is similar to a temporary table. That’s why you can use it in the FROM clause like any other table.
SQL Questions
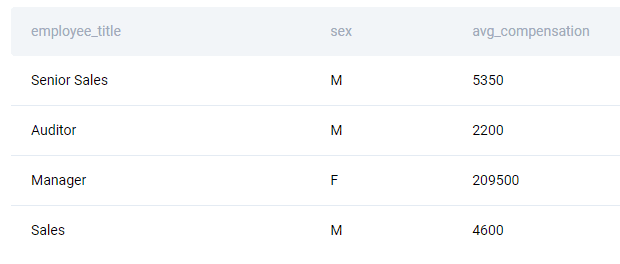
SQL Interview Question #10: Income By Title and Gender
“Find the average total compensation based on employee titles and gender. Total compensation is calculated by adding both the salary and bonus of each employee. However, not every employee receives a bonus, so disregard employees without bonuses in your calculation. An employee can receive more than one bonus.
Output the employee title, gender (i.e., sex), along with the average total compensation.”
Link to the question: https://platform.stratascratch.com/coding/10077-income-by-title-and-gender?code_type=1
Data
The first table used in the question is sf_employee.
Table: sf_employee
| id | int |
| first_name | varchar |
| last_name | varchar |
| age | int |
| sex | varchar |
| employee_title | varchar |
| department | varchar |
| salary | int |
| target | int |
| varchar | |
| city | varchar |
| address | varchar |
| manager_id | int |
The data in the table looks like this.

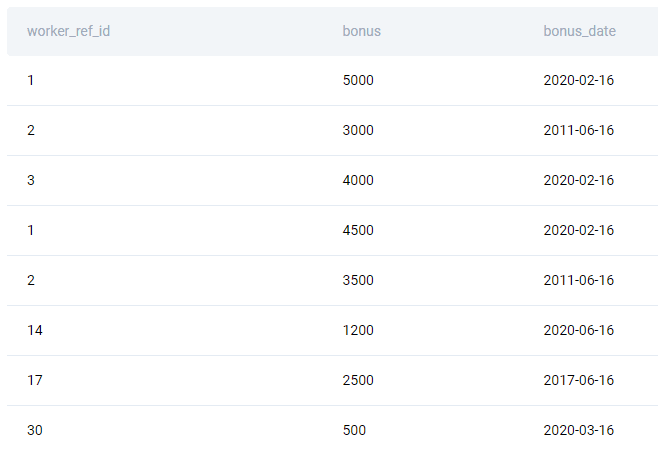
Table: sf_bonus
| worker_ref_id | int |
| bonus | int |
| bonus_date | datetime |
Here’s the data.
Solution Approach
The main SELECT statement in this code uses the table sf_employee and subquery data. The subquery calculates the total bonuses for the employee using the SUM() function; that’s why it also groups data by the worker ID. The subquery is joined with the table sf_employee like any other table. In this case, it’s using the INNER JOIN.
The main query will then use the subquery’s data to calculate the average total compensation, comprised of the salary and the total bonuses received.
In the end, the result is grouped by the employee and sex.
SELECT e.employee_title, e.sex, AVG(e.salary + b.ttl_bonus) AS avg_compensation FROM sf_employee e INNER JOIN (SELECT worker_ref_id, SUM(bonus) AS ttl_bonus FROM sf_bonus GROUP BY worker_ref_id) b ON e.id = b.worker_ref_id GROUP BY employee_title, Sex;
Output
The solution will return four rows as a result.
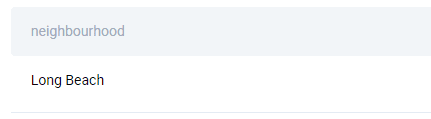
SQL Interview Question #11: Cheapest Neighborhoods With Real Beds And Internet
“Find neighborhoods where you can sleep on a real bed in a villa with internet while paying the lowest price possible.”
Link to the question: https://platform.stratascratch.com/coding/9636-cheapest-neighborhoods-with-real-beds-and-internet?code_type=1
For solving the question, use the subquery in the WHERE clause to get the price that satisfies certain criteria. The MIN() function will be used to find the lowest price for a real bed in a villa with the internet. Use the equals sign for two conditions and ILIKE with the wild card character (%) on both sides of the condition.
Then the same criteria (real bed, villa, the internet) will be used in the main query.
There’s one neighborhood that satisfies the criteria.
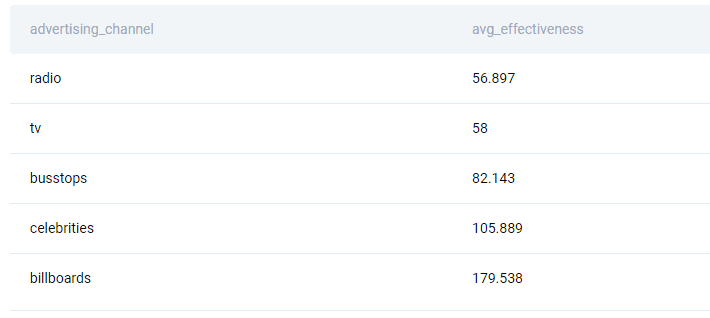
SQL Interview Question #12: Advertising Channel Effectiveness
“Find the average effectiveness of each advertising channel in the period from 2017 to 2018 (both included). The effectiveness is calculated as the ratio of total money spent to total customers acquired.
Output the advertising channel along with corresponding average effectiveness. Sort records by the average effectiveness in ascending order.”
Link to the question: https://platform.stratascratch.com/coding/10012-advertising-channel-effectiveness?code_type=1
Every CTE starts with the keyword WITH, after which follows the name of the CTE. This is then followed by AS, and in the parentheses, you define the body of CTE, i.e., the SELECT statement, which you’ll call on in the outer query.
You should use the CTE in this example to sum the money spent and the acquired customers. You do all that for the years 2017 and 2018 by setting this condition in the WHERE clause.
In the outer query, select the advertising channel and then divide the total money spent with the total number of customers acquired, which will give you the average effectiveness.
Sort the output by the effectiveness in ascending order.
5. CASE Statement

Theory
This is a conditional statement, an SQL version of an IF-THEN-ELSE logic. It instructs the code to go through a set of conditions that define which result should be returned depending on whether the data satisfies the condition or not.
The CASE statement’s syntax is:
CASE WHEN condition THEN result ELSE result END AS case_stetement_alias;
It also allows setting the multiple conditions, not only one.
The case statement is most commonly used when labeling data or with aggregate functions when the calculations are performed based on specific criteria.
SQL Questions
SQL Interview Question #13: Bookings vs. Non-Bookings
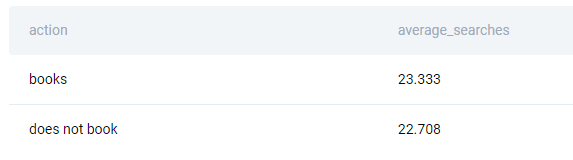
“Display the average number of times a user performed a search which led to a successful booking and the average number of times a user performed a search but did not lead to a booking. The output should have a column named action with values 'does not book' and 'books' as well as a 2nd column named average_searches with the average number of searches per action. Consider that the booking did not happen if the booking date is null. Be aware that search is connected to the booking only if their check-in dates match.”
Link to the question: https://platform.stratascratch.com/coding/10124-bookings-vs-non-bookings?code_type=1
Data
You’ll have to use both tables the question provides.
Table: airbnb_contacts
| id_guest | varchar |
| id_host | varchar |
| id_listing | varchar |
| ts_contact_at | datetime |
| ts_reply_at | datetime |
| ts_accepted_at | datetime |
| ts_booking_at | datetime |
| ds_checkin | datetime |
| ds_checkout | datetime |
| n_guests | int |
| n_messages | int |
Here’s the data preview.
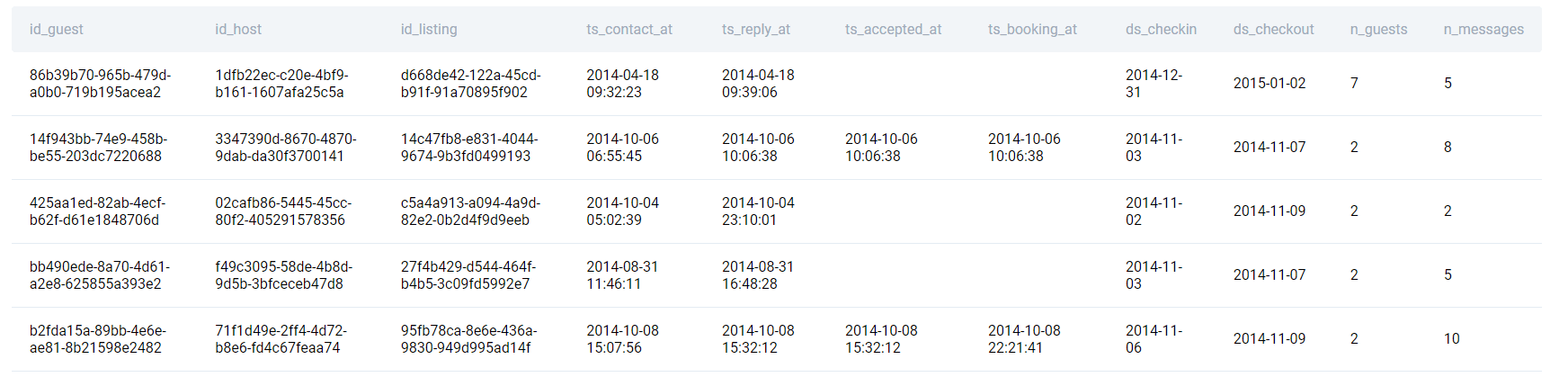
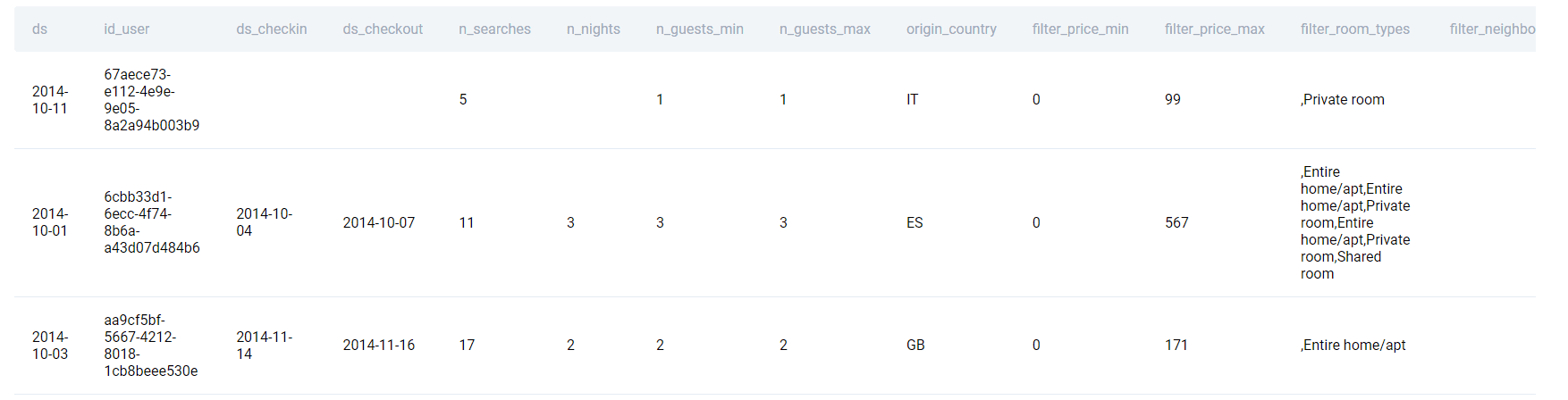
Table: airbnb_searches
| ds | datetime |
| id_user | varchar |
| ds_checkin | datetime |
| ds_checkout | datetime |
| n_searches | int |
| n_nights | float |
| n_guests_min | int |
| n_guests_max | int |
| origin_country | varchar |
| filter_price_min | float |
| filter_price_max | float |
| filter_room_types | varchar |
| filter_neighborhoods | datetime |
The first few rows from the table are shown below.
Solution Approach
The solution uses the CASE statement in the SELECT statement to label data. When there is no-NULL value in the column ts_booking_at, it will get the label “books”. If it is NULL, it will become “does not book”. This CASE statement will show its results in the new column action.
Also, there is an AVG() function in the SELECT statement for finding the average number of searches.
Data is fetched from both tables using the LEFT JOIN. In the end, the output is grouped by the data label.
SELECT CASE WHEN c.ts_booking_at IS NOT NULL THEN 'books' ELSE 'does not book' END AS action, AVG(n_searches) AS average_searches FROM airbnb_searches s LEFT JOIN airbnb_contacts c ON s.id_user = c.id_guest AND s.ds_checkin = c.ds_checkin GROUP BY 1;
Output
The above query returns the required output.
SQL Interview Question #14: Churn Rate Of Lyft Drivers
“Find the global churn rate of Lyft drivers across all years. Output the rate as a ratio.”
Link to the question: https://platform.stratascratch.com/coding/10016-churn-rate-of-lyft-drivers?code_type=1
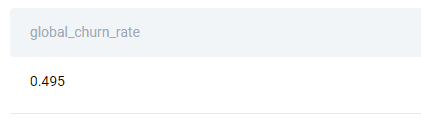
This question asks you to use the CASE statement in the aggregate function; COUNT(), to be precise. Use it to count the drivers that left, which are those whose end date is not NULL. Divide the result by the total number of drivers, and cast this into the decimal numbers.
If you do everything right, you should get the churn rate.
SQL Interview Question #15: Find the Number of Employees Who Received the Bonus and Who Didn’t
“Find the number of employees who received the bonus and who didn't.
Output an indication of whether the bonus was received or not along with the corresponding number of employees.
ex: if the bonus was received: 1, if not: 0.”
Link to the question: https://platform.stratascratch.com/coding/10081-find-the-number-of-employees-who-received-the-bonus-and-who-didnt?code_type=1
There’s a subquery in this solution. The subquery uses the CASE statement to determine the employees who did receive the bonus and who didn’t. It’s done based on the bonus date and whether the value is NULL or not. To do that, you will need to join both tables from the question using the LEFT JOIN.
The main query will use this result to count the number of employees with and without the bonus.

6. Window Functions

Theory
The SQL window functions are similar to the aggregate functions. The difference is that the window functions aggregate data in a way that makes it possible to show both individual rows and aggregated values.
Generally, there are three distinct types of window functions:
- Aggregate Window Functions
- Ranking Window Functions
- Value Window Functions
| Aggregate Window Functions | Description |
| COUNT() | Counts the number of rows. |
| SUM() | Sums the values. |
| AVG() | Returns the average value. |
| MIN() | Returns the minimum value. |
| MAX() | Returns the maximum value. |
| Ranking Window Functions | Description |
| ROW_NUMBER() | Ranks rows sequentially without skipping the row number and gives the same rank to the rows with the same values. |
| RANK() | Used for ranking, with the same values given the same ranking and the next rank being skipped. |
| DENSE_RANK() | Used for ranking, with the same values given the same ranking and the next rank not being skipped. |
| PERCENT_RANK() | Ranks the values in a percent value. |
| NTILE() | Divides rows into a number of equally sized groups. |
| Value Window Functions | Description |
| LAG() | Allows accessing data from the defined number of preceding rows. |
| LEAD() | Allows accessing data from the defined number of the following rows. |
| FIRST_VALUE() | Returns the first value from the data. |
| LAST_VALUE() | Returns the last value from the data. |
| NTH_VALUE() | Returns the value from the defined (nth) row. |
The window functions are called that for a reason. They do calculations over the rows that are related to the current row. The current row and all related rows are called a window frame.
There are five clauses important for using the window functions.
- OVER
- PARTITION BY
- ORDER BY
- ROWS
- RANGE
The OVER clause is mandatory, and its purpose is to call the window function. Without it, there are no window functions.
The PARTITION BY is used for partitioning data. By specifying the column(s) in it, you’re instructing the window function on which subset of data the calculation should be performed. When the PARTITION BY is omitted, the window function takes the whole table as a data set.
The ORDER BY clause is also an optional clause. It specifies the logical order within each data set. In other words, it’s not used for sorting the output but for setting the direction in which the window function will work. Data can be ordered in ascending or descending order.
Within the partition, you can additionally limit the rows that will be included in the window function’s calculation. This is called defining a window frame.
The ROWS clause defines a fixed number of rows preceding and following the current one.
The RANGE does the same, except not based on the number of rows but their value compared to the current row.
The window functions increase the analytical possibilities of SQL. By using them, you can show aggregated and non-aggregated data side by side, aggregate on multiple levels, rank data, and do a number of other operations that are not possible with only the aggregate functions.
SQL Questions
SQL Interview Question #16: Average Salaries
“Compare each employee's salary with the average salary of the corresponding department.
Output the department, first name, and salary of employees along with the average salary of that department.”
Link to the question: https://platform.stratascratch.com/coding/9917-average-salaries?code_type=1
Data
There’s one table named employee.
| id | int |
| first_name | varchar |
| last_name | varchar |
| age | int |
| sex | varchar |
| employee_title | varchar |
| department | varchar |
| salary | int |
| target | int |
| bonus | int |
| varchar | |
| city | varchar |
| address | varchar |
| manager_id | int |
Here’s the employee data.
Solution Approach
The query selects the department, employee’s first name, and their salary. The fourth column will calculate the AVG() salary. Since it’s a window function, it has to be called using the OVER() clause. By using department as data partition, the query will return the average salary by department instead of the overall salary.
SELECT department, first_name, salary, AVG(salary) OVER (PARTITION BY department) FROM employee;
Output
These are only the first five rows of the complete output.

SQL Interview Question #17: Ranking Most Active Guests
“Rank guests based on the number of messages they've exchanged with the hosts. Guests with the same number of messages as other guests should have the same rank. Do not skip rankings if the preceding rankings are identical.
Output the rank, guest id, and the number of total messages they've sent. Order by the highest number of total messages first.”
Link to the question: https://platform.stratascratch.com/coding/10159-ranking-most-active-guests?code_type=1
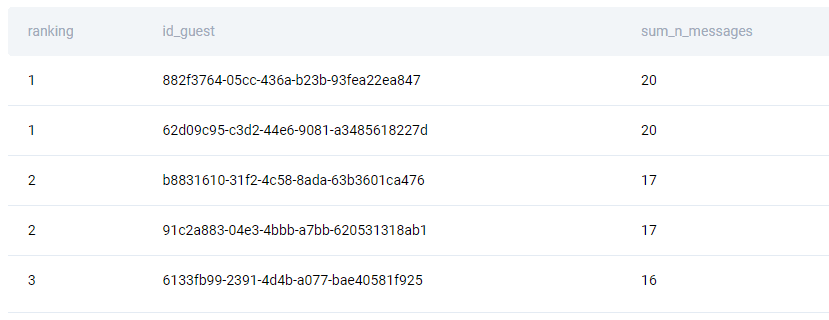
Here you need to use the ranking window function, namely the DENSE_RANK() function. There will be no data ,partitioning, but use the ORDER BY to rank the sum of the messages from the highest to the lowest. Additionally, select the guest ID and calculate the sum of messages outside the window function.
Group data by the guest ID and sort data from the highest to the lowest number of messages.
Your output should look something like this.
SQL Interview Question #18: Cum Sum Energy Consumption
“Calculate the running total (i.e., cumulative sum) energy consumption of the Meta/Facebook data centers in all 3 continents by the date. Output the date, running total energy consumption, and running total percentage rounded to the nearest whole number.”
Link to the question: https://platform.stratascratch.com/coding/10084-cum-sum-energy-consumption?code_type=1
This is a hard question that covers most of the topics I talked about. First, you need to write a CTE. Use it to write three SELECT statements that select all data from each table and join the outputs using the UNION ALL.
The second CTE will use data from the first CTE to fetch the total energy consumption by date using the SUM() aggregate function.
The outer query uses the data from the second CTE in the following way. The SUM() window function calculates the cumulative sum by ordering data from the oldest to the newest date.
Then this same window function is divided by the total energy consumption – which you can get by summing the energy consumption by date – and multiplying by 100 to get the percentage. Use the ROUND() function to show the result as rounded to the nearest whole number, i.e., there will be no decimal places.
There it is, the output that will get you points from the interviewer.

7. Text & Date Manipulation

Theory
The data scientists often have to handle text and dates/time in the databases, not only numerical values. This usually means creating one string from several ones or using only the part of the date (like day, month, year) or a string.
The most common text manipulation functions are:
| Text Function | Description |
| || or CONCAT() | Concatenates multiple string values into one. |
| CHAR_LENGTH() | Returns the of characters in a string. |
| LOWER() | Converts the string to all lowercase. |
| UPPER() | Converts the string to all uppercase. |
| SUBSTRING() | Returns the part of the string. |
| TRIM() | Deletes space or any other character from the start and end of a string. |
| LTRIM() | Deletes space or any other character from the start of a string. |
| RTRIM() | Deletes space or any other character from the end of a string. |
| LEFT() | Returns the defined number of characters from the start of a string. |
| RIGHT() | Returns the defined number of characters from the end of a string. |
The two most often used date/time functions are:
| Date/Time Function | Description |
| EXTRACT() | Returns the part of the date or time; SQL standard. |
| DATE_PART() | Returns the part of the date or time; PostgreSQL specific. |
Text & date/time functions come in handy for data scientists when they clean data. Of course, they can also perform calculations using the date/time functions, such as adding or subtracting time periods, and use it for data filtering, aggregation, etc.
SQL Questions
SQL Interview Question #19: Pending Claims
“Count how many claims submitted in December 2021 are still pending. A claim is pending when it has neither an acceptance nor rejection date.”
Link to the question: https://platform.stratascratch.com/coding/2083-pending-claims?code_type=1
Data
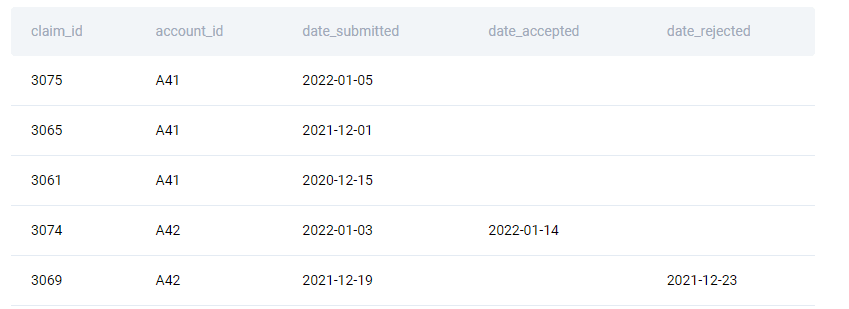
The question gives you the table cvs_claims.
| claim_id | int |
| account_id | varchar |
| date_submitted | datetime |
| date_accepted | datetime |
| date_rejected | datetime |
Make yourself familiar with the data.
Solution Approach
The COUNT() function is here for getting the number of claims. You need to count only the claims satisfying the certain criteria. Two criteria are set up with the help of the EXTRACT() function. The first one is used for extracting the month from the claim submission date. The other EXTRACT() function will get the year from the same column. That way, you get claims submitted in December 2021.
The next two criteria in the WHERE clause will show only claims that are not yet accepted nor rejected, i.e., they are pending.
SELECT COUNT(*) AS n_claims FROM cvs_claims WHERE EXTRACT(MONTH FROM date_submitted) = 12 AND EXTRACT(YEAR FROM date_submitted) = 2021 AND date_accepted IS NULL AND date_rejected IS NULL;
Output
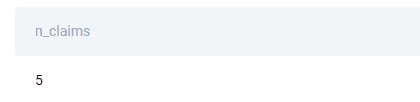
This solution shows there are five pending claims submitted in December 2021.
SQL Interview Question #20: Rush Hour Calls
“Redfin helps clients to find agents. Each client will have a unique request_id, and each request_id has several calls. For each request_id, the first call is an “initial call”, and all the following calls are “update calls”. How many customers have called 3 or more times between 3 PM and 6 PM (initial and update calls combined)?”
Link to the question: https://platform.stratascratch.com/coding/2023-rush-hour-calls?code_type=1
The solution uses the DATE_PART() function instead of EXTRACT(). It does that in the subquery in the FROM clause. The subquery shows the clients, but not all of them. First, data is filtered and cast to timestamp using the WHERE clause and D,ATE_PART() so the subquery will return only the clients making calls between 15 and 17 hours.
Data is additionally filtered after grouping using the HAVING clause. The condition shows only customers with three or more calls in the above time period.
This result will be used in the main query only for counting the number of customers.
Only one customer called three or more times between 15:00 and 17:00.
SQL Interview Question #21: Rules To Determine Grades
“Find the rules used to determine each grade. Show the rule in a separate column in the format of 'Score > X AND Score <= Y => Grade = A' where X and Y are the lower and upper bounds for a grade. Output the corresponding grade and its highest and lowest scores along with the rule. Order the result based on the grade in ascending order.”
Link to the question: https://platform.stratascratch.com/coding/9700-rules-to-determine-grades?code_type=1
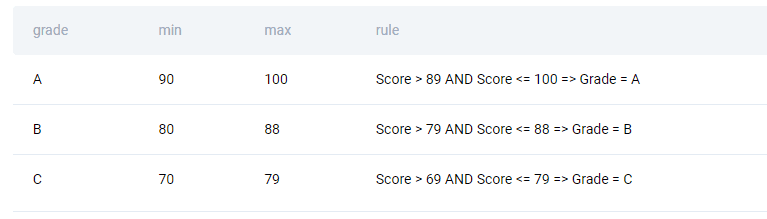
The SELECT statement returns the minimum and maximum score per grade. The last column is used for labeling the rules with the concatenate function. Use both MIN() and MAX() functions to get the following rules:
- Grade A: score > 89 and <= 100
- Grade B: score > 79 and <= 88
- Grade C: score > 69 and <= 79
Of course, the labels have to be formatted as is required.
The output is grouped by and ordered by grade.
Here are the rules.
SQL Theoretical Interview Questions
These questions test the SQL knowledge, too, the same as the coding questions. The difference is they don’t require writing a code, but you have to explain SQL concepts or the difference between them.
Here are some examples of such questions, all testing the topics I mentioned in the coding questions section.
SQL Interview Question #22: WHERE and HAVING
“What is the main difference between a WHERE clause and a HAVING clause in SQL?”
Link to the question: https://platform.stratascratch.com/technical/2374-where-and-having
Both WHERE and HAVING are used for filtering data. The main difference is that the WHERE clause is used for filtering data before aggregation and GROUP BY. The HAVING clause filters already aggregated data and is written after the GROUP BY clause.
SQL Interview Question #23: Left Join and Right Join
“What is the difference between a left join and a right join in SQL?”
Link to the question: https://platform.stratascratch.com/technical/2242-left-join-and-right-join
You can start off by explaining the similarities of these two outer joins. Then you can talk about their differences. Hint: the clue is in the ‘left’ and ‘right’.
SQL Interview Question #24: Common Table Expression
“In SQL, what is a Common Table Expression? Give an example of a situation when you would use it.”
Link to the question: https://platform.stratascratch.com/technical/2354-common-table-expression
You already saw how the CTEs work. You could talk about comparing them with subqueries and then give an example of a CTE use. There you have it in the coding questions.
Wrap up
The SQL interview questions usually come in two forms: coding and non-coding. Both question types most often test “The Unavoidable Seven”. You can’t even think of going to the interview without seven crucial SQL concepts.
Focus on them to cover the most SQL questions that can come up at the interview. The question difficulty is also one variable, so there can be a big difference in the knowledge required for solving the easy and hard questions.
Nate Rosidi is a data scientist and in product strategy. He's also an adjunct professor teaching analytics, and is the founder of StrataScratch, a platform helping data scientists prepare for their interviews with real interview questions from top companies. Connect with him on Twitter: StrataScratch or LinkedIn.