
Data Preparation with SQL Cheatsheet
If your raw data is in a SQL-based data lake, why spend the time and money to export the data into a new platform for data prep?
Importance of Data Preparation
Whether we like it or not, data prep is a major part of every data science project. Data preparation consists of tasks to prepare data in a repeatable process for use in business analytics, including data acquisition, data storage and handling, data cleaning, and early-stages of feature engineering.
Matthew Mayo: "Why is it that data preparation is often described as 80% of the work involved in data-related tasks, and do you think this is an accurate generalization?"
Sebastian Raschka: "80%? I often hear >90%!"
From Data Preparation Tips, Tricks, and Tools: An Interview with the Insiders, KDnuggets
A fundamental question is how and where to do the data prep. There are valid reasons to pick different tools and methods:
- Which tool or languages are your staff/peers most familiar with?
- Do you need a repeatable process, scheduled to run on a regular basis?
- Where is the bulk of your data currently located?
- What data volume and velocity are you dealing with?
- What current cloud services or on-prem resources exist to run the process?
- Which tools are most compatible with the current architecture in your organization?
- Does your dataset contain private elements (HIPA, FERPA, GDPR) that require special protection?
For many organizations, the answers to those questions are going to lead to SQL. Not only is SQL widely known and used in most organizations, but it also leverages existing database resources, security, and pipelines. If your raw data is in a SQL-based data lake, why spend the time and money to export the data into a new platform for data prep?
Data Preparation with SQL Cheatsheet
The following quick reference cheatsheet guide will give a sampling of SQL approaches to each of the steps in data preparation. This is not meant to be an exhaustive list of SQL functions or options, but rather a starting point.
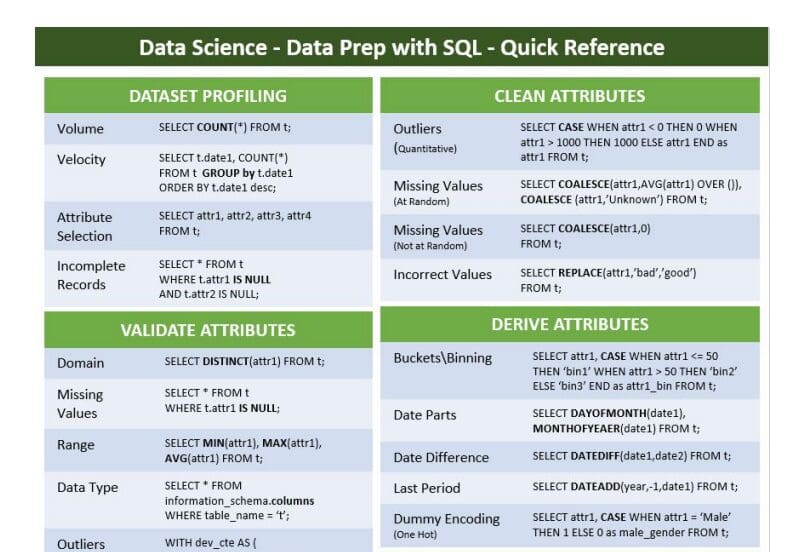
Click for full cheatsheet
Download the quick reference cheatsheet guide PDF here!
A final word on creating an interface to your model. SQL views allow you to wrap up the complexity of many of the data prep steps in a clean, secure, modular format. Rather than embedding long, complex queries in your Python or R code, you can create a view that allows access to that code in a simple, reusable format. Views are also a great way to apply security on private data elements by masking or hiding those from model access.
If you are already investing in high-performant database licenses, why not leverage them for data science by doing data prep in SQL?
Stan Pugsley is a data warehouse and analytics consultant with Eide Bailly Technology Consulting based in Salt Lake City, UT. He is also an adjunct faculty member at the University of Utah Eccles School of Business. You can reach the author via email.