Data Preparation in R Cheatsheet
Leverage the powerful data wrangling tools in R’s dplyr to clean and prepare your data.
Importance of Data Preparation
I’ve written before that whether we like it or not, data prep is a major part of every data science project. Data preparation consists of tasks to prepare data in a repeatable process for use in business analytics, including data acquisition, data storage and handling, data cleaning, and early-stages of feature engineering.
There are at least three common tools that data teams can use to do those data wrangling tasks:
- SQL, which is supported by many big data platforms like Spark, is excellent for doing the rough data filtering and collection from raw sources like data lake file collections
- Python, with the Pandas library, is growing in popularity and features
- R, specifically using the dplyr package, offers a cohesive set of functions backed by the enormous open-source collection of other R libraries.
Your choice among those three will likely depend on the skills available in your organization, the infrastructure and code base available, and the advanced models required to be used. For this article, we will focus on the reasons to use R, and provide a handy reference sheet.
dplyr, introduced in 2016, has some important features that make it an excellent tool for data prep in R.
- Data connections for nearly any data source or file format used in industry.
- dplyr was built as a harmonious package, simplifying many tasks that can be messy or confusing if you were to piece together other packages from the R world.
- Scripts are easily integrated with version control and Dev Ops practices
- Easy hand off data to powerful R libraries for integration with AI/ML models
Data Preparation in R Cheatsheet
The following quick reference cheatsheet guide guide will give a sampling of dplyr approaches to each of the steps in data preparation. This is not meant to be an exhaustive list of dplyr functions or options, but rather a starting point.
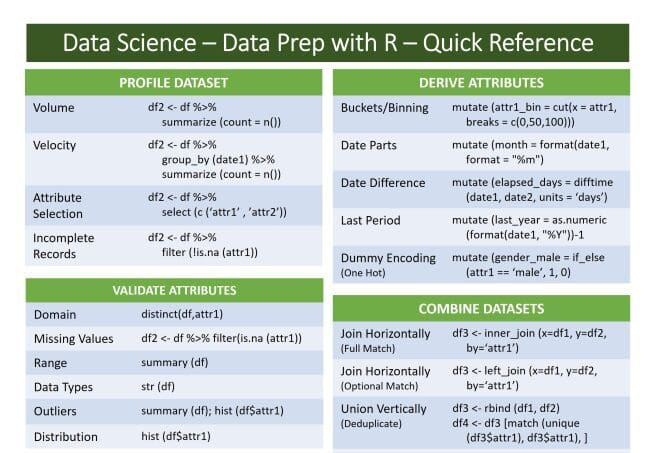
Click for full cheatsheet
Download the quick reference cheatsheet guide PDF here!
A decade ago, R was the only player for data science, but the increased competition from Python and SQL have only made it better, as features introduced in one ecosystem are quickly copied or ported to another. The broad R user community has a history of working make sure their libraries are alive and evolving, ensuring that your investment in R will be relevant in another decade. Some day in the future, perhaps dplyr, and the Tidyverse, will no longer be the best choice for data prep. But for now they make an excellent choice (despite a few awkward syntax elements like the %>% pipe!)
Stan Pugsley is an independent data warehouse and analytics consultant based in Salt Lake City, UT. He is also an assistant professor/lecturer at the University of Utah - Eccles School of Business. You can reach the author via email.