K-nearest Neighbors in Scikit-learn
Learn about the k-nearest neighbours algorithm, one of the most prominent workhorse machine learning algorithms there is, and how to implement it using Scikit-learn in Python.

Nina Strehl via Unsplash
K-nearest neighbors (KNN) is a type of supervised learning machine learning algorithm and can be used for both regression and classification tasks.
A supervised machine learning algorithm is dependent on labeled input data which the algorithm learns on and uses its learnt knowledge to produce accurate outputs when unlabeled data is inputted.
The use of KNN is to make predictions on the test data set based on the characteristics (labeled data) of the training data. The method used to make these predictions is by calculating the distance between the test data and training data, assuming that similar characteristics or attributes of the data points exist within close proximity.
It allows us to identify and assign the category of the new data whilst taking into consideration its characteristics based on learned data points from the training data. These characteristics of the new data point will be learned by the KNN algorithm and based on its proximity to other data points, it will be categorized.
Why is KNN a Good Algorithm?
KNN is a good algorithm to use, specifically for classification tasks. Classification is a typical task that a lot of Data Scientists and Machine Learning engineers come across. It solves a lot of real world problems.
Therefore, algorithms such as KNN are a good and accurate choice of algorithm to be used for pattern classification and regression models. KNN has been known not to make any assumptions about the data, leading to higher accuracy than other classification algorithms. The algorithm is also easy to implement and interpretable.
The ‘k’ in KNN
The ‘K’ in KNN is a parameter that refers to the number of nearest neighbors, where the K-value essentially creates an environment for the data points to understand its similarities based on proximity. Using the K-value, we compute the distance between the test data points and the trained labeled points to better categorize the new data points.
The K-value is a positive integer which is typically small in value with a recommendation that it be an odd number. When the K-value is small, the error rate decreases, with a low bias but a high variance which leads to overfitting of the model.
How do you Calculate the Distance Between the Data Points?
KNN is a distance-based algorithm, with the most common methods used being:
- Euclidean and Manhattan for continuous data
- Hamming distance for categorical data
Euclidean Distance is the mathematical distance between two points within Euclidean space using the length of a line between the two points. This is the most well known distance metric and a lot of people will remember it from school from Pythagoras Theorem.
Manhattan Distance is the mathematical distance between two points, which is the sum of the absolute difference of their Cartesian coordinates. In simple terms, the movement of direction between the distance can only be top, bottom and sideways.
Hamming distance compares two binary data strings and then compares these two string inputs to find the number of different characters in each position of the string.
Simple KNN Algorithm Steps
These are the general steps you need to take for the KNN algorithm
- Load in your dataset
- Choose a k-value. You should choose an odd number to avoid a tie.
- Find the distance between the new data point and the neighboring existing trained data points.
- Assign the new data point to its K nearest neighbor
Using sklearn for kNN
neighbours is a package from the sklearn module which you use for nearest neighbor classification tasks. This can be used for both unsupervised and supervised learning.
First, you will need to import these libraries:
import numpy as np import matplotlib.pyplot as plt import pandas as pd
This is the sklearn neighbors package:
sklearn.neighbors.KNeighborsClassifier
These are the parameters that can be used:
class sklearn.neighbors.KNeighborsClassifier(n_neighbors=5, *, weights='uniform', algorithm='auto', leaf_size=30, p=2, metric='minkowski', metric_params=None, n_jobs=None)
The distance metric used here in the example is minkowski, however as mentioned above there are different distance metrics you can use.
If you would like to know more about these parameters, click on this link.
K-nearest Neighbors in Scikit-Learn on the Iris Dataset
Load in the Iris Dataset
Import these libraries:
import numpy as np import matplotlib.pyplot as plt import pandas as pd
Import Iris dataset:
# url for Iris dataset url = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data" # Assign column names to the dataset names = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'Class'] # Read in the dataset df = pd.read_csv(url, names=names)
This is what the dataset should look like by executing df.head():
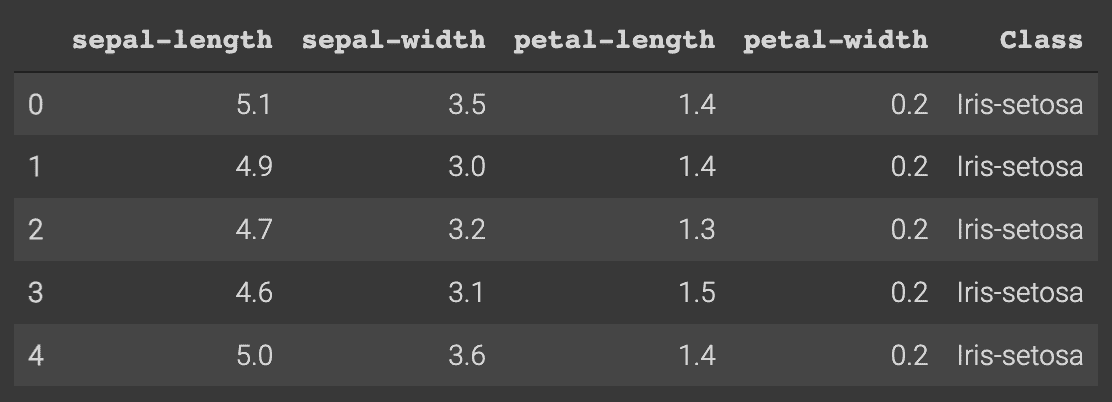
Preprocessing of Dataset
The next step is to split the dataset based on attributes and labels. The class column is considered out labels and is referred to as y, where the first 4 columns are attributes and will be referred to as X
X = dataset.iloc[:, :-1].values y = dataset.iloc[:, 4].values
Train/Test split
Using a train/test split on our dataset will help us to better understand how well our algorithm performs on unseen data/testing phase. It also helps with reducing overfitting from occurring.
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20)
Feature Scaling
Feature scaling is an important step before executing your model to start making predictions. It involves rescaling the features in a common boundary so that no information about each of the data points is lost. Without this, your model could possibly make wrong predictions.
from sklearn.preprocessing import StandardScaler scaler = StandardScaler() scaler.fit(X_train) X_train = scaler.transform(X_train) X_test = scaler.transform(X_test)
Make Your Prediction
This is where we will use the neighbors package from the sklearn module. As you can see, we have chosen our number of neighbors (K-value) as 5.
from sklearn.neighbors import KNeighborsClassifier classifier = KNeighborsClassifier(n_neighbors=5) classifier.fit(X_train, y_train)
Now we want to make a prediction on the test dataset:
y_pred = classifier.predict(X_test)
Evaluating Your Algorithm
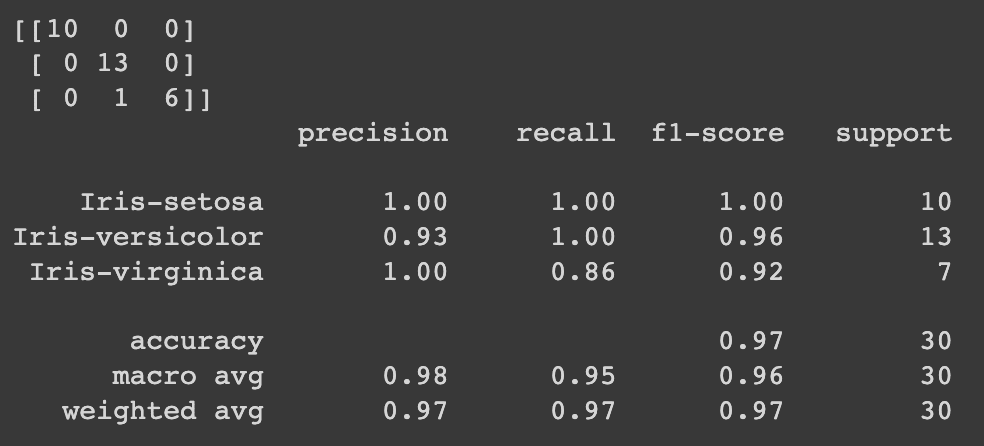
The most typical metrics used for evaluating your algorithm are confusion matrix, precision, recall and f1 score.
from sklearn.metrics import classification_report, confusion_matrix print(confusion_matrix(y_test, y_pred)) print(classification_report(y_test, y_pred))
This is the output:
Conclusion
So we’ve come to understand that KNN is a good algorithm to use for classification tasks and that the neighbors package in Scikit-learn can make it all so much easier. It is very simple and easy to implement with a flexibility to feature/distance choices. It has the ability to handle multi-class cases and it can effectively produce accurate outputs.
But there are some things you need to take into consideration when it comes to KNN. Determining the k-value can be difficult, because it can be the difference between causing overfitting or not. It can also be a matter of trial and error when determining which distance metric you should use.KNN also has a high computational cost as we compute the distances between the new data point and the training data points. With this being said, the KNN algorithm slows down as the number of examples and variables increases
Although it is one of the oldest and well used classification algorithms out there, you need to consider the con as well.
Nisha Arya is a Data Scientist and Freelance Technical Writer. She is particularly interested in providing Data Science career advice or tutorials and theory based knowledge around Data Science. She also wishes to explore the different ways Artificial Intelligence is/can benefit the longevity of human life. A keen learner, seeking to broaden her tech knowledge and writing skills, whilst helping guide others.