Machine Learning Metadata Store
In this article, we will learn about metadata stores, the need for them, their components, and metadata store management.

Photo by Manuel Geissinger
Machine learning is predominantly data-driven, involving large amounts of raw and intermediate data. The goal is usually to create and deploy a model in production to be used by others for the greater good. To understand the model, it is necessary to retrieve and analyze the output of our ML model at various stages and the datasets used for its creation. Data about these data are called Metadata. Metadata is simply data about data.
In this article, we will learn about:
- metadata stores,
- the components of the metadata store,
- the need for a metadata store
- the selection criteria for a metadata store
- metadata management,
- architecture and components of metadata management
- Declarative metadata management
- Popular Metadata Stores and their features
- There is a TL;DR of these stores in the form of a comparison table at the end of the article.
Why do we need a Metadata Store?
The process of building machine learning models is vaguely similar to conducting a science experiment from theory. You start with a hypothesis, design a model to test your hypothesis, test and improve your design to suit your hypothesis, and then pick the best method according to your data. With ML, you start with a hypothesis about which input data might produce desired results, train models, and tune the hyperparameters until you build the model which produces the results that you need.
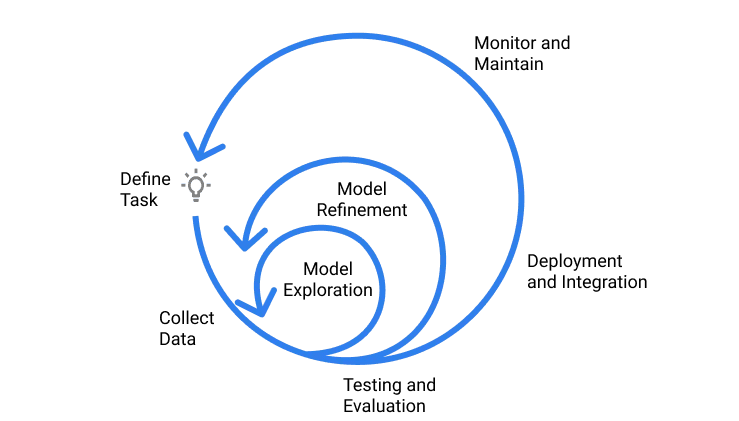
Fig: machine learning Development Lifecycle. [Source]
Storing these experimental data helps with comparability and reproducibility. The iterative model building process will be in vain if the experimental models’ parameters aren’t comparable. Reproducibility is also essential if there is a need to reproduce previous results. Given the dynamic and stochastic nature of ML experiments, achieving reproducibility is complicated.
Storing the metadata would help in retraining the same model and get the same results. With so much experimental data flowing through the pipeline, it’s essential to segregate the metadata of each experimental model from input data. Hence, the need to have a metadata store, i.e., a database with metadata.
Types of Metadata
Now that we have discussed why storing metadata is important, let’s look at the different types of metadata.
Data
Data used for model training and evaluation play a dominant role in comparability and reproducibility. Other than data, you can store the following:
- Pointer to data’s location
- Name and version of the dataset
- Column names and types of data
- Statistics of dataset
Model
The experiment is usually to lock down on a model fitted to our business needs. Until the end of the experiment, it’s hard to put a pin on which model to proceed with. So, it is useful and saves a lot of time if all the experimental models are reproducible. It should be noted that we are focused on the models to be reproducible rather than retrievable. To retrieve a model, one has to store all the models taking up too much space. This is avoidable as the following parameters help one reproduce a model when needed.
Feature preprocessing steps
The raw data has already been accounted for and saved to be retrieved. But this raw data is not always fed to the model for training. In most cases, the crucial information which the model needs, i.e., the features, are picked from the raw data and become the model’s input.
Now, since we aim for reproducibility, we need to guarantee consistency in the way the selected features are processed, and hence, the feature preprocessing steps need to be saved. Some examples of the preprocessing steps are feature augmentation, dealing with missing values, transforming it into a different format that the model requires, etc.
Model type
To recreate the model, store the type of model used like AlexNet, YoloV4, Random Forest, SVM, etc., with their versions and frameworks like PyTorch, Tensorflow, and Scikit-learn. This ensures there is no ambiguity in the selection of the model when reproducing it.
Hyperparameters
The ML model usually has a loss or cost function. To create a robust and efficient model, we aim to minimize the loss function. The weights and biases of the model where the loss function is minimized are the hyperparameters that need to be stored to reproduce the efficient model created earlier. This saves processing time in finding the right hyperparameters to tune the model and speeds the model selection process.
Metrics
The results from the model evaluation are important in understanding how well you have built your model. They help in figuring out :
- if the model is overfitting to the training set,
- how different hyperparameters affect the output, and the evaluation metrics or
- perform thorough error analysis.
Storing these data helps in performing model evaluation at any given point in time.
Context
Model context is information about the environment of an ML experiment that may or may not affect the experiment’s output but could be a factor of change in it.
Model context includes:
- Source code
- Dependencies like any packages and their versions
- Programming language and their versions
- Host information like environment variables, system packages, etc.
Use case of Metadata Stores
Now, we know about metadata, the need for it, and what comprises a metadata store. Let’s look at some of the use cases of metadata stores and how you can use them in your ML workflow:
- Search and discovery. Data search and data discovery involve collecting and evaluating data from various sources. It is often used to understand trends and patterns in the metadata. You get information regarding data schemas, fields, tags, and usage.
- Access control ensures that all team members can access the same metadata and prove vital in team collaboration. It makes sure the metadata is accessed by control groups and adheres to the organization’s policies.
- Data lineage is a map of the data journey, which includes its origin, each stop along the way, and an explanation on how and why the data has moved over time. It helps track pipeline executions, queries, API logs, and API schemas.
- Data compliance is the practice of ensuring that the organization follows a set of regulations to protect sensitive data against misuse. It states what type of data should be protected, how it should be protected, and what penalties would be charged if one fails to achieve it. Having the metadata organized, stored, and managed in one place helps govern the data under these regulations.
- Data management. A metadata store helps to configure data sources, ingestion, and retention. It helps in following data purge policies and data export policies.
- ML explainability and reproducibility. The ideal metadata store has all the information one would need to reproduce the ML model. This information can be used to justify the purpose the model serves as per business needs.
- DataOps. DataOps is a practice that brings speed and agility to end-to-end data pipelines, from collection to delivery. Since a metadata store has all the necessary information about the data flowing in the workflow, it proves instrumental when practicing DataOps.
- Data quality. As the name suggests, having the meta of all the data helps assess the data quality and ensures data quality which is crucial for any successful ML model development.
Why do we need Metadata Management?
Just storing the metadata without any management is like keeping thousands of books unorganized. We are storing these data for boosting our model building. Without any management, it’s harder to retrieve the data and compromises its reproducibility. Metadata management ensures data governance.
Here is a comprehensive list of why metadata management is necessary:
- Unify and tame data from diverse models and systems.
- Observe data compliance and ensure that data is managed according to Regulations like SR-11, GDPR, and the California Privacy Rights Act necessary to control and secure data efficiently at scale.
- Managed information about the whole ML workflow helps significantly in debugging and root cause analysis.
- Data governance at scale requires a level of automation, especially when different tools are used.
- Data discovery is essential for productivity. Finding the right data at the time of need saves a lot of time.
Metadata management architecture
A podcast on Rise of Meta management by Assaf Araki and Ben Lorica beautifully explains the three building blocks of metadata management systems.
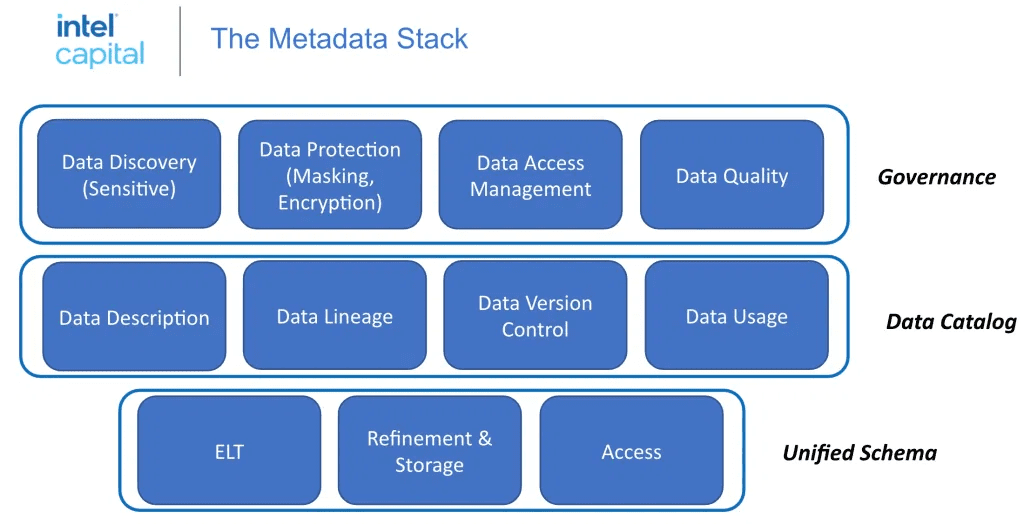
Fig: Metadata Stack. [Source]
Unified schema
The metadata needs to be collected from all systems. The three components in this layer do this job:
- Extract, load, transform - ELT is the process of extracting data from one or multiple sources and loading it to data warehouses. It is an alternative to the traditional ETL (extract, transform, load).
Since it takes advantage of the processing capability already built into a data storage infrastructure, ELT reduces the time data spends in transit and boosts efficiency.
- Refinement and storage - refining and storing in a format help in easy retrieval of data.
- Access - APIs or domain-specific languages for extracting data from metadata systems are used to build the subsequent layers.
Data Catalog
Now that we have collected the data in the previous layer, the data needs to be categorized into a catalog to make it informative and reliable. Its four components help in achieving this task:
- Data description - A detailed description with summaries of all data elements.
- Data lineage - a record of the journey data takes from creation through its transformations over time. It's a process of understanding, recording, and visualizing data as it flows.
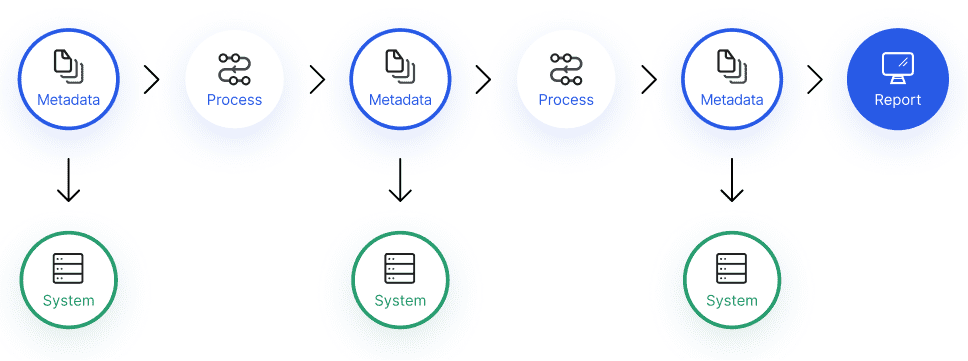
Fig: Data Lineage process [Source]
- Version Control - Version control for data ensures tracking of the changes in the datasets over time.
- Data Usage tracks data consumption by users or applications, or systems. It helps in observing the flow of data and helps in building cost-management solutions.
Governance
As the name suggests, this layer collectively works to govern the data and ensure that the data is consistent and secure. It is the process organizations use to manage, utilize and protect data in enterprise systems.

Fig: Pillars of Data Governance.[Source]
Learn more about Data Governance Guide.
Coming to the components that ensure data governance:
- Data discovery detects sensitive data across all platforms, saving time and limiting the risk of manual errors.
- Data protection reduces the exposure and unnecessary spread of sensitive data while maintaining usability.
- Data access management ensures the data adheres to organizational policy and regulations.
- Data quality helps assess the quality of the data and ensures accuracy, completeness, consistency, and relevance.
Declarative Metadata Management
Declarative metadata management is a lightweight system that tracks the lineage of the artifacts produced during your ML workflow. It automatically extracts metadata such as hyperparameters of models, schemas of datasets, and architecture of deep neural networks.
A Declarative metadata system can be used to enable a variety of functionalities like:
- regular automated comparisons of models to older ones,
- quantifying accuracy improvements that teams achieve over time towards a specific goal, e.g., by storing and comparing the output of their model and
- showing the difference in the leaderboard.
Here, the experimental metadata and ML pipelines that comprise a way to define complex feature transformation chains are automatically extracted, easing its metadata tracking system. It is achieved by a schema designed to store the lineage information and ML-specific attributes. The figure below shows the important principles of declarative metadata management.

Fig: Important principles of Declarative Metadata Management. Source: Graphical representation of principles discussed in DMM - Image created by the author
The systems employ a three-layered architecture to use the above-discussed principles.
- Layer 1 is a document database store that stores the actual experimental data.
- Layer 2 is a centralized data store exposed to the outside world, allowing users to store metadata for particular artifacts explicitly and queries the existing data.
- Layer 3: This uppermost layer, also called the high-level clients, is engineered towards popular ML libraries like SparkML, Scikit-learn, MXNet.
The high-level clients in level 3 enable automated metadata extraction from internal data structures of popular ML frameworks.
Let’s take examples from some of these frameworks to get a clearer understanding.
- SparkML: the ML workloads in SparkML contain DataFrames. The architecture of SparkML pipeline allows the DMM system to automatically track all the schema transformations (like reading, adding, removing columns) each pipeline conducts and parameterization of the operators.
- MXNet: The MXNet framework furnishes a fine-grained abstraction to declaratively define the models by combining mathematical operators (like convolutions, activation functions) into the network’s layout to learn. The 3rd layer extracts and stores the resulting computational graph, parameterization, and dimensionality of the operators and corresponding hyperparameters.
How Declarative Metadata Management Proves to be Useful
Now that we have a brief understanding of declarative metadata management, let’s see how these properties improve your ML workflow:
- Automated regressive testing: Instead of storing arbitrary key-value tags, the ML code, or the actual data, the DMM stores the pointers to the actual data. This imposes strict decoupling of the parameters from the workflow. Furthermore, it gives us the privilege to automate querying, interpretation, and analysis of the metadata and lineage. This automated analysis enables regressive testing of the models.
- Automated metadata extraction: The DMM schema enforces the storage of artifacts and pointers to ML-specific attributes and lineage information. Since it strictly focuses on metadata, the querying or metadata extraction supports the automation of the process.
- Accelerated experimentation: The automated comparison of models to the other models during experimentation provides the team's ease of quantifying improvements and hence accelerates the experimentation process.
- Increase automation: The goal of the entire model building is to make it scalable and production-ready. The automation of many steps in the workflow eases and helps in avoiding errors at such a large scale. The automation of testing and metadata extraction decreases manual labor and reduces the burden on the team.
Suppose one wishes to take the Declarative Metadata Management to the next level instead of automatically extracting metadata. In that case, one could enable meta learning which would recommend features, algorithms, or hyperparameters settings for new datasets. This again requires implementing the automated computation of meta features for contained datasets and similarity queries to find the most similar datasets for new data based on these meta-features.
Selection Criteria for your Metadata Store
Before going into more detail about metadata stores, let’s look at important features that would help you select the right metadata store.
- Easy Integration - Since you are using it to ease and speed up your ML development, you should consider its ease of integration into your current pipeline and the tools.
- Data lineage management - Data lineage keeps track of the data flow. If you deal with various data flowing during experiments, you should consider data lineage management capabilities.
- Allows data wrangling - If you expect a lot of variety in types of data then, data wrangling will clean and structure the metadata for easy access and analysis. This assures quality data. Another thing to keep in mind here is it allows an intuitive query interface too.
- Tracking features - If the platform allows data tracking, code versioning, notebook versioning, environment versioning, it would give you access to a wider range of metadata and ensure easy reproducibility.
- Scalability - If you are building your ML model to take it to production, scalability of the metadata store becomes a factor to consider.
- Team Collaboration - If you will work in a large team, having this feature would prove necessary.
- UI - Lastly, having a user-friendly UI ensures clear management of experiments and is adopted by all the team members seamlessly.
List of Metadata Stores
Metadata needs to be stored for comparability and reproducibility of the experimental ML models. The common metadata stored are the hyperparameters, feature preprocessing steps, model information, and the context of the model. The data needs to be managed as well.
Previously, we also looked into the qualities one might consider for choosing the right metadata store. With all of these in mind, let’s have a look at some of the widely used metadata stores.
Layer Data Catalog
Layer provides a central repository for datasets and features to be systematically built, monitored and evaluated. Layer is unique from other metadata stores for being a declarative tool that empowers it to provide automated entity extraction and automated pipelines . In addition, it provides data management, monitoring and search tools, etc.
Some of its features are:
Data discovery
Layer provides a powerful search for easy discovery of data while adhering to authorization and governance rules. There are two central repositories, one for data and the other for models. The data catalog manages and versions the data and features.
The model catalog has all the ML models organized and versioned in centralized storage space, making it accessible to recall a model used in experimentation.
Auto versioning
With datasets, schemas changing, files being deleted, and pipelines breaking, auto versioning helps create reproducible ML pipelines. This automatic tracking of lineage between entities streamlines your ML workflow and helps in reproducing the experiments.
Feature store
The feature store is unique to Layer. The features are grouped into `featuresets` which make features more accessible. These `featuresets` can be dynamically created, deleted, passed as value, or stored. You can simply build features, and Layer gives you the privilege to serve them online or offline.
Data quality testing
Layer ensures good quality data by executing automated tests. It assists you in creating responsive or automated pipelines with Declarative Metadata Management (discussed earlier) to automatically build, test and deploy the data and ML models. This ensures not only quality testing of data but also continuous delivery and deployment.
Data lineage
The data is religiously tracked and managed by Layer. The tracking is done automatically between versioned and immutable entities(data, model, feature, etc.). As at any given point, one could reproduce the experiments. Layer also gives a better understanding of the previous experiments.
Scalability
Most of the properties of the Layer Data Catalog work hand in hand with automation. The datasets, featureset, and ML models are also first-class entities that make it easy to manage their lifecycle at scale. Layer also has infra agnostic pipelines which support resources for scalability.
Easy collaboration
Along with empowering the data teams with its features during experimentation, it can also be used to monitor the lifecycle of the entities post-production. Its extensive UI supports tracking drift, monitoring changes, version diffing, etc.
Amundsen
Amundsen is a metadata and data discovery engine. Some of its features are:
- Discover trusted data - Searching for data within the organization is simple.
- Automated and curated metadata - build trust in data with automated and curated metadata. Preview of the data is also permitted.
- Easy integration and automation of metadata.
- Easy triage by linking the ETL job and code that generated the data.
- Team collaboration - you can share context with co-workers easily and see what data they follow frequently or own or find common queries.
Tensorflow Extended ML Metadata
ML Metadata or MLMD is a library whose sole purpose is to serve as a Metadata Store. It stores and documents the metadata and, when called, retrieves it from the storage backend with the help of APIs.
Some of its features are:
- Data lineage management - the lineage information associated with pipeline components is stored and can be traced when needed.
- Along with the usual storage of metadata about artifacts generated during the pipeline, it also stores metadata about executions of the pipeline.
- It can easily be integrated into your ML workflow.
Kubeflow
Kubeflow not only offers a Metadata store but a solution for the entire lifecycle of your enterprise ML workflow.
The one we are interested in now is KubeFlow Metadata. Some of its features are:
- Easy scalability - with Kubeflow being a solution for enterprise ML, scalability plays an important role.
- Versioning - All metadata and other artifacts are version controlled.
- It has inbuilt Jupyter notebook servers, which help in data wrangling.
- It can easily be integrated into your ML workflow.
- One can record metadata on a notebook with lineage tracking.
Apache Atlas
Apache Atlas’s metadata store provides features that allow organizations to manage and govern the metadata. Some of its features are:
- Data Discovery - an intuitive UI to search entities by type, classification, attribute value, or plain text.
- View lineage of data as it moves through components in the pipeline.
- You can dynamically create classifications like SENSITIVE_DATA, EXPIRES_ON, etc., and propagate this via lineage. It automatically ensures that the classification follows the data as it passes through components.
- Fine grained security for metadata access, enabling controls to entity instances.
Sagemaker
Amazon SageMaker feature store is a fully managed repository to store, update, retrieve and share machine learning features. It keeps track of the metadata of the stored features.
So if you are keen on storing metadata of features and not of the whole pipeline, the Sagemaker feature store is the right choice for you. Here are some of its other features:
- Ingest data from many sources - You can either create data using data preparation tools like Amazon SageMaker Data Wrangler or use streaming data sources like Amazon Kinesis Data Firehose.
- Data discovery - It tags and indexes metadata for easy discovery through the visual interface in SageMaker Studio. It also allows browsing the data catalog.
- Ensure feature consistency - It allows models to access the same set of metadata and features for training runs done offline and in batches and for real-time inference.
- Standardization eliminates confusion across teams by storing metadata definitions in a single repository, making it clear how each metadata is defined. Having well-defined data makes it easier to reuse metadata for different applications.
MLflow
The metadata store in MLflow goes by the name MLflow Tracking. It records and queries the code, data, configurations, and results from the experiments.
MLflow logs parameters, code versions, metrics, key-value input parameters, etc., when running machine learning code and later the API and UI helping in visualizing the results too. Some of its features are:
- It lets you log and query experiments in many languages like Python, REST, R API, and Java API.
- The output files can be saved in any format. For example, you can record images(PNGs), models(pickled sci-kit-learn model), and data files(Parquet file) as artifacts.
- It can organize and record runs into experiments, which group together runs for a specific task.
- You can choose where your runs are recorded. It can either be logged locally(default), a database, and an HTTP server.
- MLflow provides automatic logging. This feature eases logging the metadata such as metrics, parameters, and models by not relying on explicit log statements.
Final Thoughts
One cannot deny the importance of data in the field of machine learning. A metadata store that has all the essential data about the data is undeniably important. According to different business needs, the right metadata store could vary from organization to organization.
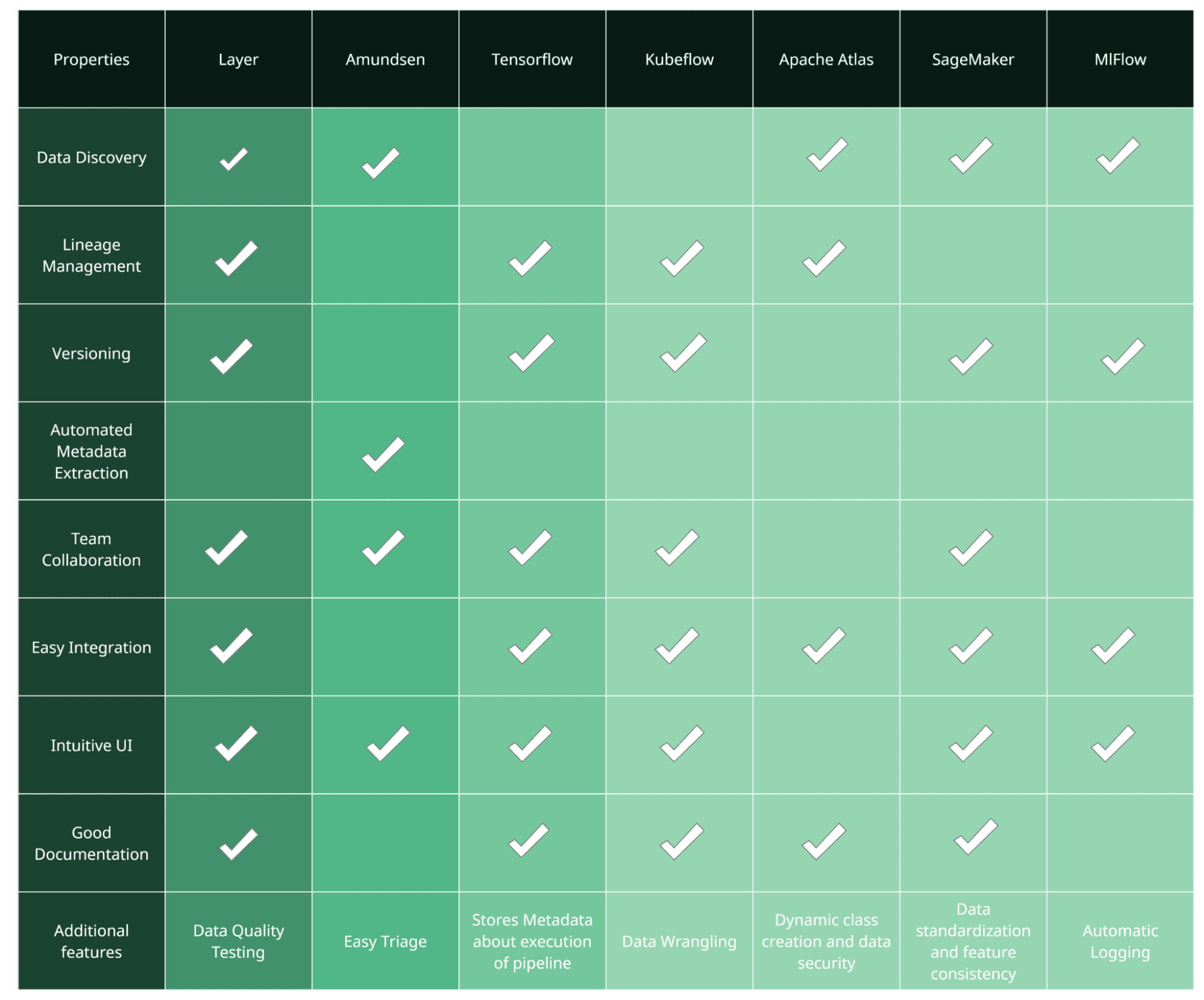
I have accumulated and summarized the seven metadata stores we discussed earlier. I hope this would give you an overview of some famous metadata stores and nudge you into finding the right one. This conclusion is based purely on the information found in the documentation in the metadata stores.
Further, read
- Walkthrough of ML metadata with Tensorflow
- Kubeflow for machine learning
- From Data to Metadata for machine learning Platforms
- ML Metadata: Version control for ML
- Video on the need for ML metadata
- Big picture of metadata management for data governance
- Lecture on metadata lifecycle
Akruti Acharya is a technical content writer and graduate student at University of Birmingham