The Difference Between Training and Testing Data in Machine Learning
When building a predictive model, the quality of the results depends on the data you use. In order to do so, you need to understand the difference between training and testing data in machine learning.
When building a predictive model, the quality of the results depends on the data you use. If you are using not enough or wrong data, your model will not be able to make realistic predictions and will lead you in the wrong direction. To avoid this, you need to understand the difference between training and testing data in machine learning.
Without further ado, let’s dive in.
Training Data
Let’s say you want to create a model based on some database. In machine learning, this data is divided into two parts: training and testing data.
Training data is the one you feed to a machine learning model, so it can analyze it and discover some patterns and dependencies. This training set has 3 main characteristics:
- Size. The training set normally has more data than testing data. The more data you feed to the machine, the better quality model you have. Once a machine learning algorithm is provided with data from your records, it learns patterns from it and makes a model for decision-making.
- Label. A label is a value of what we try to predict (response variables). For example, if we want to forecast if the patient will be diagnosed with cancer, based on their symptoms, the response variable will be Yes/No for the cancer diagnosis. The training data can be labeled and unlabeled. Both types can be used in machine learning for different cases.
- Case details. Algorithms make decisions based on the information you give them. You need to make sure that the data is relevant and has various cases with different outcomes. For instance, if you need a model that can score potential borrowers, you need to include in the training set the information you normally know about your potential client during the application process:
- Name and contact details, location;
- Demographics, social and behavioral characteristics;
- Source of origin (Meta Ads, website landing page, third party, etc.)
- Factors connected to the behavior/activity on websites, conversions, time spent on a website, number of clicks, and more.
Testing Data
After the machine learning model is built, you need to check its work. The AI platform uses testing data to evaluate the performance of your model and adjust or optimize it for better forecasts. The testing set should have the following characteristics:
- Unseen. You cannot reuse the same information that was in the training set.
- Large. The data set should be large enough so that the machine can make predictions.
- Representative. The data should represent the actual dataset.
Luckily, you don’t need to collect new data and compare predictions with actual data manually. The AI can split the existing data into two parts, put testing set aside while training, and then run tests comparing predictions and actual results all by itself. Data science has different options for data split, but the most common proportions are 70/30, 80/20, and 90/10.
So having a massive data set at hand, we can check if it’s possible to make predictions based on that model or not.
Example of How Training and Testing Data Work
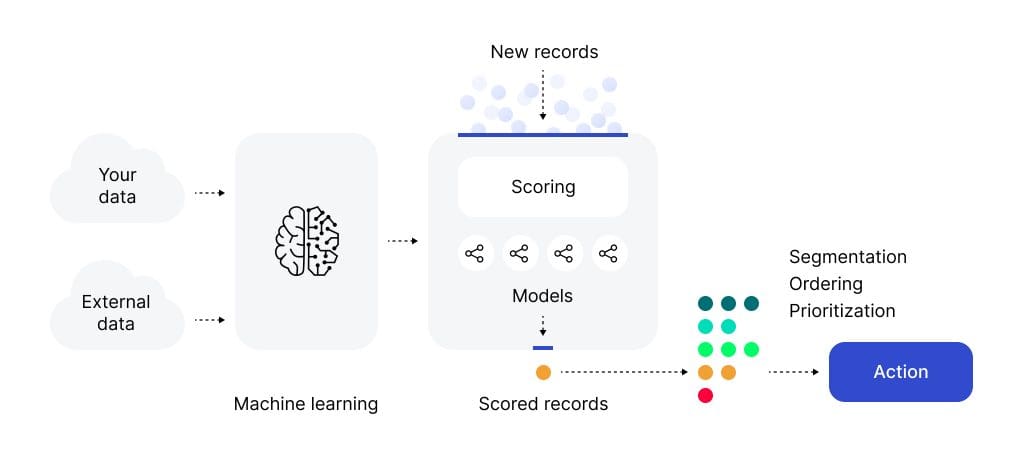
Now, let’s see how these 2 data sets work in practice. As an example, we’ll take GiniMachine - a no-code AI decision-making platform.
The evaluation process in such systems is called the blind test. When building a model, AI splits the data in a ratio of about 70% to 30%, where the first figure is training data and the second is testing. During training, the machine analyzes different metrics and how they influence the result. And during the blind test, it tries to calculate the score for test records and predict the result. It can work with custom ratios and stratifications on multiple targets as well as double-factor ones.
After the model is built and tested, the machine calculates a special index that represents the quality of the model. Thus, users can decide to use this model for scoring or create another one.
How Much Data is Enough for Machine Learning
Both training and testing sets should be large enough to let the machine learn. But how much exactly is enough?
Well, It depends on the platform you use. Some machines need at least 1,000 records to build a model. But the quality of the data is important. The industry has an unwritten rule: use 1,000 bad records + X number of good ones to create a reliable model. For instance, 1,000 non-performing loans + X ones with successfully repaid debts.
However, this is only an approximate number. The exact number of records needed for your unique case can only be determined by testing different options. From our experience, it is possible to build a decent model with only 100 records, and some cases need over 30,000 records.
Using GiniMachine, which we mentioned before, you have unlimited opportunities to experiment with different data and build as many models as you wish. But if you use other platforms, like Visier People, or underwrite.ai, their requirements for the data may differ. Pay attention to these characteristics when choosing a decision-making platform.
Prediction Errors
When talking about prediction models, it’s important to mention two phenomena that affect the quality of prediction: bias-variance tradeoff and the curse of dimensionality.
In a nutshell, the bias-variance tradeoff is the balance between creating too general or too specific models. The model with high bias is usually oversimplified and makes a lot of mistakes in training and test data. This happens when we have too little and too general data. For example, if you try to teach the model how to differentiate cats and dogs using only ten examples of the fur length and color. To solve this problem, you need to use more data and variables.
And the model with high variance does not generalize data at all. So it shows good results on training data but has many errors on test data. This scenario is possible if you fed the model with too specific data with many features. So it can’t understand what features are the most important and can’t make the right prediction with the unseen data. Also, the high amount of features increases the complexity of your model and can lead to the curse of dimensionality. In this situation, you need to combine individual characteristics into clusters and clean up the dataset from unnecessary information.
How to Use Data in Business
The possibilities of machine learning and AI-based prediction softwareare endless. They can help you forecast demand for your product, evaluate new leads and choose the most promising projects, score credit applications and debt collection, automate hiring processes, or analyze healthcare and agricultural data. There are no limits to using such a platform. With the right dataset, you can build the needed model, start scoring and get a bigger business output.
Mark Rudak is a machine learning product owner at Ginimachine