How to Package and Distribute Machine Learning Models with MLFlow
MLFlow is a tool to manage the end-to-end lifecycle of a Machine Learning model. Likewise, the installation and configuration of an MLFlow service is addressed and examples are added on how to generate and share projects with MLFlow.
One of the fundamental activities during each stage of the ML model life cycle development is collaboration. Taking an ML model from its conception to deployment requires participation and interaction between different roles involved in constructing the model. In addition, the nature of ML model development involves experimentation, tracking of artifacts and metrics, model versions, etc., which demands an effective organization for the correct maintenance of the ML model life cycle.
Fortunately, there are tools for developing and maintaining a model’s life cycle, such as MLflow. In this article, we will break down MLflow, its main components, and its characteristics. We’ll also offer examples showing how MLflow works in practice.
What is MLflow?
MLflow is an open-source tool for the development, maintenance, and collaboration in each phase of the life cycle of an ML model. Furthermore, MLflow is a framework-agnostic tool, so any ML / DL framework can quickly adapt to the ecosystem that MLflow proposes.
MLflow emerges as a platform that offers tools for tracking metrics, artifacts, and metadata. It also provides standard formats for packaging, distributing, and deploying models and projects.
MLflow also offers tools for managing model versions. These tools are encapsulated in its four main components:
- MLflow Tracking,
- MLflow Projects,
- MLflow Models and
- MLflow Registry.
MLflow Tracking
MLflow Tracking is an API-based tool for logging metrics, parameters, model versions, code versions, and files. MLflow Tracking is integrated with a UI for visualizing and managing artifacts, models, files, etc.
Each MLflow Tracking session is organized and managed under the concept of runs. A run refers to the execution of code where the artifact log is performed explicitly.
MLflow Tracking allows you to generate runs through MLflow’s Python, R, Java, and REST APIs. By default, the runs are stored in the directory where the code session is executed. However, MLflow also allows storing artifacts on a local or remote server.
MLflow Model
MLflow Models allow packaging machine learning models in a standard format to be consumed directly through different services such as REST API, Microsoft Azure ML, Amazon SageMaker, or Apache Spark. One of the advantages of the MLflow Models convention is that the packaging is multi-language or multi-flavor.
For packaging, MLflow generates a directory with two files, the model and a file that specifies the packaging and loading details of the model. For example, the following code snippet shows an MLmodel file where the flavor loader is specified as well as the `conda.yaml` file that defines the environment.
artifact_path: model
flavors:
python_function:
env: conda.yaml
loader_module: MLflow.sklearn
model_path: model.pkl
python_version: 3.8.2
sklearn:
pickled_model: model.pkl
serialization_format: cloudpickle
sklearn_version: 0.24.2
run_id: 39c46969dc7b4154b8408a8f5d0a97e9
utc_time_created: '2021-05-29 23:24:21.753565'
MLflow Project
MLflow Projects provides a standard format for packaging, sharing, and reusing machine learning projects. Each project can be a remote repository or a local directory. Unlike MLflow Models, MLflow Projects aims at the portability and distribution of machine learning projects.
An MLflow Project is defined by a YAML manifest called `MLProject`, where the project’s specifications are exposed.
The key features for the implementation of the model are specified in the MLProject file. These include:
- the input parameters that the model receives,
- the data type of the parameters,
- the command for executing the model, and
- the environment in which the project runs.
The following code snippet shows an example of an MLProject file where the model to implement is a decision tree whose only parameter is the depth of the tree and whose default value is 2.
name: example-decision-tree
conda_env: conda.yaml
entry_points:
main:
parameters:
tree_depth: {type: int, default: 2}
command: "python main.py {tree_depth}"
Likewise, MLflow provides a CLI to run projects located on a local server or a remote repository. The following code snippet shows an example of how a project is run from a local server or a remote repository:
$ mlflow run model/example-decision-tree -P tree_depth=3 $ mlflow run git@github.com:FernandoLpz/MLflow-example.git -P tree_depth=3
In both examples, the environment will be generated based on the `MLProject file` specification. The command that triggers the model will be executed under the arguments passed on the command line. Since the model allows input parameters, these are assigned through the `-P` flag. In both examples, the model parameter refers to the maximum depth of the decision tree.
By default, a run like the one shown in the example will store the artifacts in the `.mlruns` directory.
How to Store Artifacts in an MLflow Server?
One of the most common use cases when implementing MLflow is using MLflow Server to log metrics and artifacts. The MLflow Server is responsible for managing the artifacts and files generated by an MLflow Client. These artifacts can be stored in different schemes, from a file directory to a remote database. For example, to run an MLflow Server locally, we type:
$ mlflow server
The above command will start an MLflow service through the IP address http://127.0.0.1:5000/. To store artifacts and metrics, the tracking URI of the server is defined in a client session
In the following code snippet, we will see the basic implementation of artifact storage in an MLflow Server:
import MLflow
remote_server_uri = "http://127.0.0.1:5000"
MLflow.set_tracking_uri(remote_server_uri)
with MLflow.start_run():
MLflow.log_param("test-param", 1)
MLflow.log_metric("test-metric", 2)
The `MLflow.set_tracking_uri ()` command sets the location of the server.
How to Run Authentication in an MLflow Server?
Exposing a server with no authentication can be risky. Therefore, it is convenient to add authentication. Authentication will depend on the ecosystem in which you will deploy the server:
- on a local server, it is enough to add a basic authentication based on user and password,
- on a remote server, credentials must be adjusted coupled with respective proxies.
For illustration, let's look at an example of an MLflow Server deployed with basic authentication (username and password). We will also see how to configure a client to make use of this server.
Example: MLflow Server authentication
In this example, we apply basic user and password authentication to the MLflow Server through an Nginx reverse proxy.
Let's start with the installation of Nginx, which we can do in the following way:
# For darwin based OS $ brew install nginx # For debian based OS $ apt-get install nginx # For redhat based OS $ yum install nginx
For Windows OS, you have to use the native Win32 API. Please follow the detailed instructions here.
Once installed, we will proceed to generate a user with its respective password using the `htpasswd` command, which is as follows:
sudo htpasswd -c /usr/local/etc/nginx/.htpasswd MLflow-user
The above command generates credentials for the user `mlflow-user` in the `.htpasswd` file of the nginx service. Later, to define the proxy under the created user credentials, the configuration file `/usr/local/etc/nginx/nginx.conf` is modified, which by default has the following content: :
server {
listen 8080;
server_name localhost;
# charset koi8-r;
# access_log logs/host.access.log main;
location / {
root html;
index index.html index.htm;
}
which has to look like this:
server {
# listen 8080;
# server_name localhost;
# charset koi8-r;
# access_log logs/host.access.log main;
location / {
proxy_pass http://localhost:5000;
auth_basic "Restricted Content";
auth_basic_user_file /usr/local/etc/nginx/.htpasswd;
}
We are defining an authentication proxy for localhost through port 5000. This is the IP address and port number where MLflow Server is deployed by default. When using a cloud provider, you must configure the credentials and proxies necessary for the implementation. Now initialize the MLflow server as shown in the following code snippet:
$ MLflow server --host localhost
When trying to access http://localhost in the browser, authentication will be requested through the username and password created.
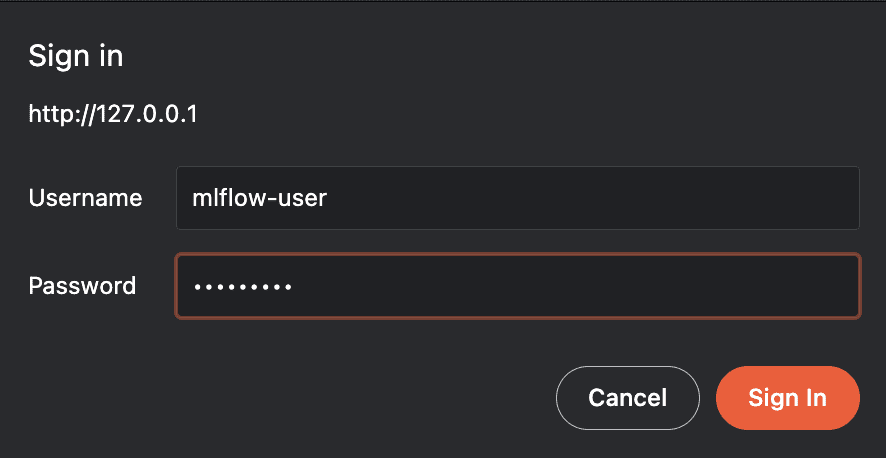
Figure 1. Login
Once you have entered the credentials, you will be directed to the MLflow Server UI.
Figure 2. MLflow Server UI
To store data in MLflow Server from a client, you have to:
- define the environment variables that will contain the credentials to access the server and
- set the URI where the artifacts will be stored.
So, for the credentials, we are going to export the following environment variables:
$ export MLflow_TRACKING_USERNAME=MLflow-user $ export MLflow_TRACKING_PASSWORD=MLflow-password
Once you have defined the environment variables, you only need to define the server URI for the artifact storage.
import MLflow
# Define MLflow Server URI
remote_server_uri = "http://localhost"
MLflow.set_tracking_uri(remote_server_uri)
with MLflow.start_run():
MLflow.log_param("test-param", 2332)
MLflow.log_metric("test-metric", 1144)
When executing the code snippet above, we can see the test metric and parameter reflect on the server.
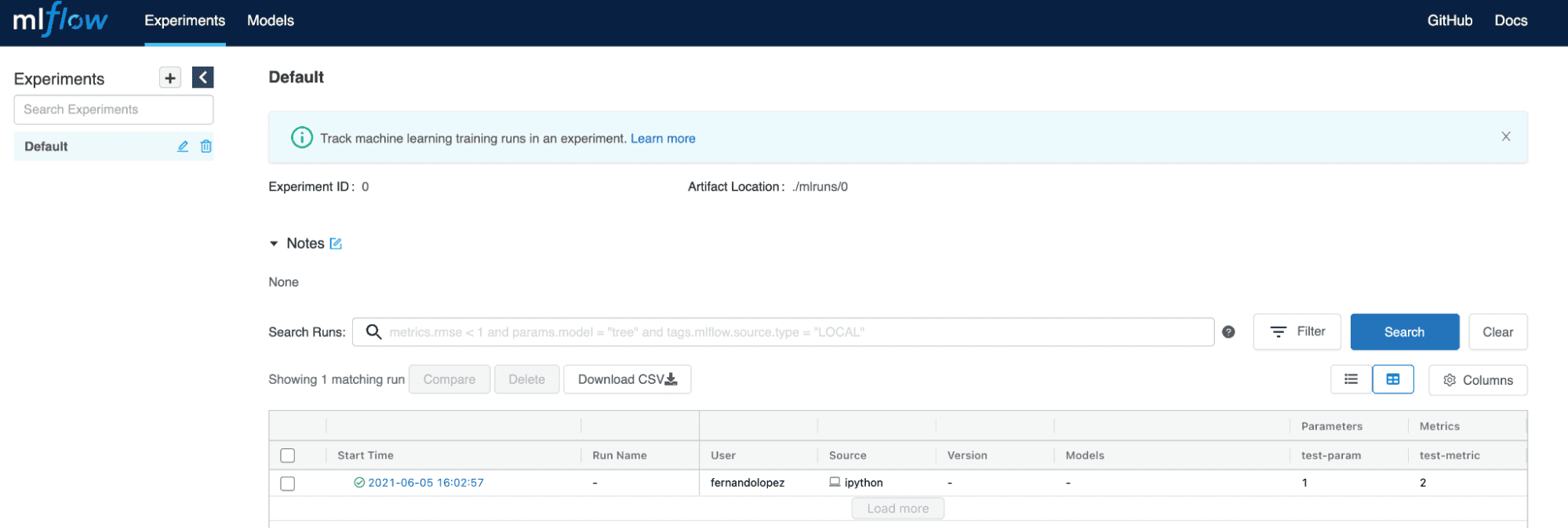
Figure 3. Metrics and parameters stored from a client service with authentication on the server.
How to Register an MLflow Model?
One of the everyday needs when developing machine learning models is to maintain order in the versions of the models. For this, MLflow offers the MLflow Registry.
The MLflow Registry is an extension that helps to:
- manage versions of each MLModel and
- record the evolution of each model in three different phases: archive, staging, and production. It is very similar to the git version system.
There are four alternatives for registering a model:
- through the UI,
- as an argument to `MLflow.<flavor> .log_model()`,
- with the `MLflow.register_model()` method or
- with the `create_registered_model()` client API.
In the following example, the model is registered using the `MLflow.<flavor> .log_model()` method:
with MLflow.start_run():
model = DecisionTreeModel(max_depth=max_depth)
model.load_data()
model.train()
model.evaluate()
MLflow.log_param("tree_depth", max_depth)
MLflow.log_metric("precision", model.precision)
MLflow.log_metric("recall", model.recall)
MLflow.log_metric("accuracy", model.accuracy)
# Register the model
MLflow.sklearn.log_model(model.tree, "MyModel-dt", registered_model_name="Decision Tree")
If it is a new model, MLFlow will initialize it as Version 1. If the model is already versioned, it will be initialized as Version 2 (or subsequent version).
By default, when registering a model, the assigned status is none. To assign a status to a registered model, we can do it in the following way:
client = MLflowClient()
client.transition_model_version_stage(
name="Decision Tree",
version=2,
stage="Staging"
)
In the above code snippet, version 2 of the Decision Tree model is assigned to the Staging state. In the server UI, we can see the states as shown in Figure 4:

Figure 4. Registered Models
To serve the model we will use the MLflow CLI, for this we only need the server URI, the model name, and the model status, as shown below:
$ export MLflow_TRACKING_URI=http://localhost $ mlflow models serve -m "models:/MyModel-dt/Production"
Model is Served and POST Eequests
$ curl http://localhost/invocations -H 'Content-Type: application/json' -d '{"inputs": [[0.39797844703998664, 0.6739875109527594, 0.9455601866618499, 0.8668404460733665, 0.1589125298570211]}'
[1]%
In the previous code snippet, a POST request is made to the address where the model is served. An array that contains five elements has been passed in the request, which is what the model expects as input data for the inference. The prediction, in this case, turned out to be 1.
However, it is important to mention that MLFlow allows defining the data structure for inferring in the `MLmodel` file through the implementation of signatures. Likewise, the data passed through the request can be of different types, which can be consulted here.
The full implementation of the previous example can be found here: https://github.com/FernandoLpz/MLFlow-example
MLflow Plugins
Due to the framework-agnostic nature of MLflow, MLflow Plugins emerged. Its primary function is to extend the functionalities of MLflow in an adaptive way to different frameworks.
MLflow Plugins allow customization and adaptation of the deployment and storage of artifacts for specific platforms.
For example, there are plugins for a platform-specific deployment:
- MLflow-redisai: which allows the creation of deployments to RedisAI from models created and managed in MLFlow,
- MLflow-torchserve: which enables PyTorch models to be deployed directly to TorchServe,
- MLflow-algorithmia: that allows deployment of models created and managed with MLFlow, to the Algorithmia infrastructure, and
- MLflow-ray-serve: that supports deployment of MLFlow models to the Ray infrastructure.
On the other hand, for the management of MLflow Projects, we have MLflow-yarn, a plugin for managing MLProjects under a Hadoop / Yarn backed. For the customization of MLflow Tracking, we have MLflow-elasticsearchstore, which allows the management of the MLFlow Tracking extension under an Elasticsearch environment.
Likewise, specific plugins are offered for deployment in AWS and Azure. They are:
It is essential to mention that MLflow provides the ability to create and customize plugins according to needs.
MLflow vs. Kubeflow
Due to the increasing demand for tools to develop and maintain the life cycle of machine learning models, different alternatives such as MLflow and KubeFlow have emerged.
As we have already seen throughout this article, MLflow is a tool that allows collaboration in developing the life cycle of machine learning models, mainly focused on tracking artifacts (MLflow Tracking), collaboration, maintenance, and versioning of the project.
On the other hand, there is KubeFlow, which, like MLflow, is a tool for developing machine learning models with some specific differences.
Kubeflow is a platform that works on a Kubernetes cluster; that is, KubeFlow takes advantage of the containerization nature of Kubernetes. Also, KubeFlow provides tools such as KubeFlow Pipelines, which aim to generate and automate pipelines (DAGs) through an SDK extension.
KubeFlow also offers Katib, a tool for optimizing hyperparameters on a large scale and provides a service for management and collaboration from Jupyter notebooks.
SEO Link: Kubernetes and Kubeflow guides
Specifically, MLflow is a tool focused on management and collaboration for the development of machine learning projects. On the other hand, Kubeflow is a platform focused on developing, training, and deploying models through a Kubernetes cluster and the use of containers.
Both platforms offer significant advantages and are alternatives for developing, maintaining, and deploying machine learning models. However, it is vital to consider the barrier to entry for the use, implementation, and integration of these technologies in development teams.
Since Kubeflow is linked to a Kubernetes cluster for its implementation and integration, it is advisable to have an expert for managing this technology. Likewise, developing and configuring pipeline automation is also a challenge that demands a learning curve, which under specific circumstances may not be beneficial for companies.
In conclusion, MLflow and Kubeflow are platforms focused on specific stages of the life cycle of machine learning models. MLflow is a tool with a collaboration orientation, and Kubeflow is more oriented to take advantage of a Kubernetes cluster to generate machine learning tasks. However, Kubeflow requires experience in the MLOps part. One needs to know about the deployment of services in Kubernetes, which can be an issue to consider when trying to approach Kubeflow.
Fernando López (GitHub) is Head of Data Science at Hitch leading a data science team for the development and deployment of artificial intelligence models throughout the organization for video interview evaluation, candidate profiling and evaluation pipeline.