Handling Missing Values in Time-series with SQL
This article is about a specific use-case that comes up often when dealing with time-series data.
This morning I read Madison Schott’s article about the LAST_VALUE function, where she highlights the usefulness of this lesser-known SQL function.
It inspired me to write a follow-up article about a specific use-case that comes up often when dealing with time-series data.
An Example
Let’s pretend you’re building a predictive maintenance model using sensor data.
After some wrangling, you end up with hourly data that looks like this:
Example of some preprocessed sensor data
At this point, we’ve already done some pretty significant data engineering in order to create these evenly spaced observations at every hour. How to do this is a subject for another article. However, take notice that there are some gaps in the temperature measurements. This is where LAST_VALUE comes to the rescue.
The reason for the missing values is usually because sensors only report when the value changes. This reduces the amount of data that the machine needs to transmit, but it creates a data problem for us to solve.
The Reason Why
If we build a model with this data directly, the accuracy is going to suffer when a particular value is missing, because there is no historical context written into the row itself. For the most accurate model possible, we should add features such as:
- Last temperature reading
- Avg temperature over past 6 hours
- Hours since temperature reading increased/decreased
- Rate of change of temperature over past 12 hours
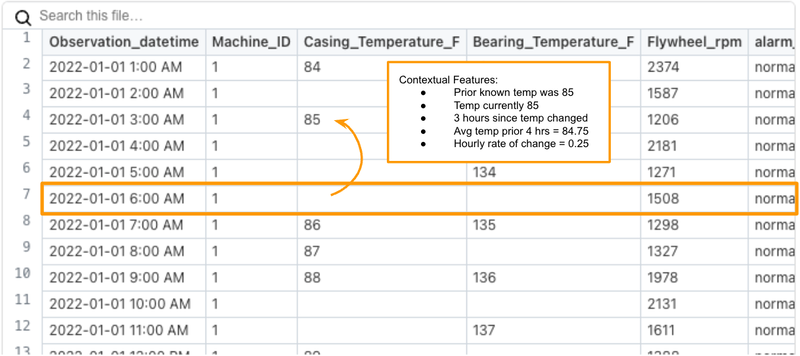
An illustration of the types of features that will be useful for a predictive model
Our very first step should be to replace the missing values with the last known value. The reason we choose to do this first, is because the other features will become much easier to create.
For example, if we leave them missing and try to calculate a rolling average, the average will be calculated incorrectly (it will ignore the missing values and only average the non-missing).
Avg Temp Prior 4 hours (with missing)
(null + 85 + null + null) / 1 = 85
Avg Temp Prior 4 hours (replaced)
(84 + 85 + 85 + 85) / 4 = 84.75
How to Fix It
In python, we would start with forwardfill. However, doing this in SQL means that we can take advantage of the power of our data warehouse.
In SQL, we use LAST_VALUE. See this article for a more in depth explanation.
Here is the syntax:
SELECT
MACHINE_ID,
OBSERVATION_DATETIME,
LAST_VALUE(
CASING_TEMPERATURE_F ignore NULLS
) OVER (
PARTITION BY MACHINE_ID
ORDER BY
OBSERVATION_DATETIME ROWS BETWEEN UNBOUNDED PRECEDING
AND CURRENT ROW
) AS LATEST_CASING_TEMPERATURE_F,
LAST_VALUE(
BEARING_TEMPERATURE_F ignore NULLS
) OVER (
PARTITION BY MACHINE_ID
ORDER BY
OBSERVATION_DATETIME ROWS BETWEEN UNBOUNDED PRECEDING
AND CURRENT ROW
) AS LATEST_BEARING_TEMPERATURE_F,
LAST_VALUE(FLYWHEEL_RPM ignore NULLS) OVER (
PARTITION BY MACHINE_ID
ORDER BY
OBSERVATION_DATETIME ROWS BETWEEN UNBOUNDED PRECEDING
AND CURRENT ROW
) AS LATEST_FLYWHEEL_RPM,
--8<-- snip --8<--
FROM
hourly_machine_data
Result with the missing replaced with LAST_VALUE
There we have it!
Conclusion
Hopefully I’ve been able to shine a light on LAST_VALUE and it’s cousin, FIRST_VALUE , which are lesser known SQL Window functions.
Josh Berry (@Twitter) leads Customer Facing Data Science at Rasgo and has been in the data and analytics profession since 2008. Josh spent 10 years at Comcast where he built the data science team and was a key owner of the internally developed Comcast feature store - one of the first feature stores to hit the market. Following Comcast, Josh was a critical leader in building out Customer Facing Data Science at DataRobot. In his spare time Josh performs complex analysis on interesting topics such as baseball, F1 racing, housing market predictions, and more.
Original. Reposted with permission.