Machine Learning Algorithms – What, Why, and How?
This post explains why and when you need machine learning and concludes by listing the key considerations for choosing the correct machine learning algorithm.
Image by Editor
Identifying Machine Learning Solvable Problems
machine learning is a field of learning patterns through data without any need for explicitly programming or hand-written rules. It’s a subfield of artificial intelligence (AI) and computer science.
Before machine learning became mainstream, programmers wrote rules derived from a function of their domain knowledge, observation of some hand-picked instances, and the business requirement to perform a particular task. But this legacy way of delivering business results suffered some evident constraints.
- Hand-written rules are limited by the knowledge of what edge cases a programmer can cover. This concept is very well explained by one of the most highly cited papers in the world of psychology titled “The Magical Number Seven, Plus or Minus Two: Some Limits on Our Capacity for Processing Information.”
- Commonly cited as Miller’s law, the paper describes the limited amount of information an average brain can hold and how it becomes unmanageable with the increasing number of variables and dimensions.
- Data is dynamic by nature and has become more so over the last decade with the proliferation of technology in our day-to-day lives. The varying data patterns fed to static pre-written rules are of little help to the business in taking meaningful actions. That is where the pattern mining ability of machine learning algorithms is put to the best use.
Let’s take an example of a fraud detection case. The programmer would write rules that if the transaction amount is above $10K, transaction location is X, and it is made from a particular type, i.e., wire transfer, then it is flagged as a potentially fraudulent transaction.
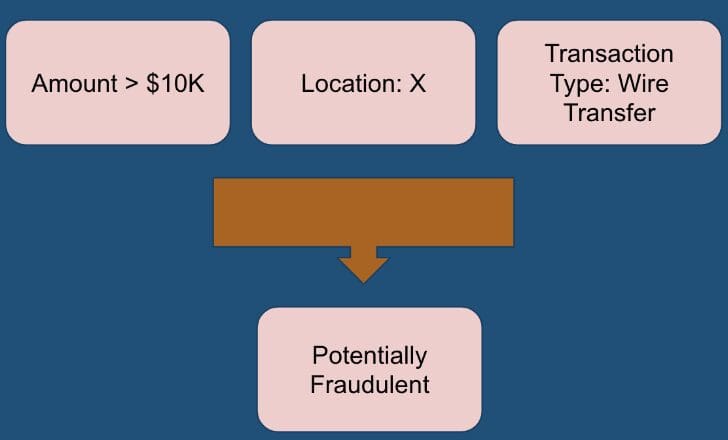
Source: Author
This could work like a charm for some time until the bad actors find an intelligent way to commit fraud. The conventional hard-coded rules are no more effective in detecting fraud. As their way of operation evolves, our fraud detection system needs to become too.
Further, all the software development processes are highly collaborative?—?what if the developer who wrote the initial rules is no longer associated with the fraud detection project? And the new developer tasked with upgrading the logic has no understanding of the previous system and is skeptical about whether the recent changes will have backward compatibility. To summarize, updating a rule-based system is not only a cumbersome process but unscalable too.
That’s where machine learning algorithms come to our rescue. If the metrics are well-defined and well-aligned with the business objective, it continues to learn from the new training data and evolves into a sophisticated machine learning system.
How to Choose the Right Algorithm
By now, we understand what type of business problems machine learning algorithms are best suited for and what are the broad categories in terms of statistical formulation of the given use case.
So, the next step is to identify which particular algorithm is the right fit for solving a machine learning problem. No rule book or guide can give you an instant answer, but we will discuss the factors experienced data scientists consider while selecting a set of candidate algorithms.
Sci-kit learn has published a flow chart that is a good starting point to understand which algorithms are appropriate for what type of data and the given problem.
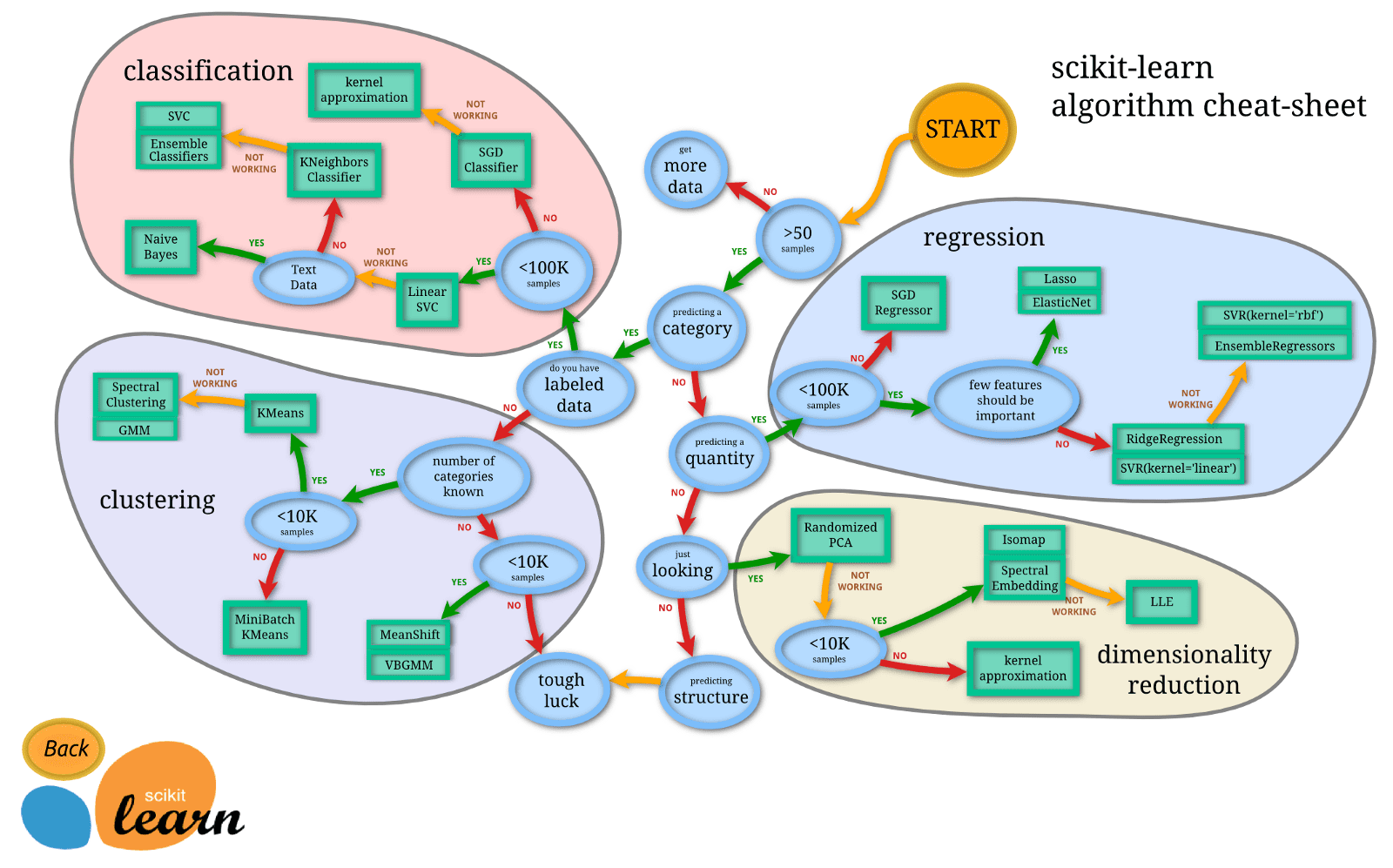
Source: https://scikit-learn.org/stable/tutorial/machine_learning_map/index.html
It is easy to get overwhelmed by the number of advanced algorithms and start implementing them to find the suitable model by hit and trial. But time is of the essence, and you need to narrow down the selection of algorithms to a minor candidate set, e.g., 2 or 3.
We have reduced our algorithm search space to a small set and will now list the pros and cons, limitations, and constraints.
Several factors go into deciding the suitable champion model:
- Accuracy: does it meet the qualifying criteria of performing above the threshold?
- Data Availability: how much data do you have?
- Resources: how long the model takes to train? Is it compute-expensive?
- Latency: the time to draw inferences in real time
- Explainability: can predictions be explained?
- Robustness to outliers: Is it sensitive to abnormal behavior?
- Non-linear associations: If the data follows a non-linear pattern, that rules out the linear models
- Missing Values: is your algorithm capable of handling missing values?
The above-listed factors give a quick and easy basis for your selection. Further, I will conclude this section by attributing to the “No Free Lunch” theorem, which states that:
“No one model works best for every problem. The assumptions of a great model for one situation may not hold for another issue, so it is common in machine learning to try multiple models and find one that works best for a particular case”
To understand this theorem, we must first determine what a model does. A model tries to capture the real-world phenomenon by boxing it under some assumptions. These assumptions help simplify the modeling environment and focus only on relevant details. Hence, a model that is a good fit for one problem might not work well for another.
Now that we understand the essential factors in selecting machine learning algorithms, you can refer to this excellent cheat sheet to understand the universe of algorithms.
Summary
The article’s key highlight is to understand the significance of machine learning algorithms. Further, it explains different model selection criteria to help you find the suitable machine learning algorithm for your business problem. Notably, no one go-to algorithm works well across multiple use cases. The post concludes by sharing cheat sheets to understand the mapping of the type of data and business problem with that of an algorithm.
Vidhi Chugh is an award-winning AI/ML innovation leader and an AI Ethicist. She works at the intersection of data science, product, and research to deliver business value and insights. She is an advocate for data-centric science and a leading expert in data governance with a vision to build trustworthy AI solutions.