An Introduction to SMOTE
Improve the model performance by balancing the dataset using the synthetic minority oversampling technique.
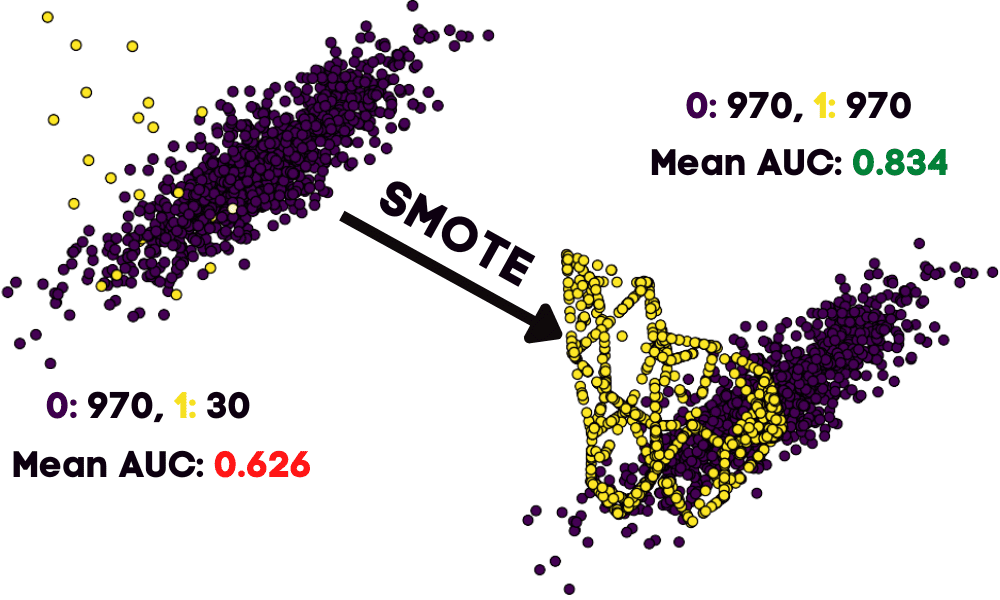
Image by Author
When we have an imbalance classification dataset, there are few minority class examples for the model to learn the decision boundary. It also affects the model's performance overall.
You can solve this problem by oversampling the minority class, and you can achieve it by duplicating the examples of a minority class in the training dataset. It will balance the class distribution, but it won’t improve the model performance, as it does not provide extra information to the model.
So, how do you balance the class distribution and improve the model performance at the same time? By synthesizing new examples from a minority class using SMOTE (Synthetic Minority Oversampling Technique).
What is SMOTE?
SMOTE (Synthetic Minority Oversampling Technique) is an oversampling method of balancing class distribution in the dataset. It selects the minority examples that are close to the feature space. Then, it draws the line between the examples in the features space and draws a new sample at a point along that line.
In simple words, the algorithm selects the random example from the minority class and selects a random neighbor using K Nearest Neighbors. The synthetic example is created between two examples in the feature space.
There is a drawback to using SMOTE, as it does not consider the majority class while creating synthetic examples. This can cause issues where there is a strong overlap between the classes.
Let’s see SMOTE in action by using the Imbalanced-Learn library.
%pip install imbalanced-learn
Note: we are using a Deepnote notebook to run the experiments.
Unbalanced Dataset
We will create an imbalanced classification dataset using make_classification from sci-kit learn’s dataset module.
from collections import Counter
from sklearn.datasets import make_classification
from imblearn.over_sampling import SMOTE
import matplotlib.pyplot as plt
# create a binary classification dataset
X, y = make_classification(
n_samples=1000,
n_features=2,
n_redundant=0,
n_clusters_per_class=1,
weights=[0.98],
random_state=125,
)
labels = Counter(y)
print("y labels after oversampling")
print(labels)
As we can observe, there are 1K samples. 970 belongs to 0 labels, and only 30 belongs to 1.
y labels after oversampling
Counter({0: 970, 1: 30})
We will then visualize the dataset using matplotlib’s pyplot.
As we can see, there are only a few yellow dots (1s) on the graph compared to purple. It is a clear example of an imbalanced dataset.
plt.scatter(X[:, 0], X[:, 1], marker="o", c=y, s=50, edgecolor="k");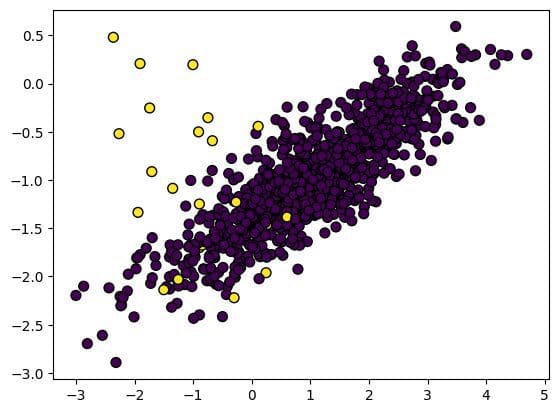
Model Training and Evaluation
Before we balanced the dataset using oversampling, we need to set a baseline for the model performance.
We will use the Decision Tree classification model on the dataset using 10-fold, 3-times cross-validation for training and evaluation. In short, we will be training and evaluating 30 models on the dataset.
The stratification in RepeatedStratifiedKFold means that each cross-validation is split so that they have the same class distribution as the original dataset.
import numpy as np
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier()
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
result = cross_val_score(model, X, y, scoring="roc_auc", cv=cv, n_jobs=-1)
print("Mean AUC: %.3f" % np.mean(result))
We got the ROC AUC mean score of 0.626 which is quite low.
Mean AUC: 0.626
Oversampling using SMOTE()
We will now apply an oversampling method SMOTE to balance our dataset. We will be using imbalanced-learn’s SMOTE function and provide it with features(X) and labels(y).
over = SMOTE()
X, y = over.fit_resample(X, y)
labels = Counter(y)
print("y labels after oversampling")
print(labels)
Both 0, 1 labels are now balanced with 970 samples in each.
y labels after oversampling
Counter({0: 970, 1: 970})
Let’s visualize the synthetically balanced dataset. We can clearly see that we have equal amounts of yellow and purple dots.
plt.scatter(X[:, 0], X[:, 1], marker="o", c=y, s=50, edgecolor="k");
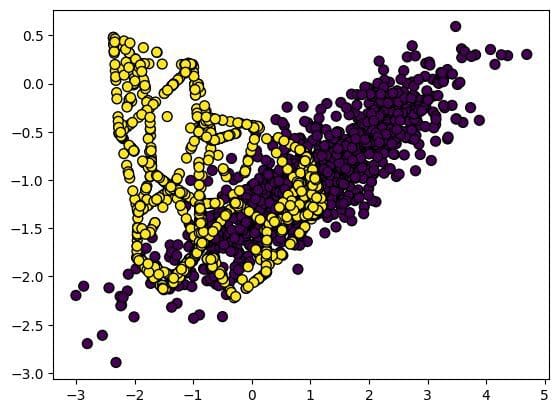
Model Training and Evaluation
We will now train the model on a synthetic dataset and evaluate the results. We are keeping everything the same, so that we compare it with our baseline result.
model = DecisionTreeClassifier()
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
result = cross_val_score(model, X, y, scoring="roc_auc", cv=cv, n_jobs=-1)
print("Mean AUC: %.3f" % np.mean(result))
After training for a few seconds we got an improved result or ROC AUC mean score of 0.834. It clearly shows that oversampling does improve the model performance.
Mean AUC: 0.834
Conclusion
The original SMOTE paper suggests that we should combine oversampling (SMOTE) with the undersampling of the majority class, as SMOTE does not consider the majority class while creating new samples. The combination of oversampling of minority class (SMOTE) and undersampling of majority class give us better results.
In this tutorial, we have learned about why we use SMOTE and how it works. We have also learned about the imbalanced-learn library and how we can use it to improve the model performance and balance the class distribution.
I hope you like my work, don’t forget to follow me on social media to learn about DS, ML, NLP, MLOps, Python, Julia, R, and Tableau.
Reference
Abid Ali Awan (@1abidaliawan) is a certified data scientist professional who loves building machine learning models. Currently, he is focusing on content creation and writing technical blogs on machine learning and data science technologies. Abid holds a Master's degree in Technology Management and a bachelor's degree in Telecommunication Engineering. His vision is to build an AI product using a graph neural network for students struggling with mental illness.