Introduction to Python Libraries for Data Cleaning
Accelerate your data-cleaning process without a hassle.

Image by pch.vecto on Freepik
Data cleaning is a must-do activity for any data expert because we need our data to be error-free, consistent, and usable for analysis. Without this step, the analysis result might suffer. However, data cleaning often takes a long time and could be repetitive. Moreover, sometimes we miss an error that we need to realize.
That is why we can rely on the Python packages designed for data cleaning. These packages were designed to improve our data cleaning experience and shorten data cleaning processing time. What are these packages? Let’s find out.
PyJanitor
Pandas provide many data-cleaning functions, such as fillna and dropna, but they could still be enhanced. PyJanitor is a Python package that provides data-cleaning APIs within the Pandas API without replacing them. The package provides various methods including, but not limited to, the following:
- Cleaning Column Names,
- Identifying Duplicate Values,
- Data Factorization,
- Data Encoding,
And many more. However, what is special about the PyJanitor is that the APIs can be executed via the chain method. Let’s test them with the example data. For this example, I would use the Titanic Training data from Kaggle.
For starters, let’s install the PyJanitor package.
pip install pyjanitor
Then we would load the Titanic dataset.
import pandas as pd
df = pd.read_csv('train.csv')
df.head()

We would use the above dataset for our example. Let’s try the PyJanitor package to clean our data with some sample functions.
import janitor
df.factorize_columns(column_names=["Sex"]).also(
lambda df: print(f"DataFrame shape after factorize is: {df.shape}")
).bin_numeric(from_column_name="Age", to_column_name="Age_binned").also(
lambda df: print(f"DataFrame shape after binning is: {df.shape}")
).clean_names()
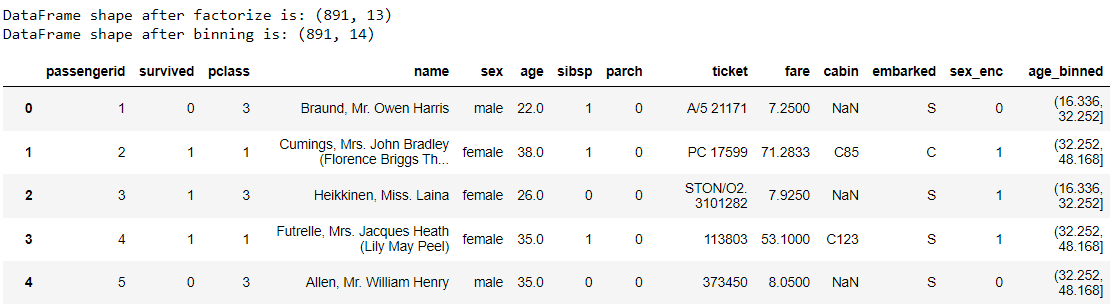
We transform our initial data frame with a chaining method. So, what happens with the code above? Let me break it down.
- First, we transform the ‘Sex’ column into a numerical with factorize function,
- With the also function, we print the shape after factorization,
- Next, we bin the age into groups using the bin_numeric function,
- Same with the also function,
- Lastly, we clean the column’s name by converting them to lowercase, then replaces all spaces with underscores using clean_names
All the above can be done with single chaining methods that directly done in our Pandas data frame. You can still do much more with the PyJanitor package, so I suggest you review their documentation.
Feature-engine
Feature-Engine is a Python package designed for feature engineering and selection that preserves the scikit-learn APIs method, such as fit and transform. The package was designed to provide a data transformer embedded in the machine learning pipeline.
The package provides various data-cleaning transformers, including but not limited to:
- Data Imputation,
- Categorical Encoding,
- Outlier Removal,
- Variable Selection,
And many more functions. Let’s try the package by installing them first.
pip install feature-engine
The Feature-Engine usage is easy; you only need to import them and train the transformer, similar to scikit-learn API. For example, I use an Imputer to fill the Age column missing data with the Median.
from feature_engine.imputation import MeanMedianImputer
# set up the imputer
median_imputer = MeanMedianImputer(imputation_method='median', variables=['Age'])
# fit the imputer
median_imputer.fit(df)
median_imputer.transform(df)
The code above would fill our age column in the data frame with the median. There are so many transformers you could experiment on. Try to find the one that suits your data pipeline on the documentation.
Cleanlab
Cleanlab is an open-source Python package to clean any issues with the machine learning dataset label. It’s designed to make any machine learning training with noisy labels more robust and provide a reliable output. Any model with probabilistic output can be trained alongside Cleanlab packages.
Let’s try out the package with a code example. First, we need to install the Cleanlab.
pip install cleanlab
As Cleanlab works to clean the label issues, let’s try to prepare the dataset for machine learning training.
# Selecting the features
df = df[["Survived", "Pclass", "SibSp", "Parch"]]
# Splitting the dataset
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
df.drop("Survived", axis=1), df["Survived"], random_state=42
)
After the dataset is ready, we would try to fit the dataset with a classifier model. Let’s look at the prediction metrics without cleaning the label.
#Fit the model
from sklearn.linear_model import LogisticRegression
model = LogisticRegression(random_state = 42)
model.fit(X_train, y_train)
preds = model.predict(X_test)
#Print the metrics result
from sklearn.metrics import classification_report
print(classification_report(y_test, preds))
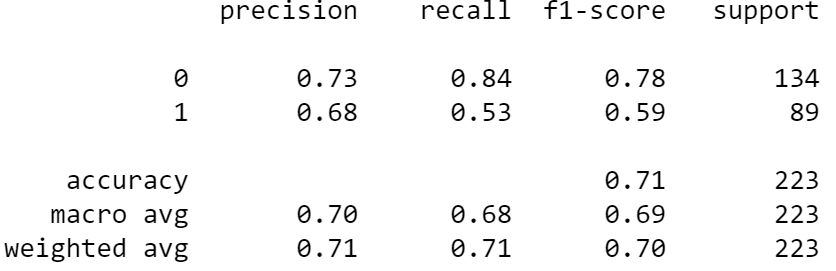
It’s a good result, but let’s see if we can improve the result after we clean the label. Let’s try to do that with the following code.
from cleanlab.classification import CleanLearning
#initiate model with CleanLearning
cl = CleanLearning(model, seed=42)
# Fit model
cl.fit(X_train, y_train)
# Examine the label quality
cl.get_label_issues()
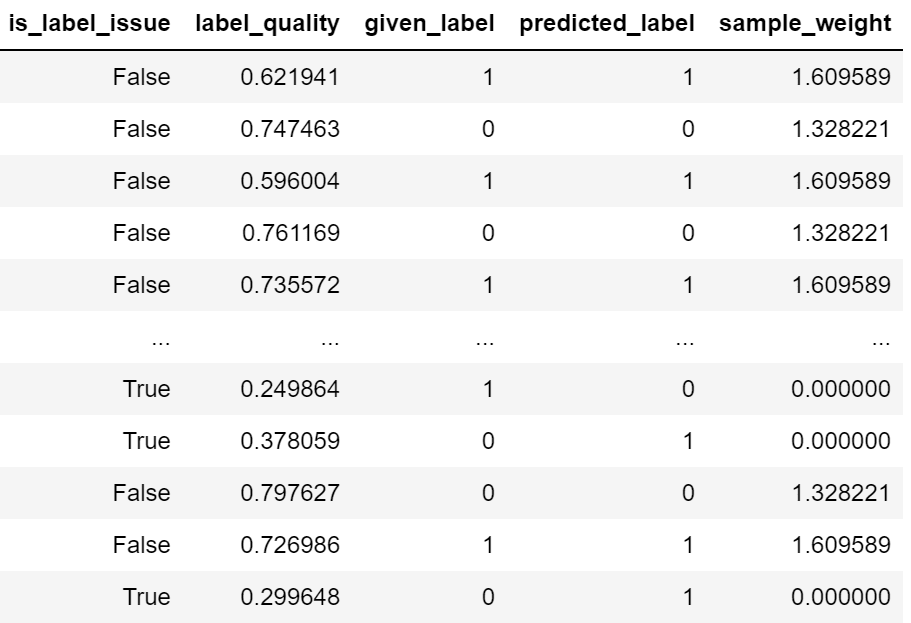
We can see from the above result that some labels have issues because of misprediction. By cleaning the label, let’s see how the model metrics result.
clean_preds = cl.predict(X_test)
print(classification_report(y_test, clean_preds))
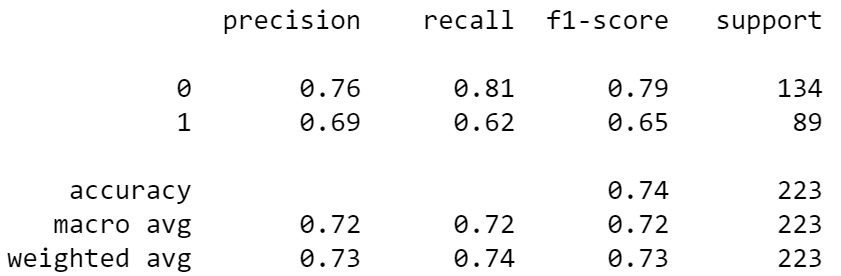
We can see there is an improvement in the results compared to our previous model without label cleaning. You could still do many things with Cleanlab; I suggest you visit the documentation to learn further.
Conclusion
Data cleaning is a must-step for any data analysis process. Still, it often takes a lot of time to clean everything properly. Luckily, there are Python packages developed to help us clean the data properly. In this article, I present three packages to help clean the data: PyJanitor, Feature-Engine, and Cleanlab.
Cornellius Yudha Wijaya is a data science assistant manager and data writer. While working full-time at Allianz Indonesia, he loves to share Python and Data tips via social media and writing media.