
Image by freepik.com
In real-world data science projects, the data used for analysis may contain several imperfections such as the presence of missing data, redundant data, data entries having incorrect format, presence of outliers in the data, etc. Data cleaning refers to the process of preprocessing and transforming raw data to render it in a form that is suitable for further analysis such as for descriptive analysis (data visualization) or prescriptive analysis (model building). Clean, accurate, and reliable data must be utilized for post analysis because “bad data leads to bad predictive models”.
Several libraries in Python, including pandas and numpy, can be used for data cleaning and transformation. These libraries offer a wide range of methods and functions to carry out tasks including dealing with missing values, eliminating outliers, and translating data into a model-friendly format. Additionally, eliminating redundant features or combining groups of highly correlated features into a single feature could lead to dimensionality reduction. Training a model using a dataset with fewer features will improve the computational efficiency of the model. Furthermore, a model built using a dataset having fewer features is easier to interpret and has better predictive power.
In this article, we will explore various tools and techniques that are available in Python for cleaning, processing, and transforming data. We will demonstrate data cleaning techniques using the data.cvs dataset shown below:
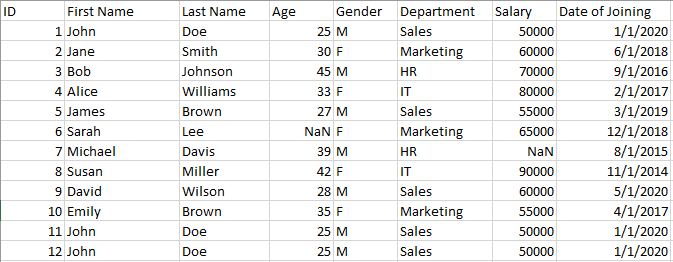
data.csv showing various imperfections such as duplicated data, NaN, etc. Data created by Author.
Libraries For Data Cleaning in Python
In Python, a range of libraries and tools, including pandas and NumPy, may be used to clean up data. For instance, the dropna(), drop duplicates(), and fillna() functions in pandas may be used to manage missing data, remove missing data, and remove duplicate rows, respectively. The scikit-learn toolkit offers tools for dealing with outliers (such as the SimpleImputer class) and transforming data into a format that can be utilized by a model, such as the StandardScaler class for standardizing normalizing numerical data, and the MinMaxScalar for normalizing data.
In this article, we will explore various data cleaning techniques that can be used in Python to prepare and preprocess data for use in a machine learning model.
Processing Missing Data
The processing of missing data is one of the most important imperfections in a dataset. Several methods for dealing with missing data are provided by the pandas package in Python, including dropna() and fillna(). The dropna() method is used to eliminate any columns or rows that have missing values. For instance, the code below will eliminate all rows with at least one missing value:
import pandas as pd
data = pd.read_csv('data.csv')
data = data.dropna()
The fillna() function can be used to fill in missing values with a specific value or method. For example, the following code will fill in missing values in the 'age' column with the mean age of the data:
import pandas as pd
data = pd.read_csv('data.csv')
data['age'].fillna(data['age'].mean(), inplace=True)
Handling Outliers
Handling outliers is a typical data cleaning activity. Values that diverge greatly from the rest of the data are considered outliers. These factors should be managed carefully since they have a significant influence on a model's performance. The RobustScaler class from the scikit-learn toolkit in Python is used to handle outliers. By deleting the median and scaling the data according to the interquartile range, this class may be used to scale the data.
from sklearn.preprocessing import RobustScaler
data = pd.read_csv('data.csv')
scaler = RobustScaler()
data = scaler.fit_transform(data)
Encoding Categorical Variables
Another common data cleaning task is converting data into a format that can be used by a model. For instance, before categorical data can be employed in a model, it must be transformed into numerical data. The get_dummies() method in the pandas package allows one to transform category data into numerical data. In the example below, the categorical feature ‘Department’ is transformed into numerical data:
import pandas as pd
data = pd.read_csv('data.csv')
data = pd.get_dummies(data, columns=['Department'])
Removing Duplicate Data
Duplicate data must also be eliminated during the data cleaning process. To delete duplicate rows from a Python DataFrame, the drop_duplicates() method provided by the pandas package can be used. For instance, the code below will eliminate any redundant rows from the data:
import pandas as pd
data = pd.read_csv('data.csv')
data = data.drop_duplicates()
Feature Engineering
Feature selection and feature engineering are essential components of data cleaning. The process of choosing only the relevant features in a dataset is referred to as feature selection, whereas the process of building new features from already existing ones is known as feature engineering. The code below is an illustration of feature engineering:
import pandas as pd
from sklearn.preprocessing import StandardScaler
# read the data into a pandas dataframe
df = pd.read_excel("data.csv")
# create a feature matrix and target vector
X = df.drop(["Employee ID", "Date of Joining"], axis=1)
y = df["Salary"]
# scale the numerical features
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X[["Age", "Experience"]])
# concatenate the scaled features with the categorical features
gender_dummies = pd.get_dummies(X["Gender"], prefix="Gender")
X_processed = pd.concat(
[gender_dummies, pd.DataFrame(X_scaled, columns=["Age", "Experience"])],
axis=1,
)
print(X_processed)
In the above code, we first create a feature matrix (X) by dropping the 'Employee ID' and 'Date of Joining' columns, and create a target vector (y) consisting of the 'Salary' column. We then scale the numerical features 'Age' and 'Experience' using the StandardScaler() function from scikit-learn.
Next, we create dummy variables for the categorical 'Gender' column and concatenate them with the scaled numerical features to create the final processed feature matrix (X_processed).
Note that the specific feature extraction techniques used will depend on the data and the specific requirements of the analysis. Also, it's important to split the data into training and testing sets before applying any machine learning models to avoid overfitting.
Conclusion
To conclude, data cleaning is an essential stage in the machine learning process since it guarantees the data used for analysis (descriptive or prescriptive) is of high quality. Important methods that may be used to prepare and preprocess data include converting data format, removing duplicate data, dealing with missing data, outlier detection, feature engineering, and feature selection. Pandas, NumPy, and scikit-learn are just a few of the many libraries and tools for feature engineering and data cleaning.
Benjamin O. Tayo is a Physicist, Data Science Educator, and Writer, as well as the Owner of DataScienceHub. Previously, Benjamin was teaching Engineering and Physics at U. of Central Oklahoma, Grand Canyon U., and Pittsburgh State U.